kafka基本原理概述——patition与replication分配
kafka一直在大数据中承受着数据的压力也扮演着对数据维护转换的角色,下面重点介绍kafka大致组成及其partition副本的分配原则:
文章参考:http://www.linkedkeeper.com/detail/blog.action?bid=1016
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka主要设计目标如下:
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条(也就是100000条——十万)消息的传输。
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
同时支持离线数据处理和实时数据处理。
Kafka专用术语:
Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
Topic:一类消息,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
Segment:partition物理上由多个segment组成。
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息
topic & partition
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
这里也就是broker——>topic——>partition——>segment
segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件。

segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
segment中index与data file对应关系物理结构如下:

索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message),以及该消息的物理偏移地址为497。
副本(replication)策略
1.数据同步
kafka 0.8后提供了Replication机制来保证Broker的failover。
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
2.副本放置策略
Kafka分配Replica的算法如下(注意!!! 下面的broker、partition副本数这些编号都是从0开始编号的):
将所有存活的N个Brokers和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本( 这里就基本说明了一个topic的partition在集群上的大致分布情况 )
将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
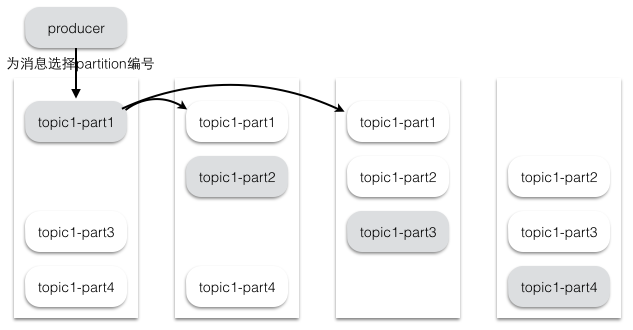
对于Kafka而言,定义一个Broker是否“活着”包含两个条件:
一是它必须维护与ZooKeeper的session(这个通过ZooKeeper的Heartbeat机制来实现)。
二是Follower必须能够及时将Leader的消息复制过来,不能“落后太多”。
重点在于kafka中partition的副本放置算法,同时间接说明了一个topic的partition在集群中的分配情况...
kafka基本原理概述——patition与replication分配的更多相关文章
- Kafka基本原理概述
Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ngi ...
- Kafka 基本原理
Kafka 基本原理 来源:阿凡卢 , www.cnblogs.com/luxiaoxun/p/5492646.html 简介 Apache Kafka是分布式发布-订阅消息系统.它最初由Link ...
- Docker基本原理概述
Docker基本原理概述 Docker是一个用于开发,交付和运行应用程序的开放平台.Docker能够将应用程序与基础架构分开,从而可以快速交付软件.借助Docker,可以以与管理应用程序相同的方式来管 ...
- Kafka之概述
Kafka之概述 一.消息队列内部实现原理 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消 ...
- Kafka(2)--kafka基本原理之消息的分发与接收
关于 Topic 和 Partition Topic 在 kafka 中,topic 是一个存储消息的逻辑概念,可以认为是一个消息集合.每条消息发送到 kafka 集群的消息都有一个类别.物理上来说, ...
- NAT64与DNS64基本原理概述
NAT64与DNS64基本原理概述 1.NAT64与DNS64背景 在IPv6网络的发展过程中,面临最大的问题应该是IPv6与IPv4的不兼容性,因此无法实现二种不兼容网络之间的互访.为了实现 ...
- Kafka基本原理
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- kafka基本原理学习
下载安装地址:http://kafka.apache.org/downloads.html 原文链接:http://www.jasongj.com/2015/01/02/Kafka深度解析 Kafk ...
- Kafka(1)-概述
一. 内部原理 1. 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端.这个模型的特 ...
随机推荐
- java-Excel导出中的坑
在Excel导出过程中,若遇到合并单元格样式只有第一行合并,而下面要合并的行没有边框显示. 一般问题出在将单元格样式设置与合并单元格放在同一个循环中导致. 以下为一个完整版的demo以供参考 定义边框 ...
- HTTP/FTP压力测试工具siege
HTTP/FTP压力测试工具siege 压力测试可以检测服务器的承载能力.针对HTTP和FTP服务,Kali Linux提供专项工具siege.该工具可以模拟多个用户同时访问同一个网站的多个网页, ...
- centos+uwsgi+nginx+python+django服务器安装配置
1.ssh登录后使用fdisk –l查看需要格式化硬盘的名称: 2.运行fdisk /dev/vdb,对数据盘进行分区,按照提示,依次输入n,p,1,两次回车,wq,分区开始.(注意数据盘的名称,和阿 ...
- Codeforces.809E.Surprise me!(莫比乌斯反演 虚树)
题目链接 \(Description\) 给定一棵树,求\[\frac{1}{n(n-1)/2}\times\sum_{i\in[1,n],j\in[1,n],i\neq j}\varphi(a_i\ ...
- oracle复杂查询是sql
一.over()分析函数 分组查前几条:select * from test t where (select count(*) from test a where t.type=a.type and ...
- CDOJ 42/BZOJ 2753 滑雪与时间胶囊 kruskal
2753: [SCOI2012]滑雪与时间胶囊 Time Limit: 50 Sec Memory Limit: 128 MBSubmit: 1376 Solved: 487[Submit][St ...
- php-curl小记
用jQuery: $.ajax({ url:url, type:"POST", data:data, contentType:"application/json; cha ...
- 华为S5300系列升级固件S5300SI-V100R003C00SPC301.cc
这个固件是升级V100R005的中间件,所以是必经的,注意,这个固件带有http的服务,但现在无论官网还是外面,几乎找不到这个固件的web功能,如果非要实现,可以拿V100R005的web文件改名为w ...
- HDU 2686 Matrix(最大费用流)
Matrix Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- 【转载】C#堆和栈的区别
原文出处 理解堆与栈对于理解.NET中的内存管理.垃圾回收.错误和异常.调试与日志有很大的帮助.垃圾回收的机制使程序员从复杂的内存管理中解脱出来,虽然绝大多数的C#程序并不需要程序员手动管理内存,但这 ...