Python实现熵值法确定权重
本文从以下四个方面,介绍用Python实现熵值法确定权重:
一. 熵值法介绍
二. 熵值法实现
三. Python实现熵值法示例1
四. Python实现熵值法示例2
一. 熵值法介绍
熵值法是计算指标权重的经典算法之一,它是指用来判断某个指标的离散程度的数学方法。离散程度越大,即信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性越大,熵也越大。根据熵的特性,我们可以通过计算熵值来判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大。
二. 熵值法实现
1.假设数据有n行记录,m个变量,数据可以用一个n*m的矩阵A表示(n行m列,即n行记录数,m个特征列)
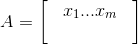
2.数据的归一化处理
xij表示矩阵A的第i行j列元素。
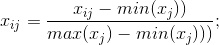
3.计算第j项指标下第i个记录所占比重
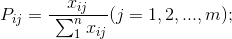
4.计算第j项指标的熵值
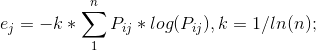
5.计算第j项指标的差异系数

6.计算第j项指标的权重
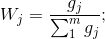
三. Python实现熵值法示例1
样例数据1
.csv格式数据内容
var1,var2,var3,var4,var5,var6
171.33,151.33,0.28,0,106.36,0.05
646.66,370,1.07,61,1686.79,1.64
533.33,189.66,0.59,0,242.31,0.57
28.33,0,0.17,0,137.85,2.29
620,234,0.88,41.33,428.33,0.13
192.33,177.66,0.16,0,128.68,1.07
111,94,0.18,0,234.27,0.22
291,654,1.21,65.66,2.26,0
421.33,247,0.7,0,0.4,0
193,288.66,0.16,0,0,0
82.33,118,0.11,0,758.41,0.24
649.66,648.66,0.54,0,13.35,0.11
37.66,103.33,0.12,0,1133.51,1.1
183.33,282.33,0.55,0,624.73,1.04
1014.66,1264.66,5.07,814.66,0,0
90.66,134,0.3,0,0.15,0
200.66,98.33,0.33,0,681.54,0.51
540.66,558.66,1.08,62,2.71,0.09
80,60.66,0.13,0,910.19,0.88
530.66,281.33,0.88,36,743.21,0.72
166,133,0.13,0,246.88,2.05
377.66,310.33,0.57,0,102.89,0.57
143.33,73,0.23,0,103.94,0.1
394.66,473.66,0.56,0,1.06,0.03
535.66,447.33,0.44,0,10.59,0.08
52.66,56.66,0.52,0,0,0
1381.66,760.66,2.3,781.66,248.71,0.13
44.33,42.33,0.07,0,0.66,0
71.66,62.66,0.11,0,535.26,0.52
148.33,56.66,0.24,0,173.83,0.16
Python代码:
#!/usr/bin/python
# -*- coding: utf-8 -*- """
Created on Fri Mar 23 10:48:36 2018
@author: Big Teacher Brother
"""
import pandas as pd
import numpy as np
import math
from numpy import array # 1读取数据
df = pd.read_csv('E:\\text.csv', encoding='gb2312')
# 2数据预处理 ,去除空值的记录
df.dropna() #定义熵值法函数
def cal_weight(x):
'''熵值法计算变量的权重'''
# 标准化
x = x.apply(lambda x: ((x - np.min(x)) / (np.max(x) - np.min(x)))) # 求k
rows = x.index.size # 行
cols = x.columns.size # 列
k = 1.0 / math.log(rows) lnf = [[None] * cols for i in range(rows)] # 矩阵计算--
# 信息熵
# p=array(p)
x = array(x)
lnf = [[None] * cols for i in range(rows)]
lnf = array(lnf)
for i in range(0, rows):
for j in range(0, cols):
if x[i][j] == 0:
lnfij = 0.0
else:
p = x[i][j] / x.sum(axis=0)[j]
lnfij = math.log(p) * p * (-k)
lnf[i][j] = lnfij
lnf = pd.DataFrame(lnf)
E = lnf # 计算冗余度
d = 1 - E.sum(axis=0)
# 计算各指标的权重
w = [[None] * 1 for i in range(cols)]
for j in range(0, cols):
wj = d[j] / sum(d)
w[j] = wj
# 计算各样本的综合得分,用最原始的数据 w = pd.DataFrame(w)
return w if __name__ == '__main__':
# 计算df各字段的权重
w = cal_weight(df) # 调用cal_weight
w.index = df.columns
w.columns = ['weight']
print(w)
print('运行完成!')
运行的结果:
Running D:/tensorflow/ImageNet/shangzhifa.py
Backend Qt5Agg is interactive backend. Turning interactive mode on.
weight
var1 0.088485
var2 0.074840
var3 0.140206
var4 0.410843
var5 0.144374
var6 0.141251
运行完成!
四. Python实现熵值法示例2
样例数据:
将数据保存到Excel表格中,并用xlrd读取。
Python代码:
import numpy as np
import xlrd #读数据并求熵
path=u'K:\\选指标的.xlsx'
hn,nc=1,1
#hn为表头行数,nc为表头列数
sheetname=u'Sheet3'
def readexcel(hn,nc):
data = xlrd.open_workbook(path)
table = data.sheet_by_name(sheetname)
nrows = table.nrows
data=[]
for i in range(hn,nrows):
data.append(table.row_values(i)[nc:])
return np.array(data)
def entropy(data0):
#返回每个样本的指数
#样本数,指标个数
n,m=np.shape(data0)
#一行一个样本,一列一个指标
#下面是归一化
maxium=np.max(data0,axis=0)
minium=np.min(data0,axis=0)
data= (data0-minium)*1.0/(maxium-minium)
##计算第j项指标,第i个样本占该指标的比重
sumzb=np.sum(data,axis=0)
data=data/sumzb
#对ln0处理
a=data*1.0
a[np.where(data==0)]=0.0001
# #计算每个指标的熵
e=(-1.0/np.log(n))*np.sum(data*np.log(a),axis=0)
# #计算权重
w=(1-e)/np.sum(1-e)
recodes=np.sum(data0*w,axis=1)
return recodes
data=readexcel(hn,nc)
grades=entropy(data)
计算结果为:
In[32]:grades
Out[32]:
array([95.7069621 , 93.14062354, 93.17273781, 92.77037549, 95.84064938,
98.01005572, 90.20508545, 95.17203466, 95.96929203, 97.80841298,
97.021269 ])
上面的程序计算得分时用了标准化前的值×权重,这对于原始评分量纲相同时没有什么问题。
按照论文上的公式,计算得分时应该用标准化后的值×权重,这对于原始数据量纲不同时应该这样做,因此按照论文的公式计算的程序如下:
Python代码为:
import numpy as np
import xlrd #读数据并求熵
path=u'K:\\选指标的.xlsx'
hn,nc=1,1
#hn为表头行数,nc为表头列数
sheetname=u'Sheet3'
def readexcel(hn,nc):
data = xlrd.open_workbook(path)
table = data.sheet_by_name(sheetname)
nrows = table.nrows
data=[]
for i in range(hn,nrows):
data.append(table.row_values(i)[nc:])
return np.array(data)
def entropy(data0):
#返回每个样本的指数
#样本数,指标个数
n,m=np.shape(data0)
#一行一个样本,一列一个指标
#下面是归一化
maxium=np.max(data0,axis=0)
minium=np.min(data0,axis=0)
data= (data0-minium)*1.0/(maxium-minium)
##计算第j项指标,第i个样本占该指标的比重
sumzb=np.sum(data,axis=0)
data=data/sumzb
#对ln0处理
a=data*1.0
a[np.where(data==0)]=0.0001
# #计算每个指标的熵
e=(-1.0/np.log(n))*np.sum(data*np.log(a),axis=0)
# #计算权重
w=(1-e)/np.sum(1-e)
recodes=np.sum(data*w,axis=1)
return recodes
data=readexcel(hn,nc)
grades=entropy(data)
结果如下:
In[34]:grades
Out[34]:
array([0.08767219, 0.07639727, 0.08342572, 0.07555273, 0.08920511,
0.11506703, 0.06970125, 0.09550656, 0.09852824, 0.10232353,
0.10662037])
参考文章:
https://blog.csdn.net/qq_24975309/article/details/82026022
https://blog.csdn.net/weixin_40450867/article/details/81226705
https://blog.csdn.net/weixin_41503009/article/details/82285422
https://blog.csdn.net/wangh0802/article/details/53981356
https://www.jianshu.com/p/3e08e6f6e244
https://blog.csdn.net/yang978897961/article/details/79164829/
https://blog.csdn.net/Yellow_python/article/details/83002698
Python实现熵值法确定权重的更多相关文章
- 熵值法 [异质指标同质化]中-Matlab 数据归一化预处理 mapminmax函数
一.mapminmax Process matrices by mapping row minimum and maximum values to [-1 1] 意思是将矩阵的每一行处理成[-1,1] ...
- 熵权法原理及matlab代码实现
参考原理博客地址https://blog.csdn.net/u013713294/article/details/53407087 一.基本原理 在信息论中,熵是对不确定性的一种度量.信息量越大,不确 ...
- 吴裕雄 python 熵权法确定特征权重
一.熵权法介绍 熵最先由申农引入信息论,目前已经在工程技术.社会经济等领域得到了非常广泛的应用. 熵权法的基本思路是根据各个特征和它对应的值的变异性的大小来确定客观权重. 一般来说,若某个特征的信息熵 ...
- python 图像处理中二值化方法归纳总结
python图像处理二值化方法 1. opencv 简单阈值 cv2.threshold 2. opencv 自适应阈值 cv2.adaptiveThreshold 3. Otsu's 二值化 例子: ...
- 基于topsis和熵权法
% % X 数据矩阵 % % n 数据矩阵行数即评价对象数目 % % m 数据矩阵列数即经济指标数目 % % B 乘以熵权的数据矩阵 % % Dist_max D+ 与最大值的距离向量 % % Dis ...
- 熵权法(the Entropy Weight Method)以及MATLAB实现
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量:如果指标的信息熵越小,该指标提供的信息量越小,在综合评价中所起作用理当越小,权重就应该越低.因此,可利用信息熵这个工 ...
- Python字典按值排序的方法
Python字典按值排序的方法: 法1: (默认升序排序,加 reverse = True 指定为降序排序) # sorted的结果是一个list dic1SortList = sorted( di ...
- 利用Python计算π的值,并显示进度条
利用Python计算π的值,并显示进度条 第一步:下载tqdm 第二步;编写代码 from math import * from tqdm import tqdm from time import ...
- MATLAB插 值 法
MATLAB插 值 法 作者:凯鲁嘎吉 - 博客园http://www.cnblogs.com/kailugaji/ 一.实验目的 二.实验原理 三.实验程序 四.实验内容 五.解答 1. 程序 ...
随机推荐
- [折半搜索][哈希]POJ1186方程的解数
题目传送门 这道题明显N数据范围非常小,但是M很大,所以用折半搜索实现搜索算法的指数级优化,将复杂度优化到O(M^(N/2)). 将搜出的两半结果用哈希的方式合并(乘法原理). Code: #incl ...
- 【转载】COM 组件设计与应用(一)——起源及复合文件
原文:http://vckbase.com/index.php/wv/1201.html COM 组件设计与应用 系列文章:http://vckbase.com/index.php/piwz?& ...
- CF 1138 E. Museums Tour
E. Museums Tour 链接 分析: 按时间建出分层图,每个点形如(u,t),表示u在在t个时刻的点,tarjan缩点.每个强连通分量中的点都能经过,然后DAG上dp. 代码: #includ ...
- avascript小技巧
avascript小技巧 事件源对象 event.srcElement.tagName event.srcElement.type 捕获释放 event.srcElement.setCapture() ...
- String.valueOf(object).trim())
获得对象的字段的值,然后转成string类型,并且去掉前后空白~~ToString()是转化为字符串的方法 Trim()是去两边空格的方法把StringBuffer转换成String类型时 没有用.t ...
- L2-016 愿天下有情人都是失散多年的兄妹
L2-016 愿天下有情人都是失散多年的兄妹 (25 分) 呵呵.大家都知道五服以内不得通婚,即两个人最近的共同祖先如果在五代以内(即本人.父母.祖父母.曾祖父母.高祖父母)则不可通婚.本题就请你 ...
- centos7 上安装mysql5.7后登录报错ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: Yes 或者No)
原文转载自以下链接:https://blog.csdn.net/keepd/article/details/77151006 安装完mysql后会有个临时密码去日志查看,但是查看登录修改密后还是不行 ...
- JavaScript学习笔记(六)—— 异步编码
第七章 异步编码 1 事件处理程序 处理程序:即网页加载完毕后将执行的代码,称回调函数或监听器: 包含:处理函数+window.onload=函数名; <script language=&qu ...
- k8s环境搭建--基于kubeadm方法
环境 master node: 数量 1, 系统 ubuntu 16.04_amd64 worker node: 数量 1, 系统 ubuntu 16.04_amd64 kubernetes 版本: ...
- Linux 文件搜索命令:find、which、whereis 和 locate
Linux 提供了许多用于文件搜索的命令,这些命令都很强大,但是也有一些不同之处,这里分别介绍一下. 一.find 命令 find 是最常见和最强大的一个文件搜索命令.使用 find 命令可以在指定目 ...