吴裕雄 python 熵权法确定特征权重
一、熵权法介绍
熵最先由申农引入信息论,目前已经在工程技术、社会经济等领域得到了非常广泛的应用。
熵权法的基本思路是根据各个特征和它对应的值的变异性的大小来确定客观权重。
一般来说,若某个特征的信息熵越小,表明该特征的值得变异(对整体的影响)程度越大,提供的信息量越多,在综合评价中所能起到
的作用也越大,其权重也就越大。相反,某个特征的信息熵越大,表明指标值得变异(对整体的影响)程度越小,提供的信息量也越少,
在综合评价中所起到的作用也越小,其权重也就越小。
二、熵权法赋权步骤
1. 数据标准化(数据归一化)
将各个指标的数据进行标准化(归一化)处理。
假设给定了k个特征,其中
(每个特征的值表示)。假设对各特征数据(值)标准化后的值为
,那么
。
i 表示特征序列,j 表示 i 特征序列对应的各个具体的值的序列,所谓的序列就是起到标号的作用,方便人们理解公式的运行过程。
2. 求各指标的信息熵
根据信息论中信息熵的定义,一组数据的信息熵。其中
,如果
,则定义
。
3. 确定各指标权重
根据信息熵的计算公式,计算出各个特征的信息熵为 。通过信息熵计算各指标的权重:
。
4. 对各个特征进行评分
根据计算出的指标权重,设Zl为第l个特征的最终得分,则 ,
import xlrd
import numpy as np #读数据并求熵
path=u"D:\\LearningResource\\myLearningData\\hostital.xls"
hn,nc=1,1
#hn为表头行数,nc为表头列数
sheetname=u'Sheet1' def readexcel(hn,nc):
data = xlrd.open_workbook(path)
table = data.sheet_by_name(sheetname)
nrows = table.nrows
data=[]
for i in range(hn,nrows):
data.append(table.row_values(i)[nc:])
return np.array(data) def entropy(data0):
#返回每个样本的指数
#样本数,指标个数
n,m=np.shape(data0)
#一行一个样本,一列一个指标
#下面是归一化
maxium=np.max(data0,axis=0)
minium=np.min(data0,axis=0)
data= (data0-minium)*1.0/(maxium-minium)
##计算第j项指标,第i个样本占该指标的比重
sumzb=np.sum(data,axis=0)
data=data/sumzb
#对ln0处理
a=data*1.0
a[np.where(data==0)]=0.0001
# #计算每个指标的熵
e=(-1.0/np.log(n))*np.sum(data*np.log(a),axis=0)
print(e)
# #计算权重
w=(1-e)/np.sum(1-e)
recodes=np.sum(data0*w,axis=1)
return recodes data=readexcel(hn,nc)
grades=entropy(data)
print(grades)

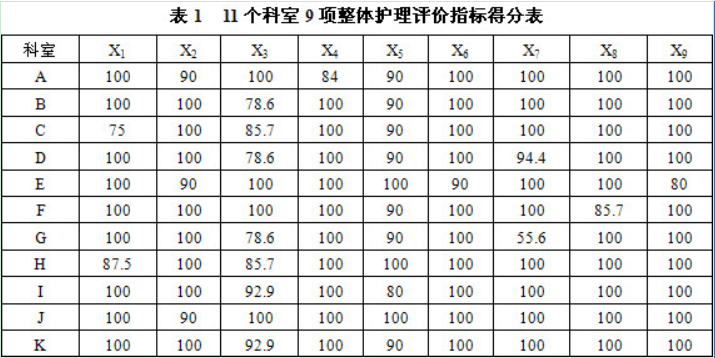
原数据集
吴裕雄 python 熵权法确定特征权重的更多相关文章
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理包裹式特征选取模型
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_select ...
- 基于topsis和熵权法
% % X 数据矩阵 % % n 数据矩阵行数即评价对象数目 % % m 数据矩阵列数即经济指标数目 % % B 乘以熵权的数据矩阵 % % Dist_max D+ 与最大值的距离向量 % % Dis ...
- 熵权法(the Entropy Weight Method)以及MATLAB实现
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量:如果指标的信息熵越小,该指标提供的信息量越小,在综合评价中所起作用理当越小,权重就应该越低.因此,可利用信息熵这个工 ...
- 熵权法原理及matlab代码实现
参考原理博客地址https://blog.csdn.net/u013713294/article/details/53407087 一.基本原理 在信息论中,熵是对不确定性的一种度量.信息量越大,不确 ...
- 吴裕雄 python深度学习与实践(17)
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import time # 声明输 ...
- 吴裕雄 python神经网络 水果图片识别(4)
# coding: utf-8 # In[1]:import osimport numpy as npfrom skimage import color, data, transform, io # ...
- 吴裕雄 python神经网络 水果图片识别(2)
import osimport numpy as npimport matplotlib.pyplot as pltfrom skimage import color,data,transform,i ...
随机推荐
- Error running app: Default Activity not found ; 安卓程序运行不了,也不报错。
我最近copy一个工程,写完了去运行时不能运行,项目不报错,就是运行的地方有个叉号:尝试很多办法后准备重新New一个时发现:"10:17 Error running app: Default ...
- SQL SERVER 数据压缩
从SQL SERVER 2008开始,SQL SERVER 提供了对数据进行压缩的功能,启用数据压缩无须修改应用程序. 数据压缩可有效减少数据的占用空间,读取和写入相同数据花费的IO也响应减少,从而可 ...
- 当别人给你一个wsdl或者webservice接口时
一 通过wsdl生成客户端 引用于http://www.cnblogs.com/yisheng163/p/4524808.html 参照http://www.cnblogs.com/xdp-gacl ...
- asp.net 基础内容
1. ViewData ViewBag TempData 区别? 1.ViewData和TempData是字典类型,赋值方式用字典方式,ViewData["myName"] 2. ...
- jquery 弹框,确定、取消
function del(id, url) { var bool = confirm("确定删除?") if (bool) { //点击确定后操作 var Urls = " ...
- 下雨天,适合学「Spring Boot」
北方的闷热,让不少小伙伴盼着下雨,前几天北京下了场大雨,杭州也紧跟这下了场雨,就在昨天原本还很闷热的天,突然就飘泼大雨了.今天也断断续续的下着小雨,一觉醒来已经是10点了.有句话说:懒惰是人的天性 ...
- ORACLE ROWNUM解析[转]
一.对rownum的说明 关于Oracle 的 rownum 问题,很多资料都说不支持SQL语句中的“>.>=.=.between...and”运算符,只能用如下运算符号“<.< ...
- python入门-使用API
python入门-使用API import requests #执行API调用并存储响应 url = 'https://api.github.com/search/repositories?q=lan ...
- 10.纯 CSS 创作一个同心圆弧旋转 loader 特效
原文地址:https://segmentfault.com/a/1190000014682999 想到了扇形:正方形 ->border-radius: 50%; ->取四份中的任意一份. ...
- cmd批处理命令及powershell
https://blog.csdn.net/wenzhongxiang/article/details/79256937 Powershell查询IP地址及主机名信息:1.foreach($ipv4 ...