Pytorch CNN网络MNIST数字识别 [超详细记录] 学习笔记(三)
1. 准备数据集
1.1 MNIST数据集获取:
torchvision.datasets接口直接下载,该接口可以直接构建数据集,推荐
其他途径下载后,编写程序进行读取,然后由Datasets构建自己的数据集
本文使用第一种方法获取数据集,并使用Dataloader进行按批装载。如果使用程序下载失败,请将其他途径下载的MNIST数据集 [文件] 和 [解压文件] 放置在 <data/MNIST/raw/> 位置下,本文的程序及文件结构图如下:
其中,model文件夹用来存储每个epoch训练的模型参数,根文件夹下包含model.py用于训练模型,test.py为测试集测试,show.py为展示部分
1.2 程序部分
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import time
# 1. 准备数据集
## 1.1 使用torchvision自动下载MNIST数据集
train_data = datasets.MNIST(root='data\\',
train=True,
transform=transforms.ToTensor(),
download=True)
## 1.2 构建数据集装载器
train_loader = DataLoader(dataset=train_data,
batch_size=100,
shuffle=True,
drop_last=False,
num_workers=4)
if __name__ == "__main__":
print("===============数据统计===============")
print("训练集样本:",train_data.__len__(), train_data.data.shape)

【代码解析】
root为存放MNIST的路径,trian=True代表下载的为训练集和训练集标签,False则代表测试集和标签
transforms.ToTensor()表示将shape为(H, W, C)的 numpy 数组或 img 转为shape为(C, H, W)的tensor,并将数值归一化为[0,1]
download为True则代表自动下载,若该文件夹下已经下载,则直接跳过下载步骤
shuffle=True,表示对分好的batch进行洗牌操作,drop_last=True表示对最后不足batch大小的剩余样本舍去,False表示保留
num_works表示每次读取的进程数,和核心数有关
Dataset和Dataloader详细说明,请移步:[Pytorch Dataset和Dataloader 学习笔记(二)]
2. 设计网络结构
2.1 网络设计
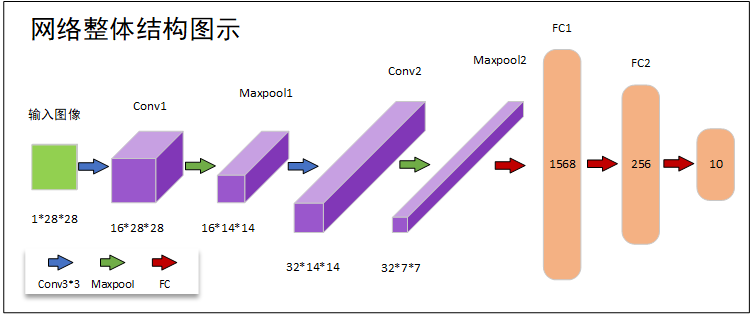
网络结构如上图所示,输入图像—>卷积1—>池化1—>卷积2—>池化2—>全连接1—>全连接2—>softmax,每次卷积通道数都增加一倍,最后送入全连接层实现分类
2.2 程序部分
# 2. Design model using class
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv_layer1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.max_pooling1 = nn.MaxPool2d(2)
self.conv_layer2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.max_pooling2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(1568, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.max_pooling1(F.relu(self.conv_layer1(x)))
x = self.max_pooling2(F.relu(self.conv_layer2(x)))
x = x.view(-1, 32*7*7)
x = F.relu(self.fc1(x))
y_hat = self.fc2(x) # CrossEntropyLoss会自动激活最后一层的输出以及softmax处理
return y_hat
net = Net()
# 3. Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
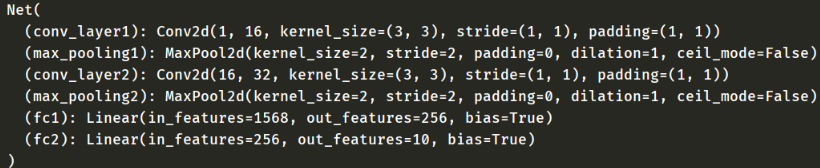
【代码解析】
fc1的1568维度是因为最后一次池化后的shape为32*7*7=1568
在最后一层,并没有进行relu激活以及接入softmax,是因为,在CrossEntropyLoss中会自动激活最后一层的输出以及softmax处理
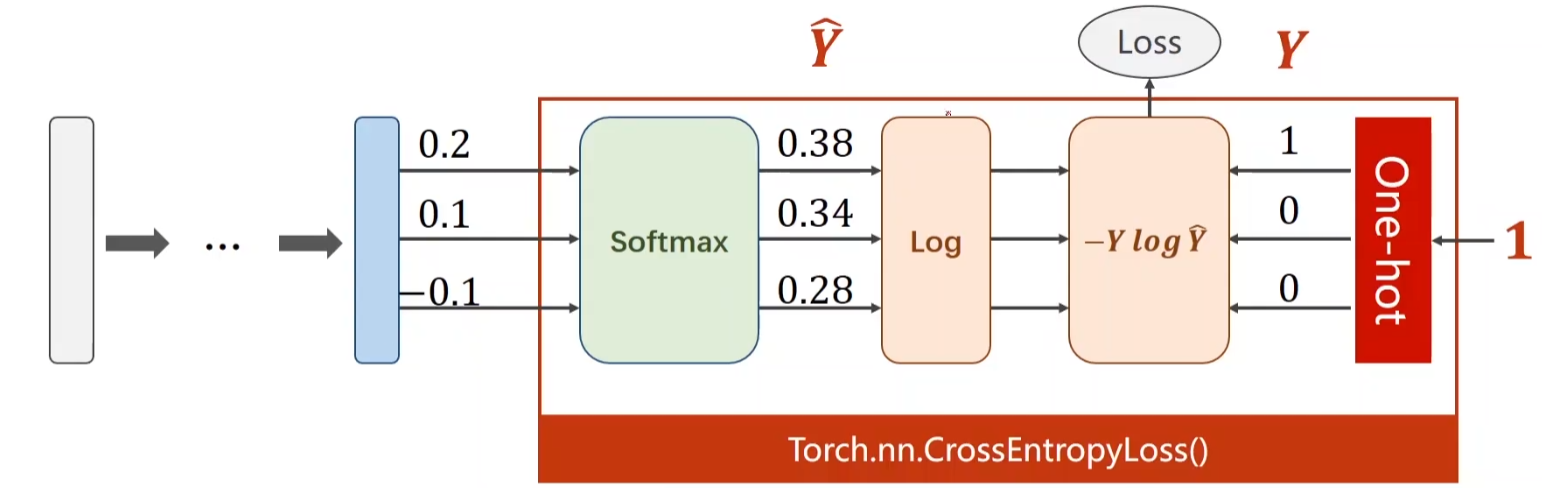
CrossEntropyLoss图参考:《PyTorch深度学习实践》完结合集
详细网络结构搭建说明,请移步:Pytorch线性规划模型 学习笔记(一)
3. 迭代训练
# 3. Construct loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
# 4. Training
if __name__ == "__main__":
print("Training...")
for epoch in range(20):
strat = time.time()
total_correct = 0
for x, y in train_loader:
y_hat = net(x)
y_pre = torch.argmax(y_hat, dim=1)
total_correct += sum(torch.eq(y_pre, y)) # 统计当前epoch下的正确个数
loss = criterion(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (float(total_correct) / train_data.__len__())*100
save_path = "model/net" + str(epoch+1) + ".pth"
torch.save(obj=net.state_dict(), f=save_path)
print("epoch:", str(epoch + 1) + "/20",
" \n time:", "%.1f" % (time.time() - strat) + "s"
" train_loss:", loss.item(),
" acc:%.3f%%" % acc,)
print("we are done!")

【代码解析】
- total_correct变量用于统计每个epoch下正确预测值的个数,每进行epoch进行一次清零
- torch.argmax(y_hat, dim=1)用于选取y_hat下每一行的最大值(每个样本的最高得分),并返回与y相同维度的tensor
- torch.eq(y_pre, y)用于比较两个矩阵元素是否相同,相同则返回True,不同则返回False,用于判断预测值与真实值是否相同
- torch.save保存了每个epoch的网络权重参数
4. 测试集预测部分
# 测试模型,测试集为test_data
import torch
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from model import Net
test_data = datasets.MNIST(root='data\\',
train=False,
transform=transforms.ToTensor(),
download=True)
test_loader = DataLoader(dataset=test_data,
batch_size=100,
shuffle=True,
drop_last=False,
num_workers=4)
if __name__ == "__main__":
print("---------------预测分析---------------")
print("测试集样本:", test_data.__len__(), test_data.data.shape)
model = Net()
model.load_state_dict(torch.load("model/net20.pth"))
model.eval()
total_correct = 0
for x, y in test_loader:
y_hat = model(x)
y_pre = torch.argmax(y_hat, dim=1)
total_correct += sum(torch.eq(y_pre, y))
acc = (float(total_correct) / test_data.__len__())*100
print("total_test_samples:", test_data.__len__(),
" test_acc:", "%.3f%%" % acc)

经过20个epoch的训练,在测试集上达到了98.590%的准确率,部分batch真实值与预测值展示如下:


5. 全部代码
链接:链接:https://pan.baidu.com/s/1GGhG1Slw2Tlsgl13yzHUIw
提取码:82l4
转载请说明出处
Pytorch CNN网络MNIST数字识别 [超详细记录] 学习笔记(三)的更多相关文章
- pytorch CNN 手写数字识别
一个被放弃的入门级的例子终于被我实现了,虽然还不太完美,但还是想记录下 1.预处理 相比较从库里下载数据集(关键是经常失败,格式也看不懂),更喜欢直接拿图片,从网上找了半天,最后从CSDN上下载了一个 ...
- 用pytorch做手写数字识别,识别l率达97.8%
pytorch做手写数字识别 效果如下: 工程目录如下 第一步 数据获取 下载MNIST库,这个库在网上,执行下面代码自动下载到当前data文件夹下 from torchvision.dataset ...
- muduo网络库学习笔记(三)TimerQueue定时器队列
目录 muduo网络库学习笔记(三)TimerQueue定时器队列 Linux中的时间函数 timerfd简单使用介绍 timerfd示例 muduo中对timerfd的封装 TimerQueue的结 ...
- Python 工匠:使用数字与字符串的技巧学习笔记
#Python 工匠:使用数字与字符串的技巧学习笔记#https://github.com/piglei/one-python-craftsman/blob/master/zh_CN/3-tips-o ...
- Keras cnn 手写数字识别示例
#基于mnist数据集的手写数字识别 #构造了cnn网络拟合识别函数,前两层为卷积层,第三层为池化层,第四层为Flatten层,最后两层为全连接层 #基于Keras 2.1.1 Tensorflow ...
- CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- 卷积神经网络CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- TensorFlow学习笔记(三)MNIST数字识别问题
一.MNSIT数据处理 MNSIT是一个非常有名的手写体数字识别数据集.包含60000张训练图片,10000张测试图片.每张图片是28X28的数字. TonserFlow提供了一个类来处理 MNSIT ...
- MNIST数字识别问题
摘自<Tensorflow:实战Google深度学习框架> import tensorflow as tf from tensorflow.examples.tutorials.mnist ...
随机推荐
- php 获取某年后的日期
比如两年后:date('Y-m-d',strtotime('+2 year')) 月份year改成month
- 三、jmeter常用的元件及组件
一.HTTP cookie Manager 用来储浏览器产生的用户信息,Stepping Thread Group 可用于模拟阶梯加压! 二.HTTP Cache Manager 缓存管理器(模拟浏览 ...
- activiti知识点梳理
一.Activiti是什么 Alfresco 软件在 2010 年 5 月17 日宣布 Activiti业务流程管理(BPM)开源项目的正式启动,其首席架构师由业务流程管理 BPM的专家 Tom Ba ...
- ajax 异步无刷新点改
<button class="status" t_id="{{$v->id}}">{{$v->status}}</button&g ...
- jQuery清空元素和克隆元素
1.清空 $(function () { $('#btn').click(function () { $('#ul1').html('') $('#ul1').empty() $('#ul1').re ...
- 基于混合云模式的calico部署
开始前准备 确定calico数据存储 Calico同时支持kubernetes api和etcd数据存储.官方给出的建议是在本地部署中使用K8S API,仅支持Kubernetes模式.而官方给出的e ...
- [bug] MySQL-Front连接MySQL 8.0失败
原因: MySQL-Front不支持MySQL 8.0的密码认证方式 解决: 在mysql安装目录中my.ini文件末尾添加 default_authentication_plugin=mysql_n ...
- Ansible_使用jinja2模板部署自定义文件
一.jinja2简介 1.jinja2模板 1️⃣:Ansible将jinja2模板系统用于模板文件,Ansible还使用jinja2语法来引用playbook中的变量 2️⃣:变量和逻辑表达式置于标 ...
- linux进阶之网络技术管理
本节内容 1. 网络七层模型 物理层 数据链路层 网络层 传输层 会话层 表示层 应用层 2. TCP/UDP (1)TCP面向连接,可靠传输,消耗系统资源比较多,传输速度较慢,但是数据传 ...
- Lua中的元表与元方法学习总结
前言 元表对应的英文是metatable,元方法是metamethod.我们都知道,在C++中,两个类是无法直接相加的,但是,如果你重载了"+"符号,就可以进行类的加法运算.在Lu ...