Huffman算法
一、Huffman算法介绍
霍夫曼编码(英语:Huffman Coding),又译为哈夫曼编码、赫夫曼编码,是一种用于无损数据压缩的熵编码(权编码)算法。在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现几率的方法得到的,出现几率高的字母使用较短的编码,反之出现几率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。
前缀代码表示以一种方式分配代码(位序列),以使分配给一个字符的代码不是分配给任何其他字符的代码的前缀。这就是霍夫曼编码如何确保在解码生成的比特流时没有歧义的地方。
让我们通过一个反例来了解前缀代码。假设有四个字符a,b,c和d,它们对应的可变长度代码分别为00、01、0和1。由于分配给c的代码是分配给a和b的代码的前缀,因此这种编码会产生歧义。如果压缩的比特流是0001,则解压缩的输出可以是“ cccd”或“ ccb”或“ acd”或“ ab”。
霍夫曼编码主要包括两个主要部分:
1)根据输入字符构建霍夫曼树。
2)遍历霍夫曼树并将代码分配给字符。
二、构建霍夫曼树的步骤
输入是唯一字符及其出现频率的数组,输出是霍夫曼树。
1. 为每个唯一字符创建一个叶节点,并为所有叶节点建立一个最小堆(Min Heap用作优先级队列。frequency字段的值用于比较最小堆中的两个节点。最初,把最不频繁的字符作为根)
2. 从最小堆中提取频率最小的两个节点。
3. 创建一个频率等于两个节点频率之和的新内部节点。使第一个提取的节点为其左子节点,另一个提取的节点为其右子节点。将此节点添加到最小堆中。
4. 重复步骤2和3,直到堆仅包含一个节点。其余节点是根节点,树已完成。
一个例子:
| 字符 | A | B | C | D | E |
| 频率 | 1 | 7 | 6 | 5 | 2 |
步骤1:构建一个包含5个节点的最小堆,其中每个节点代表具有单个节点的树的根。
步骤2:从最小堆中提取两个最小频率节点。添加一个频率为1 + 2 = 3的新内部节点。
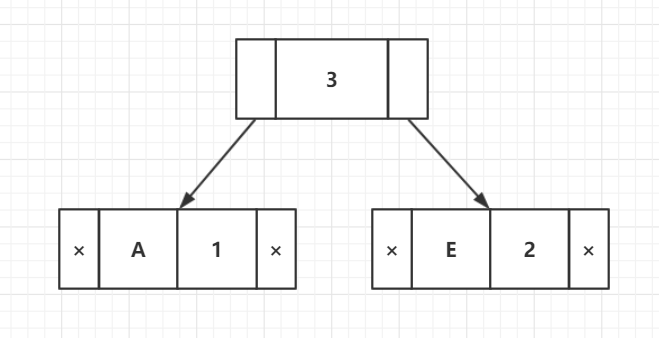
现在最小堆包含4个节点,其中3个节点是每个具有单个元素的结点,一个堆节点是具有3个元素。
| 字符 | 频率 |
| 内部节点 | 3 |
| D | 5 |
| C | 6 |
| B | 7 |
步骤3:从堆中提取两个最低频率节点。添加频率为12 + 13 = 25的新内部节点

现在最小堆包含3个节点,其中2个节点是每个具有单个元素的节点,两个堆节点是具有多个节点的子树。
| 字符 | 频率 |
| 内部节点 | 8 |
| C | 6 |
| B | 7 |
步骤4:提取两个最低频率节点。添加频率为6 + 7 = 13的新内部节点
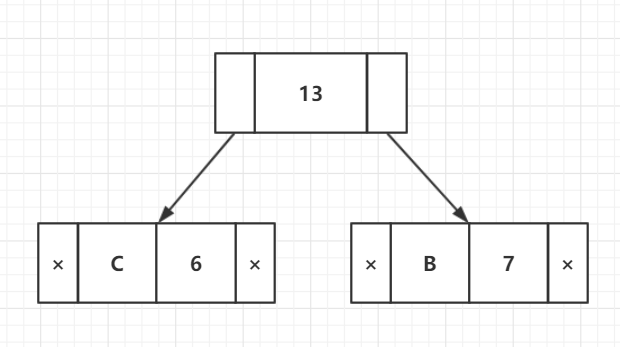
现在,最小堆包含2个节点。
| 字符 | 频率 |
| 内部节点 | 8 |
| 内部节点 | 13 |
步骤6:提取两个最低频率节点。添加频率为8 + 13 = 21的新内部节点
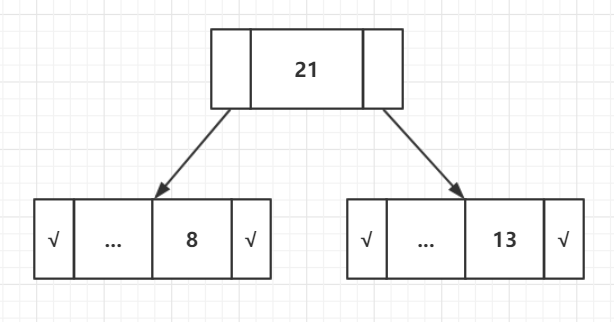
现在最小堆中只剩下一个节点,因此算法在此处停止。
从霍夫曼树打印代码的步骤:
遍历从根开始形成的树。维护一个辅助阵列。当移到左孩子时,将0写入数组。当移动到正确的孩子时,将1写入数组。遇到叶节点时打印阵列。
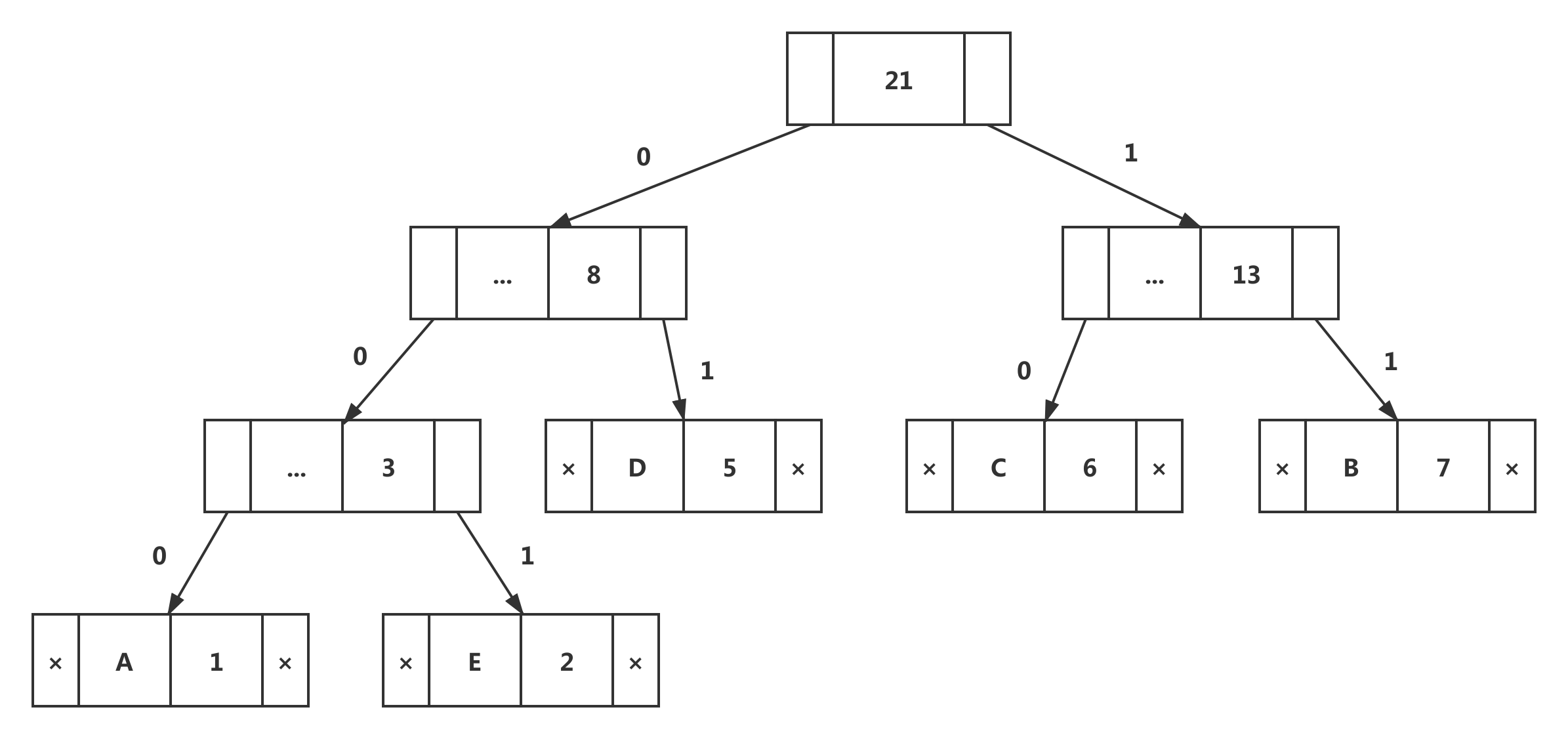
输出如下:
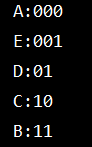
源代码:
1 package tree;
2
3 import java.util.Comparator;
4 import java.util.PriorityQueue;
5
6 /**
7 * 这是一个哈夫曼树 (Huffman Tree),用于无损数据压缩的熵编码算法
8 * 哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
9 */
10 public class HuffmanTree {
11
12 /**
13 * 通过树遍历的霍夫曼代码
14 * @param root
15 * @param s
16 */
17 public static void printCode(HuffmanNode root, String s) {
18 /* 如果左右为空,那么这就是一个叶子结点 */
19 if (root.left == null && root.right == null && Character.isLetter(root.c)) {
20 System.out.println(root.c + ":" + s);
21 return;
22 }
23 assert root.left != null;
24 printCode(root.left, s + "0");
25 printCode(root.right, s + "1");
26 }
27
28 public static void main(String[] args) {
29
30 int n = 5; // 字符数量
31
32 /* 下面那个例子的最后结果:
33 A:000
34 E:001
35 D:01
36 C:10
37 B:11
38 */
39 char[] charArray = {'A', 'B', 'C', 'D', 'E'};
40 int[] charfreq = {1, 7, 6, 5, 2};
41
42 /* 创建优先级队列q,创建一个最低优先级队列(min-heap)。*/
43 PriorityQueue<HuffmanNode> q = new PriorityQueue<>(n, new MyComparator());
44
45 /* 为每个字符创建一个Huffman树的叶子结点,并 */
46 for (int i = 0; i < n; i++) {
47 /* 创建一个Huffman节点对象,并将其添加到优先级队列。*/
48 HuffmanNode hn = new HuffmanNode();
49
50 hn.c = charArray[i];
51 hn.data = charfreq[i];
52
53 hn.left = null;
54 hn.right = null;
55
56 q.add(hn);
57 }
58
59 /* 创建一个Huffman根节点 */
60 HuffmanNode root = null;
61
62 while (q.size() > 1) {
63 /* 提取第一个最小的。*/
64 HuffmanNode x = q.peek();
65 q.poll();
66
67 /* 提取第二个最小的。*/
68 HuffmanNode y = q.peek();
69 q.poll();
70
71 /* 新建一个新结点,将两个节点的频率之和分配给f节点 */
72 HuffmanNode f = new HuffmanNode();
73 f.data = x.data + y.data;
74 f.c = '-';
75
76 f.left = x;
77 f.right = y;
78
79 root = f;
80
81 q.add(f);
82 }
83
84 printCode(root, "");
85 }
86 }
87
88 /**
89 * 哈夫曼节点
90 */
91 class HuffmanNode {
92 int data;
93 char c;
94
95 HuffmanNode left;
96 HuffmanNode right;
97 }
98
99 /**
100 * 用于比较哈夫曼节点值的大小
101 */
102 class MyComparator implements Comparator<HuffmanNode> {
103
104 @Override
105 public int compare(HuffmanNode o1, HuffmanNode o2) {
106 return o1.data - o2.data;
107 }
108 }
Huffman算法的更多相关文章
- Codeforces Round #263 (Div. 2)C(贪心,联想到huffman算法)
数学家伯利亚在<怎样解题>里说过的解题步骤第二步就是迅速想到与该题有关的原型题.(积累的重要性!) 对于这道题,可以发现其实和huffman算法的思想很相似(可能出题人就是照着改编的).当 ...
- 闲来无事写写-Huffman树的生成过程
前言:最近项目上一直没事干,感觉无聊到了极点,给自己找点事做,补一下大学没有完成的事情,写一个huffman算法Java版的,学校里面写过c语言的. 因为很久没搞数据结构和算法这方面了(现在搞Java ...
- 哈夫曼树【最优二叉树】【Huffman】
[转载]只为让价值共享,如有侵权敬请见谅! 一.哈夫曼树的概念和定义 什么是哈夫曼树? 让我们先举一个例子. 判定树: 在很多问题的处理过程中,需要进行大量的条件判断,这些判断结构的设 ...
- Huffman 编码压缩算法
前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法.相信大家应该听说过 David Huffman 和他的压缩算法—— Huffman Code,一种通过字 ...
- FastText算法原理解析
1. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.fasttext是facebook开源的一个词向量与文本分类工 ...
- [转载]Huffman编码压缩算法
转自http://coolshell.cn/articles/7459.html 前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法.相信大家应该听说过 D ...
- 数据压缩算法之哈夫曼编码(HUFFMAN)的实现
HUFFMAN编码可以很有效的压缩数据,通常可以压缩20%到90%的空间(算法导论).具体的压缩率取决于数据的特性(词频).如果采取标准的语料库进行编码,一般可以得到比较满意的编码结果(对不同文件产生 ...
- FastText算法
转载自: https://www.cnblogs.com/huangyc/p/9768872.html 0. 目录 1. 前言 2. FastText原理 2.1 模型架构 2.2 层次SoftMax ...
- Huffman编码实现压缩解压缩
这是我们的课程中布置的作业.找一些资料将作业完毕,顺便将其写到博客,以后看起来也方便. 原理介绍 什么是Huffman压缩 Huffman( 哈夫曼 ) 算法在上世纪五十年代初提出来了,它是一种无损压 ...
随机推荐
- clickonce的密钥到期问题处理
最近clickonce的密钥到期了,在网上找了些文章用来修改密钥的到期时间,已成功生成新密钥,好不好使暂时未测. 在此小结一下,以备参考: 1.在原密钥所属电脑上cmd执行如下命令 renewcert ...
- CLR无法从COM 上下文*****转换为COM上下文*****,这种状态已持续60秒。
异常信息:CLR无法从COM 上下文0x645e18 转换为COM上下文0x645f88,这种状态已持续60秒.拥有目标上下文/单元的线程很有可能执行的是非泵式等待或者在不发送 Windows 消息的 ...
- Thinkphp5 主动式 计划任务 支持windows和linux
百度搜索过相关的php计划任务的资料,特别是搜索thinkphp的计划任务,目前能明确实现的都是被动式的,就是通过tp3.2自带的计划任务类实现,通过挂钩子的形式,用户访问网站的时候就执行计划任务,这 ...
- python对象引用和垃圾回收
变量="标签" 变量a和变量b引用同一个列表: >>> a = [1, 2, 3] >>> b = a >>> a.appen ...
- [转载]CentOS 7 创建本地YUM源
本文中的"本地YUM源"包括三种类型:一是直接使用CentOS光盘作为本地yum源,优点是简单便捷,缺点是光盘软件包可能不完整(centos 7 Everything 总共才6.5 ...
- CF622F-The Sum of the k-th Powers【拉格朗日插值】
正题 题目链接:https://www.luogu.com.cn/problem/CF622F 题目大意 给出\(n,k\),求 \[\sum_{i=1}^ni^k \] 解题思路 很经典的拉格朗日差 ...
- CF786C-Till I Collapse【树状数组倍增,优先队列】
正题 题目链接:https://www.luogu.com.cn/problem/CF786C 题目大意 给出一个长度为\(n\)的序列. 对于每个\(k\in[1,n]\)求将\(n\)分成最少的段 ...
- 《集体智慧编程学习笔记》——Chapter2:提供推荐
知识点: 1. 协作型过滤--Collaboraive Filtering 通常的做法是对一群人进行搜索,并从中找出与我们品味相近的一小群人,算法会对这些人的偏好进行考察,并将它们组合起来构造出一个经 ...
- 浅析 Java 内存模型
文章转载于 飞天小牛肉 的 <「跬步千里」详解 Java 内存模型与原子性.可见性.有序性>.<JMM 最最最核心的概念:Happens-before 原则> 1. 为什么要学 ...
- Hbase修复工具Hbck
因为前面Hbase2集群出现过一次故障,当时花了一个周末才修好,就去了解整理了一些hbase故障的,事故现场可以看前面写的一篇:Hbase集群挂掉的一次惊险经历 一. HBCK一致性 一致性是指Reg ...