[ML] Daily Portfolio Statistics
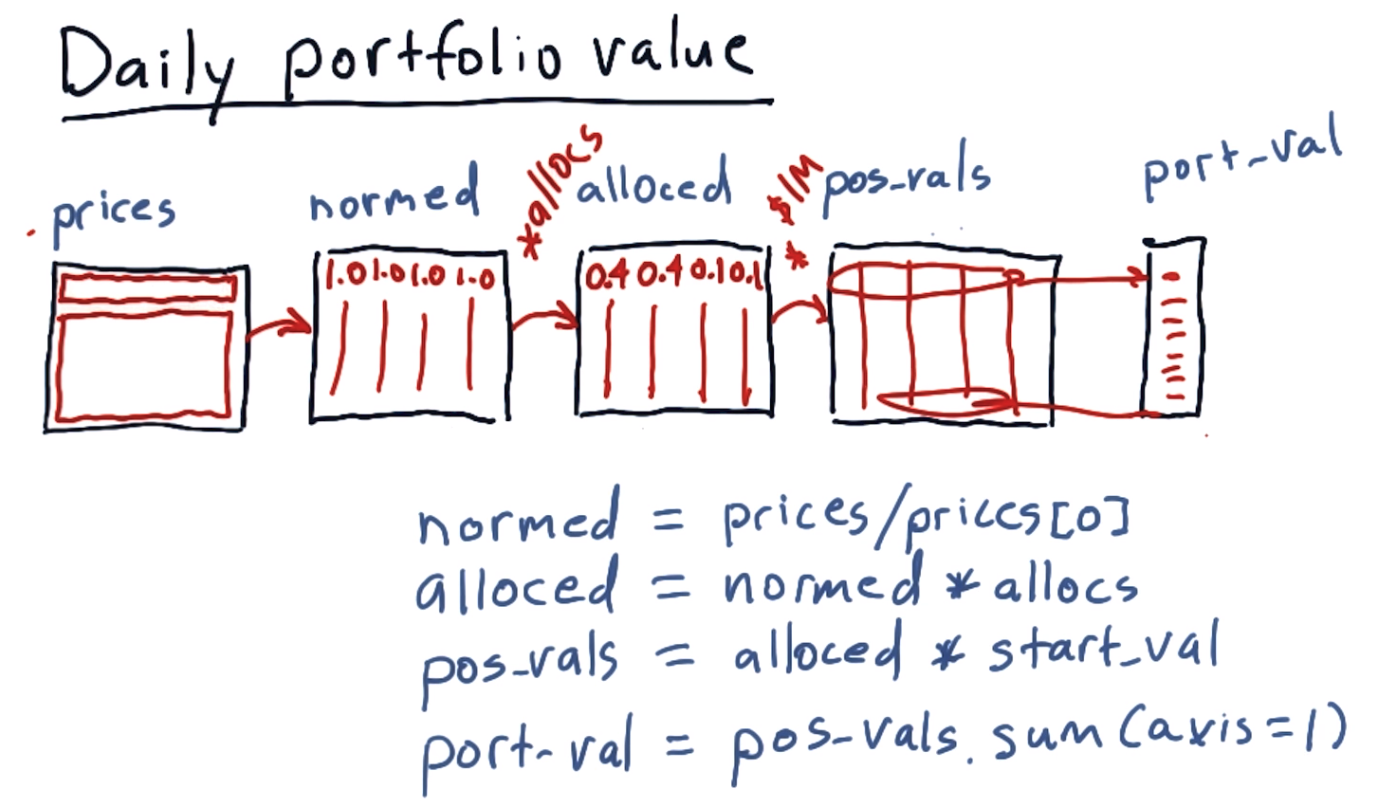
Let's you have $10000, and you inverst 4 stocks. ['SPY', 'IBM', 'XOM', 'GOOG']. The allocation is [0.4, 0.4, 0.1, 0.1] separately.
The way to calculate the daily porfolio is
- Normalize the price by devide price of first day.
- Nored * allocation
- * starting value
- Sum up each row
After we can port value, the first thing we can calculate is the daily return.
The important thing to remember that the first value of daily return is alwasy zero, so we need to remove the first value.
daily_rets = daily_rets[1:]
Four statics:
1. Cumulative return:
Is a just a measure of how much the value of the portfolio has go up from the beginning to the end.
cum_ret = (port_val[-] / port_val[]) -
2. Average daily return:
The mean value of daily return
avg_daily_ret = daily_rets.mean()
3. Standard deviation of odaily return:
std_daily_ret = daily_rets.std()
4. Sharp ratio:
The idea for sharp ratio is to consider our return, or rewards in the context of risk.
All else being equal:
Lower risk is better
Higher return is better
Also considers risk free rate of return, nowadays, risk free return is almost 0. (Put menoy into the bank has very low interests)
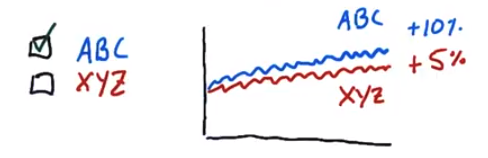
Both stocks have similar volatility, so ABC is better due greater returns.
Here both stocks have similar returns, but XYZ has lower volatility (risk).
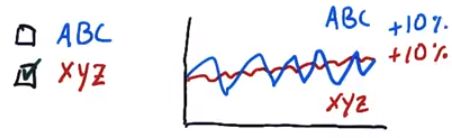
In this case, we actually do not have a clear picture of which stock is better!

Calculate Shape ratio:

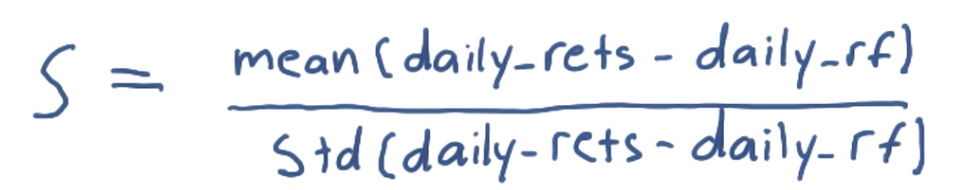
Risk free value can be replace by:
1. LIBOR
2. 3mo T-Bill
3. 0%
Because risk free is so small, noramlly we can just drop it when calculate the sharp raito.
IF we calcualte daily shape ratio: use K = srq(252), monly then srq(12)

[ML] Daily Portfolio Statistics的更多相关文章
- 一篇文章看懂spark 1.3+各版本特性
Spark 1.6.x的新特性Spark-1.6是Spark-2.0之前的最后一个版本.主要是三个大方面的改进:性能提升,新的 Dataset API 和数据科学功能的扩展.这是社区开发非常重要的一个 ...
- Scoring and Modeling—— Underwriting and Loan Approval Process
https://www.fdic.gov/regulations/examinations/credit_card/ch8.html Types of Scoring FICO Scores V ...
- Stanford机器学习笔记-3.Bayesian statistics and Regularization
3. Bayesian statistics and Regularization Content 3. Bayesian statistics and Regularization. 3.1 Und ...
- FAQ: Automatic Statistics Collection (文档 ID 1233203.1)
In this Document Purpose Questions and Answers What kind of statistics do the Automated tasks ...
- oracle internal: VIEW: X$KCBKPFS - PreFetch Statistics - (9.0)
WebIV:View NOTE:159898.1 Note (Sure) - Note Mods - Note Refs Error ORA 600 TAR TAR-Info Bug B ...
- ML笔记_机器学习基石01
1 定义 机器学习 (Machine Learning):improving some performance measure with experience computed from data ...
- Spark ML 几种 归一化(规范化)方法总结
规范化,有关之前都是用 python写的, 偶然要用scala 进行写, 看到这位大神写的, 那个网页也不错,那个连接图做的还蛮不错的,那天也将自己的博客弄一下那个插件. 本文来源 原文地址:htt ...
- Google's Machine Learning Crash Course #01# Introducing ML & Framing & Fundamental terminology
INDEX Introducing ML Framing Fundamental machine learning terminology Introducing ML What you learn ...
- [ML] I'm back for Machine Learning
Hi, Long time no see. Briefly, I plan to step into this new area, data analysis. In the past few yea ...
随机推荐
- code-reading-notes--libyang-1
API struct lyd_node * lyd_parse_xml(struct ly_ctx *ctx, struct lyxml_elem **root, int options, ...) ...
- ItChat与图灵机器人的结合
前景: 我在知乎关注一位大佬 名字叫 LittleCoder 我是在他开发ItChat包时关注的 ItChat已经完成了微信的个人账号的API接口 已经实现了实时获取用户的即时信息并自动化进行回应 后 ...
- JavaScript中的常用的数组操作方法
JavaScript中的常用的数组操作方法 一.concat() concat() 方法用于连接两个或多个数组.该方法不会改变现有的数组,仅会返回被连接数组的一个副本. var arr1 = [1,2 ...
- 【转】Visual Studio單元測試小應用-測執行時間
[转]Visual Studio單元測試小應用-測執行時間 Visual Studio的單元測試會記錄每一個測試的執行時間,如果有幾個Method要測效能,以前我會用Stopwatch,最近我都改用單 ...
- Android之——自己定义TextView
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/47082241 在这一篇博文中,将向大家介绍怎样以最简单的方式,来自己定义Andro ...
- easyui编辑器(kindeditor-4.1.10)
//1 重写kindedit -建一个js文件 easyui_kindeditor.js (function ($, K) { if (!K) throw " ...
- JS数组去重 包含去除多个 NaN
Array.prototype.uniq = function () { var arr = []; var flag = true; this.forEach(function(item) { ...
- KafkaZookeeper1-整体介绍
版本 1.0.0 概述 本文介绍了 kafka 中 zookeeper 的整体实现. 最初 kafka 使用同步的方式访问 zookeeper.但是对于 partition 个数很多的cluster, ...
- Django(part2)
admin site:django自带了admin site,我们需要创建能访问site的用户 #以交互的方式创建超级用户 manage.py createsuperuser 如果要把model加到a ...
- (转载) Scrollview 嵌套 RecyclerView 及在Android 5.1版本滑动时 惯性消失问题
Scrollview 嵌套 RecyclerView 及在Android 5.1版本滑动时 惯性消失问题 标签: scrollviewandroid滑动嵌套 2015-07-16 17:24 1112 ...