Disruptor并发框架 (二)核心概念场景分析
核心术语
- RingBuffer(容器): 被看作Disruptor最主要的组件,然而从3.0开始RingBuffer仅仅负责存储和更新在Disruptor中流通的数据。对一些特殊的使用场景能够被用户(使用其他数据结构)完全替代。
- Sequence(槽位置): Disruptor使用Sequence来表示一个特殊组件处理的序号。和Disruptor一样,每个消费者(EventProcessor)都维持着一个Sequence。大部分的并发代码依赖这些Sequence值的运转,因此Sequence支持多种当前为AtomicLong类的特性。
- Sequencer: 这是Disruptor真正的核心。实现了这个接口的两种生产者(单生产者和多生产者)均实现了所有的并发算法,为了在生产者和消费者之间进行准确快速的数据传递。
- SequenceBarrier(生产消费者冲突问题解决): 由Sequencer生成,并且包含了已经发布的Sequence的引用,这些的Sequence源于Sequencer和一些独立的消费者的Sequence。它包含了决定是否有供消费者来消费的Event的逻辑。
- WaitStrategy:决定一个消费者将如何等待生产者将Event置入Disruptor。
- Event:从生产者到消费者过程中所处理的数据单元。Disruptor中没有代码表示Event,因为它完全是由用户定义的。
- EventProcessor(生产线程):主要事件循环,处理Disruptor中的Event,并且拥有消费者的Sequence。它有一个实现类是BatchEventProcessor,包含了event loop有效的实现,并且将回调到一个EventHandler接口的实现对象。
- EventHandler(消费者):由用户实现并且代表了Disruptor中的一个消费者的接口。
- Producer:由用户实现,它调用RingBuffer来插入事件(Event),在Disruptor中没有相应的实现代码,由用户实现。
- WorkProcessor:确保每个sequence只被一个processor消费,在同一个WorkPool中的处理多个WorkProcessor不会消费同样的sequence。
- WorkerPool:一个WorkProcessor池,其中WorkProcessor将消费Sequence,所以任务可以在实现WorkHandler接口的worker吃间移交
- LifecycleAware:当BatchEventProcessor启动和停止时,于实现这个接口用于接收通知。
初看Disruptor,给人的印象就是RingBuffer是其核心,生产者向RingBuffer中写入元素,消费者从RingBuffer中消费元素,如下图:
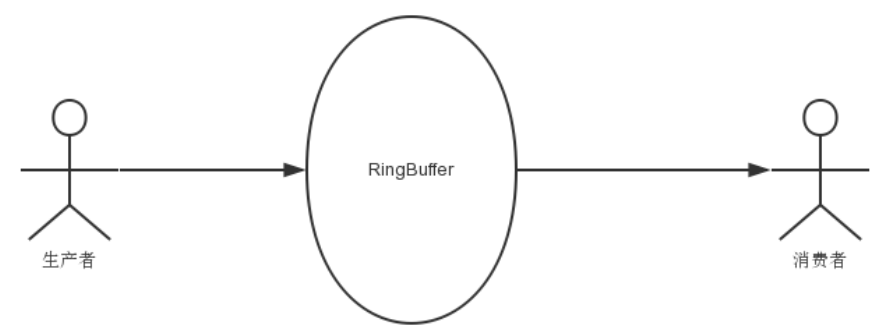
ringbuffer究竟是什么?
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer
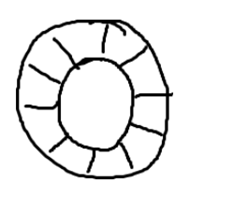
ringbuffer拥有一个序号,这个序号指向数组中下一个可用元素
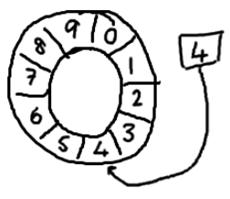
Disruptor说的是生产者和消费者的故事. 有一个数组.生产者往里面扔芝麻.消费者从里面捡芝麻. 但是扔芝麻和捡芝麻也要考虑速度的问题. 1 消费者捡的比扔的快 那么消费者要停下来.生产者扔了新的芝麻,然后消费者继续. 2 数组的长度是有限的,生产者到末尾的时候会再从数组的开始位置继续.这个时候可能会追上消费者,消费者还没从那个地方捡走芝麻,这个时候生产者要等待消费者捡走芝麻,然后继续.
进一步理解
1如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。
2我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠。
3因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。
4这是对CPU缓存友好的,也就是说在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。
5其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
Disruptor并发框架 (二)核心概念场景分析的更多相关文章
- Disruptor 系列(二)使用场景
Disruptor 系列(二)使用场景 今天用一个订单问题来加深对 Disruptor 的理解.当系统中有订单产生时,系统首先会记录订单信息.同时也会发送消息到其他系统处理相关业务,最后才是订单的处理 ...
- 并发编程之Disruptor并发框架
一.什么是Disruptor Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易.这个系统是建立在JV ...
- Disruptor 并发框架
什么是Disruptor Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易.这个系统是建立在JVM平 ...
- Java并发-线程池篇-附场景分析
作者:汤圆 个人博客:javalover.cc 前言 前面我们在创建线程时,都是直接new Thread(): 这样短期来看是没有问题的,但是一旦业务量增长,线程数过多,就有可能导致内存异常OOM,C ...
- Disruptor并发框架(一)简介&上手demo
框架简介 Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易.这个系统是建立在JVM平台上,其核心是一 ...
- Disruptor并发框架简介
Martin Fowler在自己网站上写一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金额交易平台,它能够以很低的延迟产生大量交易.这个系统是建立在JVM平台上,其核心是一个业务逻辑处 ...
- fusionjs 学习二 核心概念
核心概念 middleware 类似express 的中间件模型(实际上是构建在koa中间件模型上的),但是和koa 的中间件有差异 fusionjs 的中间件同时可以运行在浏览器页面加载的时候 se ...
- Disruptor 高性能并发框架二次封装
Disruptor是一款java高性能无锁并发处理框架.和JDK中的BlockingQueue有相似处,但是它的处理速度非常快!!!号称“一个线程一秒钟可以处理600W个订单”(反正渣渣电脑是没体会到 ...
- 架构师养成记--15.Disruptor并发框架
一.概述 disruptor对于处理并发任务很擅长,曾有人测过,一个线程里1s内可以处理六百万个订单,性能相当感人. 这个框架的结构大概是:数据生产端 --> 缓存 --> 消费端 缓存中 ...
随机推荐
- 计算机网络初探(ip协议)
粗读了两遍计算机网络(谢希仁),对于计算计算机网络算是有了一个初步的了解,所以打算写一篇文章(希望是教程)进行巩固(主要围绕IP协议). 局域网 因特网的产生和广泛使用极大地改变了我们的生活,但对于不 ...
- CCF-201403-1-相反数
问题描述 试题编号: 201403-1 试题名称: 相反数 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 有 N 个非零且各不相同的整数.请你编一个程序求出它们中有多少对相反 ...
- 关于xshell:Connection closed by foreign host
因为原来系统网有时掉,有时卡(同局域网别人没事),重新做了系统. 装了xmanager3,在用xshell连接linux服务器时,提示:服务器发送了一个无效的密钥,然后输出:Connection cl ...
- KafkaManager中Group下不显示对应Topic的解决方案
一.软件版本 Kafka:0.8.2.1 KafkaManager:1.2.9.10 二.问题现象 点击Consumer下某个组,显示如下图所示的异常,查看KafkaManager的Applicati ...
- MyBatis多租户隔离插件开发
在SASS的大潮流下,相信依然存在很多使用一个数据库为多个租户提供服务的场景,这个情况下一般是多个租户共用同一套表通过sql语句级别来隔离不同租户的资源,比如设置一个租户标识字段,每次查询的时候在后面 ...
- Caffe-5.2-(GPU完整流程)训练(依据googlenet微调)
上一篇使用caffenet的模型微调.但由于caffenet有220M太大,測试速度太慢.因此换为googlenet. 1. 训练 迭代了2800次时死机,大概20分钟. 使用的是2000次的模型. ...
- Java中用Apache POI生成excel和word文档
概述: 近期在做项目的过程中遇到了excel的数据导出和word的图文表报告的导出功能.最后决定用Apache POI来完毕该项功能.本文就项目实现过程中的一些思路与代码与大家共享.同一时候.也作为自 ...
- 基于 HTML5 Canvas 的 3D 机房创建
对于 3D 机房来说,监控已经不是什么难事,不同的人有不同的做法,今天试着用 HT 写了一个基于 HTML5 的机房,发现果然 HT 简单好用.本例是将灯光.雾化以及 eye 的最大最小距离等等功能在 ...
- 服务器固件测试--PCI设备的介绍(集成网卡和外插网卡)
今天2017年9月26号,快三个月的时间,是该梳理一下,我来到这个岗位学到的东西. 网卡是什么 网卡分为俩大类 板载的集成网卡和外插的网卡.外插的网卡又分为很多种. 板载的集成网卡 外插的网卡分为 I ...
- 获取spring容器上下文(webApplicationContext)的几种方法
在很多情况,我们需要先获取spring容器上下文,即webApplicationContext,然后通过webApplicationContext来获取其中的bean.典型的情况是,我想在一个并未委托 ...