【机器学习】支持向量机(SVM)
感谢中国人民大学胡鹤老师,课程深入浅出,非常好
一、关于SVM
可以做线性分类、非线性分类、线性回归等,相比逻辑回归、线性回归、决策树等模型(非神经网络)功效最好
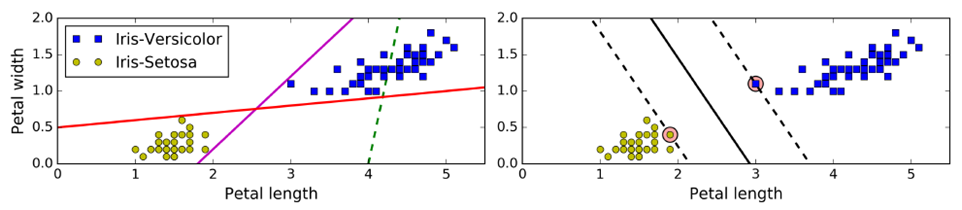
传统线性分类:选出两堆数据的质心,并做中垂线(准确性低)——上图左
SVM:拟合的不是一条线,而是两条平行线,且这两条平行线宽度尽量大,主要关注距离车道近的边缘数据点(支撑向量support vector),即large margin classification——上图右

使用前,需要对数据集做一个scaling,以做出更好的决策边界(decision boundary)
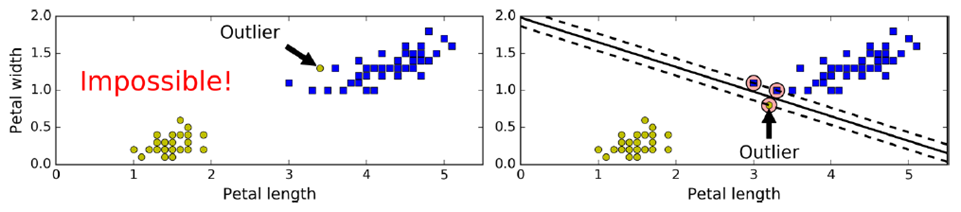
但需要容忍一些点跨越分割界限,提高泛化性,即softmax classification
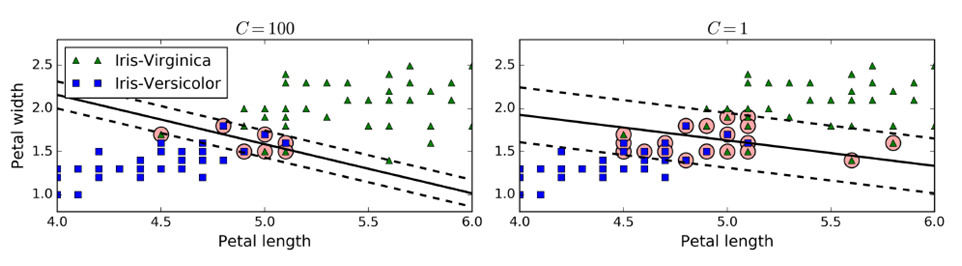
在sklearn中,有一个超参数c,控制模型复杂度,c越大,容忍度越小,c越小,容忍度越高。c添加一个新的正则量,可以控制SVM泛化能力,防止过拟合。(一般使用gradsearch)
SVM特有损失函数Hinge Loss

二、LinearSVC(liblinear库,不支持kernel函数,但是相对简单,复杂度O(m*n))
同SVM特点吻合,仅考虑落在分类面附近和越过分类面到对方领域的向量,给于一个线性惩罚(l1),或者平方项(l2)
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y = (iris["target"]==2).astype(np.float64)
svm_clf = Pipeline((
("scaler",StandardScaler()),
("Linear_svc",LinearSVC(C=1,loss="hinge")),
))
svm_clf.fit(X,y)
print(svm_clf.predit([[5.5,1.7]]))
三、对于nonlinear数据的分类
有两种方法,构造高维特征,构造相似度特征
1. 使用高维空间特征(即kernel的思想),将数据平方、三次方。。映射到高维空间上
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline((
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
))
polynomial_svm_clf.fit(X, y)
这种kernel trick可以极大地简化模型,不需要显示的处理高维特征,可以计算出比较复杂的情况
但模型复杂度越强,过拟合风险越大
SVC(基于libsvm库,支持kernel函数,但是相对复杂,不能用太大规模数据,复杂度O(m^2 *n)-O(m^3 *n))
可以直接使用SVC(coef0:高次与低次权重)
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)
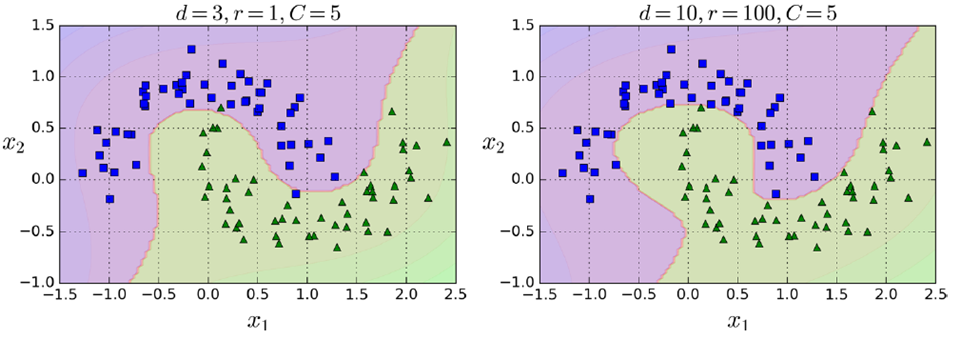
2. 添加相似度特征(similarity features)
例如,下图分别创造x1,x2两点的高斯分布,再创建新的坐标系统,计算高斯距离(Gaussian RBF Kernel径向基函数)
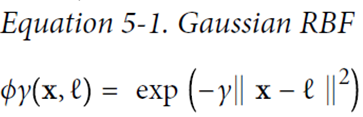
gamma(γ)控制高斯曲线形状胖瘦,数据点之间的距离发挥更强作用
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
))
rbf_kernel_svm_clf.fit(X, y)

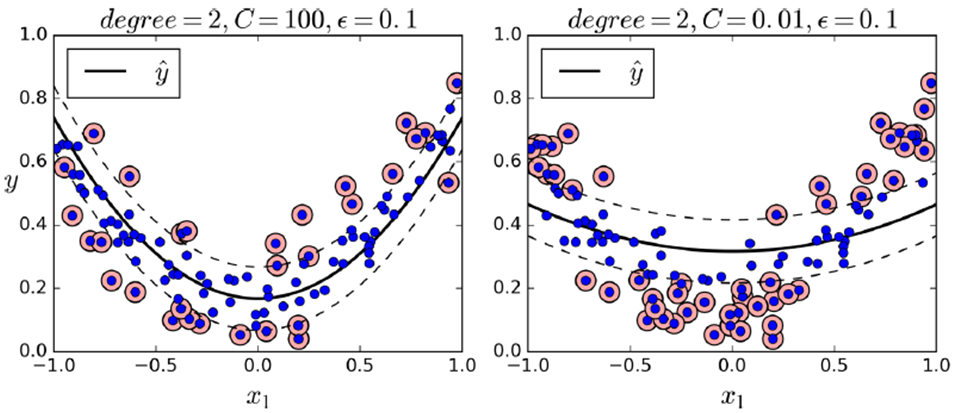
如下是不同gamma和C的取值影响

SGDClassifier(支持海量数据,时间复杂度O(m*n))
四、SVM Regression(SVM回归)
尽量让所用instance都fit到车道上,车道宽度使用超参数 控制,越大越宽
控制,越大越宽
使用LinearSVR
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)
使用SVR
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
五、数学原理:

w通过控制h倾斜的角度,控制车道的宽度,越小越宽,并且使得违反分类的数据点更少
1. hard margin linear SVM
优化目标: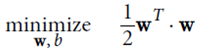 ,并且保证
,并且保证

2. soft margin linear SVM
增加一个新的松弛变量(slack variable)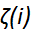 ,起正则化作用
,起正则化作用
优化目标: ,并且保证
,并且保证
放宽条件,即使有个别实例违反条件,也惩罚不大
3. LinearSVM
使用拉格朗日乘子法进行计算,α是松弛项后的结果
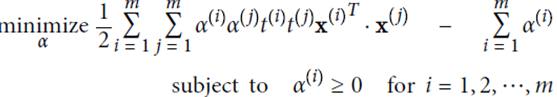
计算结果: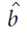 取平均值
取平均值
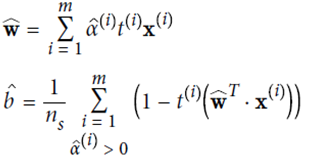
KernelizedSVM
由于
故可先在低位空间里做点积计算,再映射到高维空间中。
下列公式表示,在高维空间计算可用kernel trick方式,直接在低维上面计算


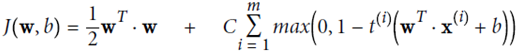
几个常见的kernal及其function

【机器学习】支持向量机(SVM)的更多相关文章
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析
SVM有很多实现,现在只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使用一种核函数(kernel)的方式将SVM ...
- coursera机器学习-支持向量机SVM
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 机器学习-支持向量机SVM
简介: 支持向量机(SVM)是一种二分类的监督学习模型,他的基本模型是定义在特征空间上的间隔最大的线性模型.他与感知机的区别是,感知机只要找到可以将数据正确划分的超平面即可,而SVM需要找到间隔最大的 ...
- 机器学习——支持向量机(SVM)
支持向量机原理 支持向量机要解决的问题其实就是寻求最优分类边界.且最大化支持向量间距,用直线或者平面,分隔分隔超平面. 基于核函数的升维变换 通过名为核函数的特征变换,增加新的特征,使得低维度空间中的 ...
- 机器学习支持向量机SVM笔记
SVM简述: SVM是一个线性二类分类器,当然通过选取特定的核函数也可也建立一个非线性支持向量机.SVM也可以做一些回归任务,但是它预测的时效性不是太长,他通过训练只能预测比较近的数据变化,至于再往后 ...
- 机器学习——支持向量机(SVM)之核函数(kernel)
对于线性不可分的数据集,可以利用核函数(kernel)将数据转换成易于分类器理解的形式. 如下图,如果在x轴和y轴构成的坐标系中插入直线进行分类的话, 不能得到理想的结果,或许我们可以对圆中的数据进行 ...
- 机器学习——支持向量机(SVM)之Platt SMO算法
Platt SMO算法是通过一个外循环来选择第一个alpha值的,并且其选择过程会在两种方式之间进行交替: 一种方式是在所有数据集上进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描. 所谓 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
随机推荐
- Jquery第一篇【介绍Jquery、回顾JavaScript代码、JS对象与JQ对象的区别】
什么是Jquery? Jquey就是一款跨主流浏览器的JavaScript库,简化JavaScript对HTML操作 就是封装了JavaScript,能够简化我们写代码的一个JavaScript库 为 ...
- JVM菜鸟进阶高手之路十(基础知识开场白)
转载请注明原创出处,谢谢! 最近没有什么实战,准备把JVM知识梳理一遍,先以开发人员的交流来谈谈jvm这块的知识以及重要性,依稀记得2.3年前用solr的时候老是经常oom,提到oom大家应该都不陌生 ...
- 使用Spring的隐式注解和装配以及使用SpringTest框架
SpringTestConfiguration 1.加入jar 包spring-test-4.3.9.RELEASE.jar 2.写基本的Component 注意级联状态下 需要给需要调用的属性加入 ...
- js'初学笔记
之前看过一个博主说的学习前端养成写博客的习惯,我慢慢学着在上面写点东西,记录我的学习. 这段时间把之前学的js基础补上一点,学了一些对数组和字符的操作,split(),将字符串变成数组.join(), ...
- 大数据 - Teradata学习体会
引言 随着计算机系统在处理能力.存储能力等方面,特别是计算机软件技术的不断提高,使得信息处理技术得到飞速发展. 数据处理主要分为两大类:联机事物处理OLTP.联机分析处理OLAP.OLTP也就是传统的 ...
- ArrayList ConcurrentModificationException
1.ConcurrentModificationException ConcurrentModificationException 出现在使用 ForEach遍历,迭代器遍历的同时,进行删除,增加出现 ...
- Qt下 QString转char*
Qt下面,字符串都用QString,确实给开发者提供了方便.Qt再使用第三方开源库时,由于库的类型基本上都是标准的类型,字符串遇的多的就是Char*类型 Qt再使用第三方开源库时,由于库的类型基本上都 ...
- 【POJ】2348 Euclid's Game(扩欧)
Description Two players, Stan and Ollie, play, starting with two natural numbers. Stan, the first pl ...
- 模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- localStorage和sessionStorage总结以及区别
(1)兼容的手机和浏览器: (2)使用 .setItem( key, value)存键值数据 sessionStorage.setItem("key","value&qu ...