爬取软考试题系列之ip自动代理
马上5月份有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.com网上的软考试题。
以上为背景。
很久没有更新博客园的博客了,所以之前的代码没有及时的贴出来,咱们就从今天开始,讲述一下我爬取软考试题的故(keng)事(shi)。现在我已经能自动抓取某一个模块的所有题目了,如下图:
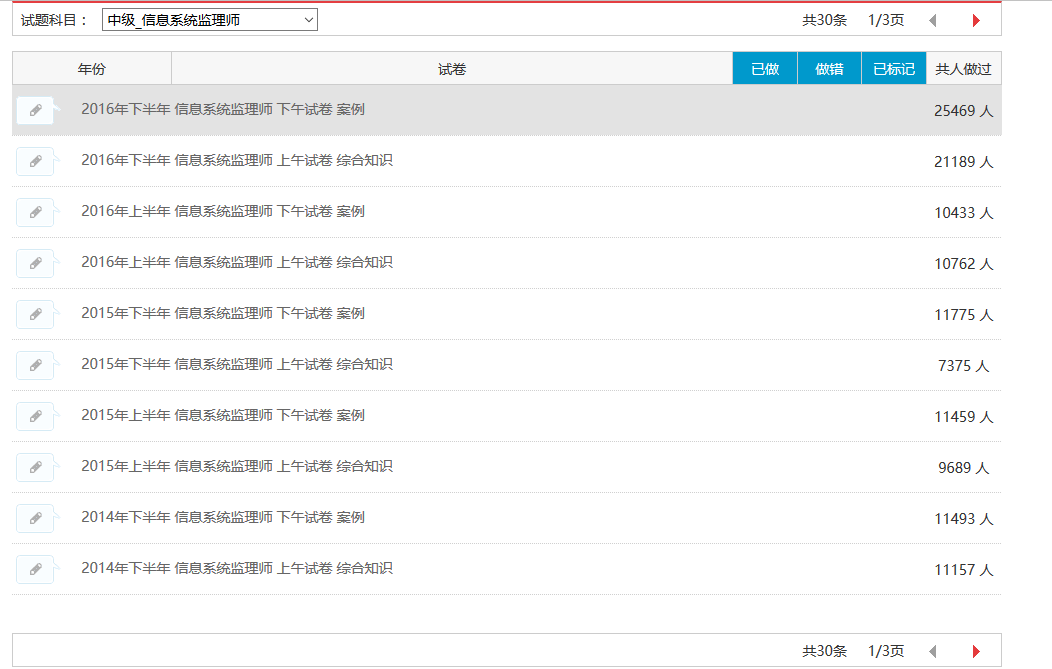
目前可以将信息系统监理师的30条试题记录全部抓取下来,结果如下图所示:
 抓取下来的内容图片:
抓取下来的内容图片:

虽然可以将部分信息抓取下来,但是代码的质量并不高,以抓取信息系统监理师为例,因为目标明确,各项参数清晰,为了追求能在短时间内抓取到试卷信息,所以并没有做异常处理,昨天晚上填了很久的坑。
回到主题,今天写这篇博客,是因为又遇到新坑了。从博客标题我们可以猜出个大概,肯定是请求次数过多,所以ip被网站的反爬虫机制给封了。
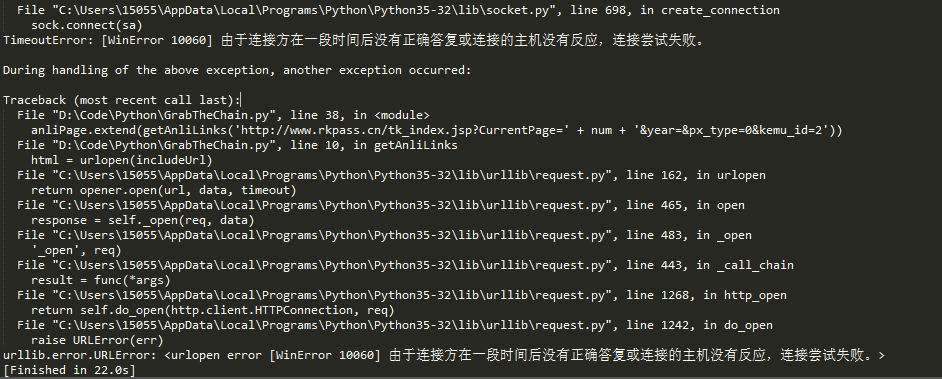
活人不能让尿憋死,革命先辈的事迹告诉我们,作为社会主义的接班人,我们不能屈服于困难,逢山开路,遇水搭桥,为了解决ip问题,ip代理这个思路就出来了。
在网络爬虫抓取信息的过程中,如果抓取频率高过了网站的设置阀值,将会被禁止访问。通常,网站的反爬虫机制都是依据IP来标识爬虫的。于是在爬虫的开发者通常需要采取两种手段来解决这个问题:
1、放慢抓取速度,减小对于目标网站造成的压力。但是这样会减少单位时间类的抓取量。
2、第二种方法是通过设置代理IP等手段,突破反爬虫机制继续高频率抓取。但是这样需要多个稳定的代理IP。
话不多书,直接上代码:
# IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)
运行结果截图:
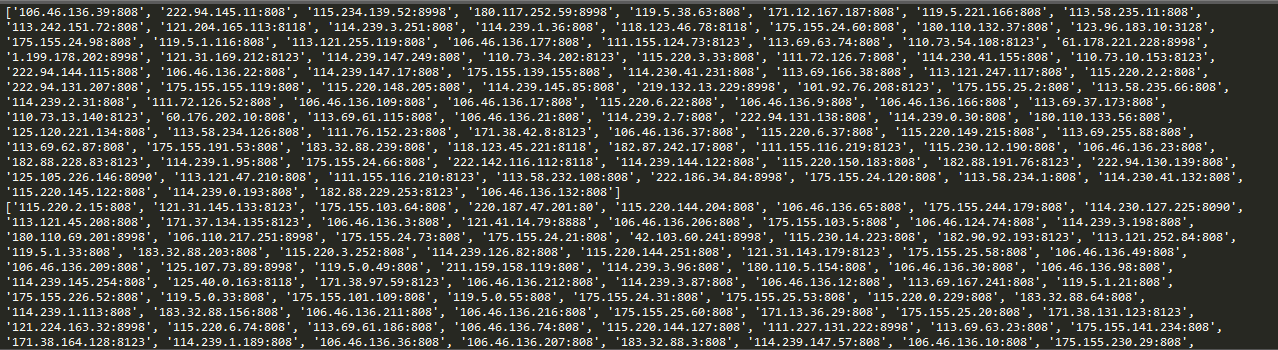
这样,在爬虫请求的时候,把请求ip设置为自动ip,就能有效的躲过反爬虫机制中简单的封锁固定ip这个手段。
-------------------------------------------------------------------------------------------------------------------------------------
为了网站的稳定,爬虫的速度大家还是控制下,毕竟站长也都不容易。本文测试只抓取了17页ip。
爬取软考试题系列之ip自动代理的更多相关文章
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- python爬虫学习(二):定向爬虫例子-->使用BeautifulSoup爬取"软科中国最好大学排名-生源质量排名2018",并把结果写进txt文件
在正式爬取之前,先做一个试验,看一下爬取的数据对象的类型是如何转换为列表的: 写一个html文档: x.html<html><head><title>This is ...
- pyhton 网络爬取软考题库保存text
#-*-coding:utf-8-*-#参考文档#https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-al ...
- scrapy版本爬取某网站,加入了ua池,ip池,不限速不封号,100个线程爬崩网站
目录 scrapy版本爬取妹子图 关键所在下载图片 前期准备 代理ip池 UserAgent池 middlewares中间件(破解反爬) settings配置 正题 爬虫 保存下载图片 scrapy版 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
- 利用Python爬取可用的代理IP
前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/.在使用的时候发现很多IP都用不了. 所以用Python写了个脚本,该脚本可以把能用的代理IP检测 ...
- 爬虫爬取代理IP池及代理IP的验证
最近项目内容需要引入代理IP去爬取内容. 为了项目持续运行,需要不断构造.维护.验证代理IP. 为了绕过服务端对IP 和 频率的限制,为了阻止服务端获取真正的主机IP. 一.服务器如何获取客户端IP ...
随机推荐
- ios NSString拼接方法总结
NSString* string; // 结果字符串 02 NSString* string1, string2; //已存在的字符串,需要将string1和string2连接起来 03 04 / ...
- JAVA_file(2)
几种不太安全的: 1. new File(path),这个方法的路径到底在那里取决于调用java命令的起始位置定义在哪里, tomcat/bin下面的catalina.bat调用了java,所以在to ...
- Swift 2.0 UIAlertView 和 UIActionSheet 的使用
在 IOS 9.0 之后, UIAlertView 是 给废弃了的,虽然你要使用的话,暂时还是可以的,但是在 9.0 之后,IOS 推荐大家使用的是 UIAlertController 这个控制器 ...
- 修改本地配置远程连接oracle数据库
当我们需要查看数据库信息时,我们更愿意通过客户端来查看,这样不仅操作方便,而且查看更精准.那么需要远程连接数据库需要在本地修改那些配置呢?以下是我个人的经验,希望大家都指正. 1.在oracle安装目 ...
- django源码简析——后台程序入口
这一年一直在用云笔记,平时记录一些tips或者问题很方便,所以也就不再用博客进行记录,还是想把最近学习到的一些东西和大家作以分享,也能够对自己做一个总结.工作中主要基于django框架,进行项目的开发 ...
- JVM内存
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack( ...
- Input file 文本框美化
HTML原生的input file 上传按钮有多(无)不(力)漂(吐)亮(槽)我就不多说了.大家几乎在项目中都会有遇到图片.等文件需要上传的地方,好看的文件上传按钮会使人身心愉悦(我瞎说的).好了不多 ...
- 【java基础之jdk源码】Object
最新在整体回归下java基础薄弱环节,以下为自己整理笔记,若有理解错误,请批评指正,谢谢. java.lang.Object为java所有类的基类,所以一般的类都可用重写或直接使用Object下方法, ...
- android学习3——长宽的单位问题dp,px,dpi
android设备的单位px,pt,dp,sp 分辨率 先通俗说下分辨率的概念.可以把屏幕想想成一个个正方形格子组成的.如果横向有1280个格子,竖向有720个格子.那么分辨率就是1280*720.这 ...
- js或者php浮点数运算产生多位小数的理解
<?php $f = 0.58; var_dump(intval($f * 100)); //为啥输出57 ?> 首先我们要知道浮点数的表示(IEEE 754): 浮点数, 以64位的长度 ...