浅谈HashMap的内部实现
权衡时空
HashMap是以键值对的方式存储数据的。
如果没有内存限制,那我直接用哈希Map的键作为数组的索引,取的时候直接按索引get就行了,可是地价那么贵,哪里有无限制的地盘呢。
如果没有时间限制的话,我可以把数据放到一个无序数组中,按顺序查找,迟早也能找到。可是time is money,光阴那么短暂,谁又等得起呢。
所以,HashMap做了个折中的策略,使用适当的时间和空间做出了权衡,具体可以归结为“链表散列法”,这是一个hash表处理冲突的经典方法。
链表散列
那么什么是”链表散列法”呢?看下图:
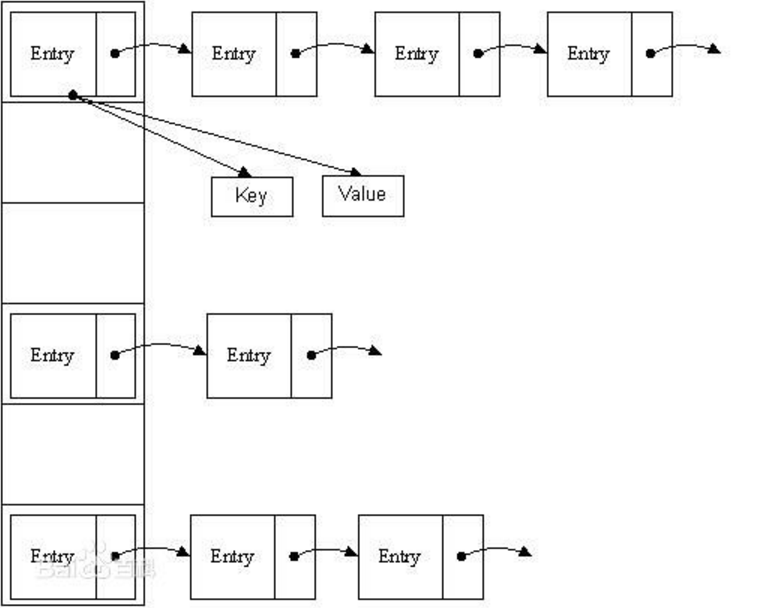
纵向的是一个数组,数组的每一项都是一个链表。你可以把这个数组看成是N个桶,每一个桶放着一个链子。
数组是干嘛的?数组的每一项负责放链表的。
链表是干嘛的?负责放Map数据的,比如一个HashMap有两个键,一个是key1,一个是key2。那么该链表就会分出两个节点分别存放这两个键值对(每一个键值对是打包放在Entry对象中的)。
链表是怎么链起来的?Entry包含有key、value、下一个节点next、hash值等,这个next就把各个节点串了起来。
HashMap保存数据的过程为:先计算当前要保存的键值对的哈希值(决定着当前键值对要放到哪个桶中),根据这个哈希值找到对应的桶。如果桶中没有数据,那就直接放进去。如果桶中已经放了数据(也即:桶中的链条上放着一个或者多个键值对),那就顺着桶中的这个链条一个一个比对,看有没有key与当前要保存的数据的key相同。如果有相同,直接覆盖原来key的value。如果没有相同的,那么将该元素保存在链头(最早保存的元素就会跑到链尾)。
装填因子
桶的数量决定了能放多少个HashMap,而具体用了多少个桶,则直接关系着查找的效率。打个比方,你去隔壁班找小明,班里有10个人,你很快就会找到小明,班里坐着100个人,你可能找半天才能找到。所以你去看HashMap的构造函数是这样的:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
三个构造函数都牵动着两个东西:initialCapacity,loadFactor。前者表示的是桶的初始数量(即数组大小),后者表示“装填因子”,装填因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。比如,数组初始大小为100,如果装填因子=0.6,表示当数组中存放了60个Map之后,就要把数组扩容后才能继续存放。这就是为了解决上面讲到的效率问题。
装填因子定的小了,查找数据就快些,但是浪费空间。装填因子大了,空间利用率就高,但是浪费时间。生活就是这样,顾此失彼在所难免,万事哪有两全的呢。系统权衡利弊后,默认给的装填因子是0.75,这个一般我们是不需要改动的。
除留余数
那么还有个问题。拿到一个Map的哈希值,怎么决定放到哪个桶里呢?如果最后数组中的Map数据都挤到一块儿那可不行,查询就会慢。太松了也不行,浪费空间。Java用了一招“除留余数法”,保证数据在数组中分布均匀。
“除留余数法”,就是取模。比如数组的长度是100,Map的哈希值是80,用80%100,余数是80,就放到80那个位置。但是Java可不是那样干算的呦,且看源码:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
上面代码就是HashMap中的添加Entry数据的方法。BucketIndex就是当前Map在数组中的索引。第三行扩容且不谈,重点在indexFor方法,这个方法就是”取模”。我们点进去看一下:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
H是Map的哈希值,length是数组的长度。它直接使用了一个h & (length - 1)。这一句其实就相当于对数组取模,但是直接用二进制的位操作,比数学计算要快的多。这也给了我们程序员一个启发,能用位运算时尽量用,提高逼格又提高效率。
均匀分布
还有个有趣的地方,上面代码的注释部分:length must be a non-zero power of 2,这句是说,数组的长度必须是2的n次方。
为啥是2的n次方呢?
如果不是2的n次方,比如length为15,h分别为2,3,4。那么用h & (length -1)有:
|
h |
Length-1 |
h & (length -1) |
|
0010 |
1110 |
0010,即2 |
|
0011 |
1110 |
0010,即2 |
|
0100 |
1110 |
0100,即4 |
你看,随便测了三个数字,就发生了碰撞。为什么会这样呢?
这是因为:如果不是2的n次方,那么2^n – 1的最低位必然为0,而0、1分别和0作“与”运算,结果都为0。也就是说,不论h为多少,h & (length - 1)的结果最低位都是0。那么数组中最低位为1的那些位置就全部空缺着,这就导致数据在数组中分布不均匀了,继而影响了查询的效率。
读取数据的时候就简单多了,通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。
参考资料:
http://www.cnblogs.com/chenssy/p/3521565.html
http://blog.csdn.net/zhuanshenweiliu/article/details/39177447
http://blog.csdn.net/tanggao1314/article/details/51457585#t1
http://www.importnew.com/18851.html
浅谈HashMap的内部实现的更多相关文章
- 浅谈SQL Server内部运行机制
对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说,逻辑的增删改查,或者较复杂的SQL语句,都是非常简单的,不存在任何挑战,不值得一提,那么,SQL的哪些方面是他们的挑战 或者软肋呢? 那就是 ...
- 浅谈HashMap原理,记录entrySet中的一些疑问
HashMap的底层的一些变量: transient Node<K,V>[] table; //存储数据的Node数组 transient Set<java.util.Map.Ent ...
- 浅谈HashMap与线程安全 (JDK1.8)
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型.HashMap 继承自 AbstractMap 是基于哈希表的 Map 接口的实现,以 Key-Value 的形式存在,即 ...
- Java重点之小白解析--浅谈HashMap与HashTable
这是一个面试经常遇到的知识点,无论什么公司这个知识点几乎是考小白必备,为什么呢?因为这玩意儿太特么常见了,常见到你写一百行代码,都能用到好几次,不问这个问哪个.so!本小白网罗天下HashMap与Ha ...
- 【JDK源码分析】浅谈HashMap的原理
这篇文章给出了这样的一道面试题: 在 HashMap 中存放的一系列键值对,其中键为某个我们自定义的类型.放入 HashMap 后,我们在外部把某一个 key 的属性进行更改,然后我们再用这个 key ...
- 浅谈HashMap的实现原理
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
- 浅谈 Nginx 的内部核心架构设计
一.前言 Nginx---Ngine X,是一款免费的.自由的.开源的.高性能HTTP服务器和反向代理服务器:也是一个IMAP.POP3.SMTP代理服务器:Nginx以其高性能.稳定性.丰富的功能. ...
- 【Java】浅谈HashMap
HashMap是常用的集合类,以Key-Value形式存储值.下面一起从代码层面理解它的实现. 构造方法 它有好几个构造方法,但几乎都是调此构造方法: public HashMap(int initi ...
- 浅谈HashMap 的底层原理
本文整理自漫画:什么是HashMap? -小灰的文章 .已获得作者授权. HashMap 是一个用于存储Key-Value 键值对的集合,每一个键值对也叫做Entry.这些个Entry 分散存储在一个 ...
随机推荐
- CodeForces 333A
Secrets Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Submit Sta ...
- easyui treegrid实现显示checkbox并能获取到选定值的
闲聊: 小颖最近忙疯了,经常被加班,昨天都要下班了,又提了个需求,虽然写的代码不多只有几行,可是测试环境很难跑通,一会就ie崩溃了,所以弄得小颖最近老是头晕. 也不知道最近是怎么了,一向特别爱吃的小颖 ...
- 《JAVASCRIPT高级程序设计》第五章(1)
引用类型是一种将数据和功能组合到一起的数据结构,它与类相似,但是是不同的概念:ECMAScript虽然是一门面向对象的语言,但它不具备传统的面向对象语言所支持的类和结构等基本结构.引用类型也被称为“对 ...
- Linux编程之从零开始搭建RPC分布式系统
我一毕业进公司就接触到了RPC,主要是使用前辈们搭建好的RPC框架以及封装好的RPC函数进行业务开发,虽说使用RPC框架开发已经近半年了,但一直想知道如何从零开始搭建起这么一个好用的分布式通信系统框架 ...
- 代码神器Atom,最常用的几大插件,你值得拥有。
作者:魔洁 atom常用插件 atom插件安装File>Settings>intall搜索框输入插件名,点击Packages搜索,搜索出来后点击intall安装,建议你先安装(simpli ...
- 论SNAPSHOT包的危害性
先介绍一下背景:我们应用是一个标准的spring+webx工程,博主在一次项目发布前为了再次测试一下自己的代码,将分支部署到日常环境中,但是项目启动的时候报错: 第一眼看到这个堆栈后有点懵逼 第一是上 ...
- mybatis入门-第一个程序
今天,我们就一起来完成mybatis的第一个小demo,使用mybatis对我们的数据库进行一个小小的操作. 需求 根据用户id查询用户的信息. 环境搭建 java环境:jdk1.7版本 开发工具:e ...
- table中td的宽度不随文字变宽
1.设置了table的宽度后,宽度仍然不固定,td的内容一多,很容易吧table撑变形.有些时候我们需要设置固定的宽度. 解决办法 table的css 加入样式 table-layout:fixed ...
- Node.js学习笔记(一)基础介绍
什么是Node.js 官网介绍: Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js us ...
- JavaScript中的this关键字的用法和注意点
JavaScript中的this关键字的用法和注意点 一.this关键字的用法 this一般用于指向对象(绑定对象); 01.在普通函数调用中,其内部的this指向全局对象(window); func ...