深度学习网络层之 Batch Normalization
Batch Normalization
Ioffe 和 Szegedy 在2015年《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》论文中提出此方法来减缓网络参数初始化的难处.
Batch Norm优点
- 减轻过拟合
- 改善梯度传播(权重不会过高或过低)
- 容许较高的学习率,能够提高训练速度。
- 减轻对初始化权重的强依赖
- 作为一种正则化的方式,在某种程度上减少对dropout的使用。
Batch Norm层摆放位置
在激活层(如 ReLU )之前还是之后,没有一个统一的定论。在原论文中提出在非线性层之前(CONV_BN_RELU),而在实际编程中很多人可能放在激活层之后(BN_CONV_RELU)。
Batch Norm原理
内部协转移(Internal Covariate Shift):由于训练时网络参数的改变导致的网络层输出结果分布的不同。这正是导致网络训练困难的原因。
对输如进行白化(whiten:0均值,单位标准差,并且decorrelate去相关)已被证明能够加速收敛速度,参考Efficient backprop. (LeCun et al.1998b)和 A convergence anal-ysis of log-linear training.(Wiesler & Ney,2011)。由于白化中去除相关性类似PCA等操作,在特征维度较高时计算复杂度较高,因此提出了两种简化方式:1)对特征的每个维度进行归一化,忽略白化中的去除相关性 ;2)在每个mini-batch中计算均值和方差来替代整体训练集的计算.
batch normalization中即使不对每层的输入进行去相关,也能加速收敛。通俗的理解是在网络的每一层的输入都做了归一化预处理。
unit gaussian activations:
\[
\hat x^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{\operatorname{Var[x^{(k)}]}}}
\]
公式中k为通道channel数。
\[
\text{Batch Normalizing Transform} \\
\begin{align}
u &= \frac{1}{m}\sum_{i=1}^m x_i &\text{//mini-batch mean} \\
var &= \frac{1}{m} \sum_{i=1}^m (x_i - u)^2 &\text{//mini-batch variance} \\
\hat{x_i} &= \frac{x_i - u}{\sqrt{var + \epsilon}} &\text{//normalize} \\
y_i &= \gamma \hat{x_i} + \beta &\text{//scale and shift}
\end{align}
\]
其中ϵ是为了防止方差为0导致数值计算的不稳定而添加的一个小数,如1e−6。可以看做是在原网络中插入了一个
注意,在对每层的输入进行正则化之后会改变特征的表示,如对sigmoid输入进行正则化后将数据限制在进行线性的区域,这样改变了原始特征的分布。如下图所示:
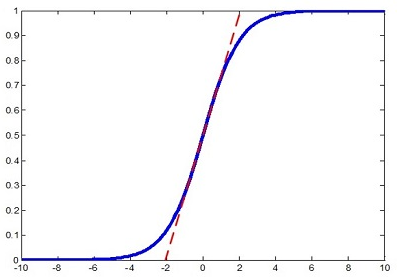
论文中引入了两个可学习的参数\(\gamma , \beta\)来还原原始特征分布。这两个参数学习的目标即为\(\gamma=\sqrt{\text{Var}[x]}、 \beta=\mathbb E[x]\).原来的分布方差和均值由前层的各种参数weight耦合控制,而现在仅由\(\gamma , \beta\)控制,这样在保留BN层足够的学习能力的同时,我们使得其学习更加容易。因此,加速收敛并非由于计算量减少(反而由于增加了参数增加了计算量)。梯度计算如下:

在训练时计算mini-batch的均值和标准差并进行反向传播训练,而测试时并没有batch的概念,训练完毕后需要提供固定的\(\bar\mu,\bar\sigma\)供测试时使用。论文中对所有的mini-batch的\(\mu_\mathcal B,\sigma^2_\mathcal B\)取了均值(m是mini-batch的大小,\(\bar\sigma^2\)采用的是无偏估计):
\[
\begin{align}
\bar\mu &=\mathbb E[\mu_\mathcal B] \\
\bar\sigma^2 &={m\over m-1}\mathbb E[\sigma^2_\mathcal B]
\end{align}
\]
测试阶段,同样要进行归一化和缩放平移操作,唯一不同之处是不计算均值和方差,而使用训练阶段记录下来的\(\bar\mu,\bar\sigma\)。
\[
\begin{align}
y&=γ({x-\bar\mu\over\sqrt{\bar\sigma^2+ϵ}})+ β \\
&={γ\over\sqrt{\bar\sigma^2+ϵ}}\cdot x+(β-{γ\bar\mu\over\sqrt{\bar\sigma^2+ϵ}})
\end{align}
\]
caffe框架中该层全局均值和方差的实现
与论文计算 global 均值和 global 方差的方式不同之处在于,Caffe 中的 global 均值和 global 方差采用的是滑动衰减平均的更新方式,设滑动衰减系数moving_average_fraction 为 λ,当前的 mini-batch 的均值和方差分别为 \(\mu_B,\sigma_B^2\):
\[
\mu_{new} = \lambda \mu_{old} + \mu_B \\
\sigma_{new}^2 =
\begin{cases}
\lambda \sigma_{old}^2 + \frac{m - 1}{m} \sigma_B^2 & m > 1 \\
\lambda \sigma_{old}^2 & m = 1
\end{cases}
\]
Batch Norm在卷积层的应用
前边提到的mini-batch说的是神经元的个数,而卷积层中是堆叠的多个特征图,共享卷积参数。如果每个神经元使用一对\(\gamma , \beta\)参数,那么不仅多,而且冗余。可以在channel方向上取m个特征图作为mini-batch,对每一个特征图计算一对参数。这样减少了参数的数量。
应用举例-VGG16
为VGG16结构模型添加Batch Normalization。
- 重新完全训练.如果想将BN添加到卷基层,通常要重新训练整个模型,大概花费一周时间。
- finetune.只将BN添加到最后的几层全连接层,这样可以在训练好的VGG16模型上进行微调。采用ImageNet的全部或部分数据按batch计算均值和方差作为BN的初始\(\beta,\gamma\)参数。
深度学习网络层之 Batch Normalization的更多相关文章
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- 深度学习中的batch、epoch、iteration的含义
深度学习的优化算法,说白了就是梯度下降.每次的参数更新有两种方式. 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度.这种方法每更新一次参数都要把数据集里的所有样本都看一遍, ...
- 深度学习中的batch的大小对学习效果的影响
Batch_size参数的作用:决定了下降的方向 极端一: batch_size为全数据集(Full Batch Learning): 好处: 1.由全数据集确定的方向能够更好地代表样本总体,从而更准 ...
- 深度学习网络层之 Pooling
pooling 是仿照人的视觉系统进行降维(降采样),用更高层的抽象表示图像特征,这一部分内容从Hubel&wiesel视觉神经研究到Fukushima提出,再到LeCun的LeNet5首次采 ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- 【深度学习】批归一化(Batch Normalization)
BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中"梯度弥散"的问题,从而使得训练深层网 ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
随机推荐
- java web轻量级开发面试教程读书笔记:建索引时我们需要权衡的因素
场景一,数据表规模不大,就几千行,即使不建索引,查询语句的返回时间也不长,这时建索引的意义就不大.当然,若就几千行,索引所占的空间也不多,所以这种情况下,顶多属于"性价比"不高. ...
- HTML5无插件多媒体Media——音频audio与视频video
文件日志地址 http://blog.csdn.net/q1056843325/article/details/60336226 音频与视频现在已经变得越来越流行 各个网站为了保证跨浏览器的兼容性 ...
- Go 到底有没有引用传参(对比 C++ )
Go 到底有没有引用传参(对比 C++ ) C++ 中三种参数传递方式 值传递: 最常见的一种传参方式,函数的形参是实参的拷贝,函数中改变形参不会影响到函数外部的形参.一般是函数内部修改参数而又不希望 ...
- batの磕磕碰碰
前两天用kettle和存储过程实现了两个划小接口,然后用bat调用它们,在自己的xp系统上测试完全通过,没有任何问题. 然后很开心滴把成果打包给北京的同事他们使用.第二天他们跟我说无法取数,我马上就流 ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- Go数组、切片、映射的原理--简明解析
数组.切片.映射是Golang的最重要的数据结构,下面是对这3种数据结构的一点个人总结: 一.数组 数组是切片和映射的基础数据结构. 数组是一个长度固定的数据类型,存储着一段具有相同数据类型元素的连续 ...
- 【小白成长撸】--多项式求圆周率PI
/*程序的版权和版本声明部分: *Copyright(c) 2016,电子科技大学本科生 *All rights reserved. *文件名:多项式求PI *程序作用:计算圆周率PI *作者:Amo ...
- 一种解决url的get请求参数传值乱码问题的方式
做项目的时候发现url get请求传中文字符出现乱码问题,百度了一下,最后用一种比较容易理解的方式解决了.分享给大家! 经过百度,网友提到:url get方式提交的参数编码,只支持iso8859-1编 ...
- # 团队作业8——第二次项目冲刺(Beta阶段)--5.27 seventh day
团队作业8--第二次项目冲刺(Beta阶段)--5.27 seventh day Day six: 会议照片 项目进展 Beta冲刺的最后一天,以下是今天具体任务安排: 队员 昨天已完成的任务 今日计 ...
- 201521123091 《Java程序设计》第11周学习总结
Java 第十一周总结 第十一周的作业. 目录 1.本章学习总结 2.Java Q&A 3.码云上代码提交记录及PTA实验总结 4.课后阅读 1.本章学习总结 1.1 以你喜欢的方式(思维导图 ...