深度学习中优化【Normalization】
深度学习中优化操作:
- dropout
- l1, l2正则化
- momentum
- normalization
1、为什么Normalization?
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
对于每一层网络得到输出向量的分布是不太有规律的,将这些没有规律的的输出结果放入激励层,会使得许多样本?因为偏离0坐标太远,而使得这些样本的值很大(等于1)或者很小(等于0),从而导致在反向传播时梯度消失。
我们在训练的时候希望每个batch在同一层网络下的输出结果是独立同分布的,这样能网络的泛化性就会比较强。
2、方式
1.Batch Normalization
BN的做法很简单,就是在输出结果在送到激励层之前,对输出结果做一次标准化。

前三步分别就是求均值与方差,并对其进行中心化,normalize中分母中的$\epsilon$,是为了避免除以0溢出。经过这三步,输出结果已经变成均值为$\mu _{b}$, 方差是$\sigma^{2}_{b}$的分布了。
最后一步非常重要。γ和β是可学习的,目的是让网络能够自己调节分布。我们获得一个关于y轴对称的分布真的是最符合神经网络训练的吗?没有任何理由能证明这点。事实上,γ和β为输出的线性调整参数,可以让分布曲线压缩或延长一点,左移或右移一点。由于γ和β是可训练的,那么意味着神经网络会随着训练过程自己挑选一个最适合的分布。如果我们固执地不用γ和β会怎么样呢?那势必会把压力转移到特征提取层,虽然最后结果依然可观,但训练压力会很大。你想想,一边只需要训练两个数,另一边需要训练特征提取层来符合最优分布就是关于y轴的对称曲线。前者自然训练成本更低。
---------------------
作者:木盏
来源:CSDN
原文:https://blog.csdn.net/leviopku/article/details/83109422
版权声明:本文为博主原创文章,转载请附上博文链接!
反向传播:https://kevinzakka.github.io/2016/09/14/batch_normalization/

在反向传播过程中,$\frac{\partial L}{\partial \boldsymbol{y}}$由上一步已经算出,是已知条件。
先求:$\frac{\partial f}{\partial \gamma }, \frac{\partial f}{\partial \hat{x_{i}}},\frac{\partial f}{\partial \beta } $
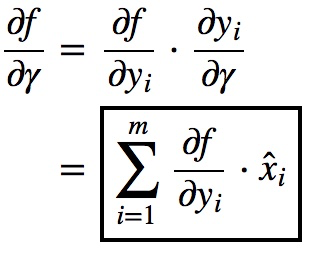
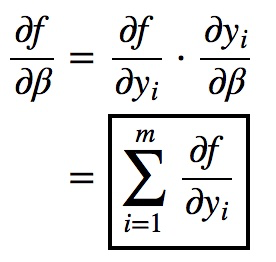
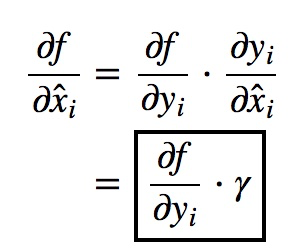
再根据 x标准化,求$\frac{\partial f}{\partial \mu }, \frac{\partial f}{\partial \sigma ^{2}},\frac{\partial f}{\partial x_{i} } $
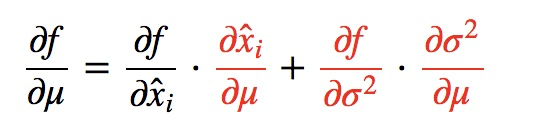
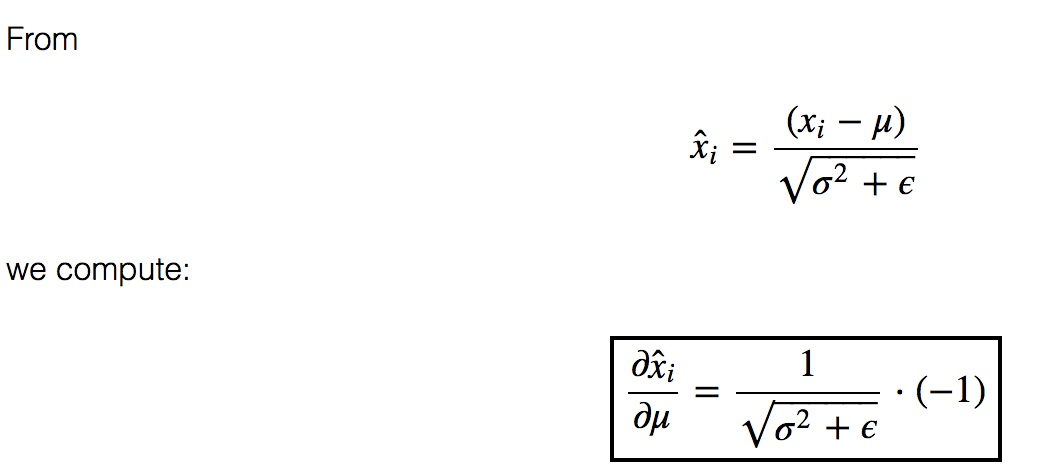

$\frac{\partial f}{\partial \mu} = \sum_{i = 1}^{m} \frac{\partial f}{\partial \hat{x}_{i}} \frac{\partial \hat{x}_{i}}{\partial \mu} + \frac{\partial f}{\partial \sigma^{2} } \frac{\partial \sigma^{2}}{\partial \mu}$
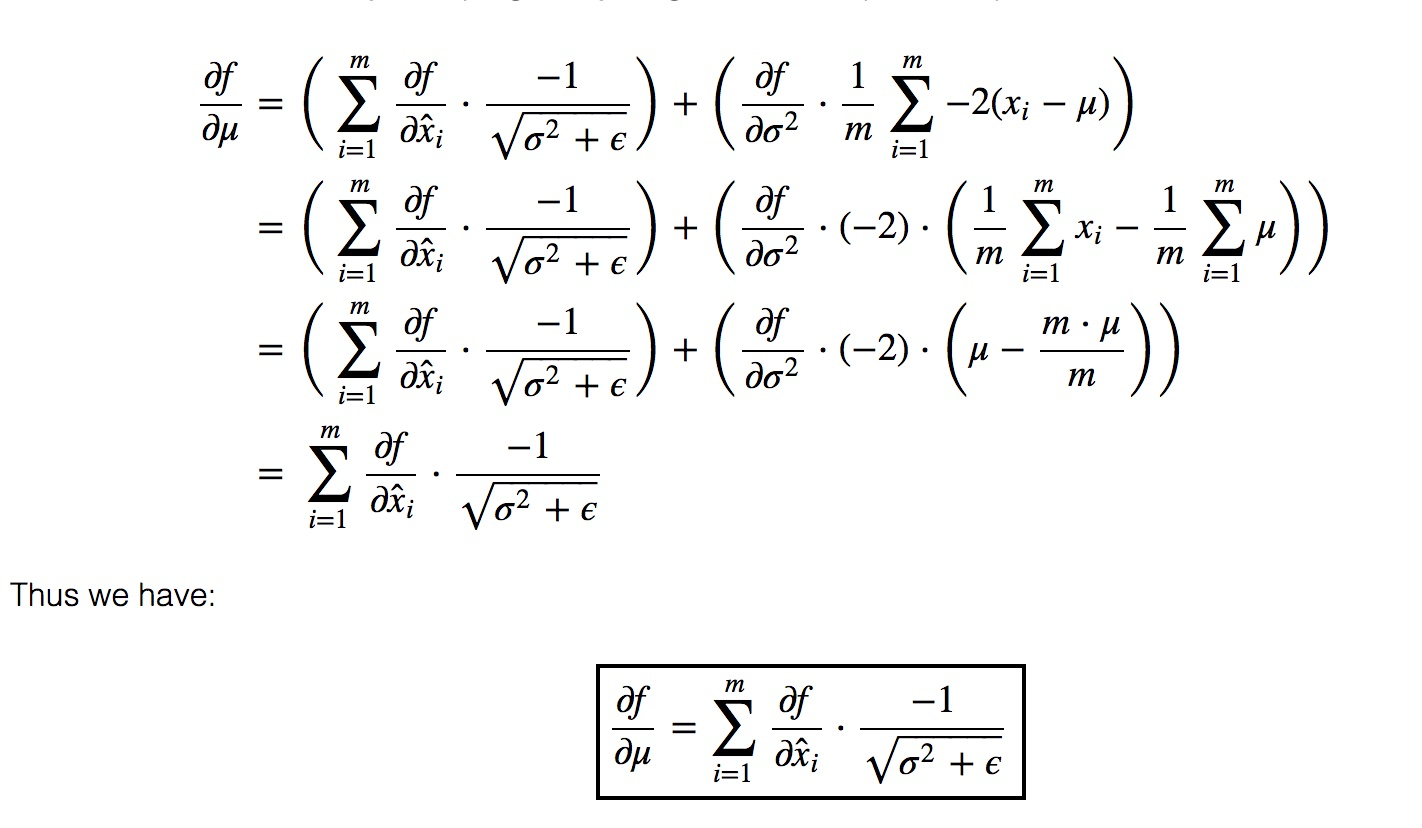

缺点:
1.对batchsize大小比较敏感,如果batchsize太不小计算的均值和方差不足以代表整体的数据分布
2.在RNN领域效果不是很好。为什么
BN是以每一个batch为基准进行计算的,也就是 μ.shape = (1, D), var.shape = (1, D),对于RNN来说,每一个batch中的数据可能不是等长的,即使padding后变成等长,然后在normalize就会引入噪声(padding)
2、Layer Normalization
LN不以batch为单位,而是以一个样本为单位。
u.shape = (N, 1)
var.shape = (N, 1)
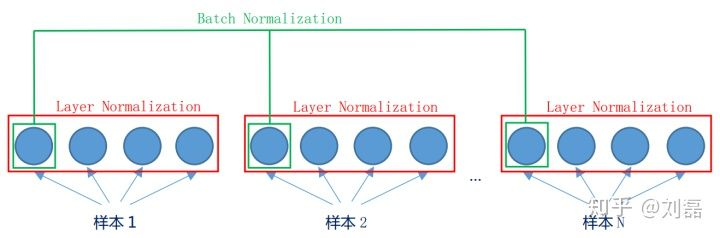
反向传播:
python实现:
tf接口
参考:
http://www.dataguru.cn/article-13031-1.html
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://blog.csdn.net/leviopku/article/details/83109422
深度学习中优化【Normalization】的更多相关文章
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作.效果还不错,至少对于训练速度提升了很多. batch normalization的做法是把数据转换为0 ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- L19深度学习中的优化问题和凸性介绍
优化与深度学习 优化与估计 尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同. 优化方法目标:训练集损失函数值 深度学习目标:测试集损失函数值(泛化性) ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
随机推荐
- 部署 apply plugin: 'realm-android'
我在build.gradle中添加 apply plugin: 'realm-android' //依赖Realm数据库,插件化依赖 这个后,同步,清理,运行的时候报 应该在build.gradle ...
- spring boot整合Hadoop
最近需要用spring boot + mybatis整合hadoop,其中也有碰到一些坑,记录下来方便后面的人少走些弯路. 背景呢是因为需要在 web 中上传文件到 hdfs ,所以需要在spring ...
- LNMP环境下部署搭建wordpress
1. 下载WordPress安装包 访问官方网站https://cn.wordpress.org/ 点击Download.tar.gz下载linux平台安装包 2. 安装软件 2.1.上传安装包 使用 ...
- iis问题
1.8.5版本的iis配置完成,不能打开网页显示503.原因是应用程序池,加载用户配置文件失败,然后应用程序池关闭了.关闭它就可以正常打开了. server2008,打不开网页,打开url显示目录的原 ...
- 移动端和PC端弹出遮罩层后,页面禁止滚动的解决方法及探究
PC端解决方案 pc端的解决思路就是在弹出遮罩层的时候取消已经存在的滚动条,达到无法滚动的效果. 也就是说给body添加overflow:hidden属性即可,IE6.7下不会生效,需要给html增加 ...
- 利用Sonar定制自定义扫描规则
上有3种方法可以自定义soanr的代码校验规则: 直接在sonar的web接口中增加XPath规则: 通过插件的功能来增加自定义规则,比如checkstyle,pmd等插件是允许自定义规则的: 通 ...
- Core官方DI解析(3)-ServiceCallSite.md
上一篇说过在整个DI框架中IServiceProviderEngine是核心,但是如果直接看IServiceProviderEngine派生类其实看不出也没什么东西,因为这个类型其实都是调用的其它对象 ...
- windows系统中给qt工程添加第三方库
· TEMPLATE = app CONFIG += console c++11 CONFIG -= app_bundle CONFIG -= qt SOURCES += main.cpp LIBS ...
- scala的多种集合的使用(7)之集Set的操作方法
1.给集添加元素 1)用+=.++=和add给可变集添加元素. scala> var set = scala.collection.mutable.Set[Int]() set: scala.c ...
- C#关于TreeView树在节点数较多时总是会出现闪烁的问题方法记录
首先介绍下背景吧,问题如题,这个问题应该说困扰我大半年了(不是说我没有请教大佬,不是说我没有上网查过,之前在搜索时,总是没有解决此问题~~),直到最近一次在在优化代码时,再次上网查找,在发现搜索词条” ...