day31-软件开发规范
一、为什么要规范软件开发?
1.1 为什么要有规范软件开发
之前写的一些程序,所谓的'项目',都是在一个py文件下完成的,代码量也就几百行,没有太大问题。但是真正的后端开发的项目,少则几万行代码,多则十几万,几十万行代码,就不能全都放在一个py文件中了。
软件开发,规范项目目录结构,代码规范,遵循PEP8规范等等,让代码结构更清晰。
软件开发的首要规范就是从设计目录结构开始。
1.2 为什么要设计项目目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱。
所以,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
二、较好的目录结构方式(推荐)
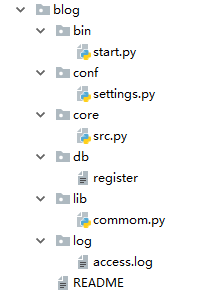
具体分析:
#===============>start.py
# 开启项目的start文件。
import sys
import os
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BASE_PATH)
from core import src if __name__ == '__main__':
src.run() #===============>settings.py
# 配置文件,放一些路径或者信息等配置
import os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DB_PATH=os.path.join(BASE_DIR,'db','db.json')
LOG_PATH=os.path.join(BASE_DIR,'log','access.log')
LOGIN_TIMEOUT=5 或
DB_PATH = r'..\db\register.py'
LOG_PATH = r'..\log\access.log' """
logging配置
"""
# 定义三种日志输出格式
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': LOG_PATH, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
} #===============>src.py
# 主要逻辑部分:
# 核心逻辑,代码放在这。
from conf import settings
from lib import common
import time logger=common.get_logger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.LOGIN_TIMEOUT)}
def auth(func):
def wrapper(*args,**kwargs):
if current_user['user']:
interval=time.time()-current_user['login_time']
if interval < current_user['timeout']:
return func(*args,**kwargs)
name = input('name>>: ')
password = input('password>>: ')
db=common.conn_db()
if db.get(name):
if password == db.get(name).get('password'):
logger.info('登录成功')
current_user['user']=name
current_user['login_time']=time.time()
return func(*args,**kwargs)
else:
logger.error('用户名不存在') return wrapper @auth
def buy():
print('buy...') @auth
def run(): print('''
购物
查看余额
转账
''')
while True:
choice = input('>>: ').strip()
if not choice:continue
if choice == '':
buy() #===============>db.json
# 重要数据放在这里 #===============>common.py
# 公共组件放在这里:公共功能部分。
from conf import settings
import logging
import logging.config
import json def get_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(name) # 生成一个log实例
return logger def conn_db():
db_path=settings.DB_PATH
dic=json.load(open(db_path,'r',encoding='utf-8'))
return dic #===============>access.log
# 日志信息
[2017-10-21 19:08:20,285][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:08:32,206][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:08:37,166][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:39,535][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:40,797][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:08:47,093][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:09:01,997][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:09:05,781][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]
[2017-10-21 19:09:29,878][MainThread:8812][task_id:core.src][src.py:19][INFO][登录成功]
[2017-10-21 19:09:54,117][MainThread:9884][task_id:core.src][src.py:19][INFO][登录成功]
关于README的内容
每个项目都应该有的一个readme文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
1、软件定位,软件的基本功能。
2、运行代码的方法: 安装环境、启动命令等。
3、简要的使用说明。
4、代码目录结构说明,更详细点可以说明软件的基本原理。
5、常见问题说明。
有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
day31-软件开发规范的更多相关文章
- Python模块的导入以及软件开发规范
Python文件的两种用途 1 . 当脚本直接使用,直接当脚本运行调用即可 def func(): print("from func1") func() 2 . 当做模块被导入使用 ...
- python 全栈开发,Day29(昨日作业讲解,模块搜索路径,编译python文件,包以及包的import和from,软件开发规范)
一.昨日作业讲解 先来回顾一下昨日的内容 1.os模块 和操作系统交互 工作目录 文件夹 文件 操作系统命令 路径相关的 2.模块 最本质的区别 import会创建一个专属于模块的名字, 所有导入模块 ...
- Python 3 软件开发规范
Python 3 软件开发规范 参考链接 http://www.cnblogs.com/linhaifeng/articles/6379069.html#_label14 对每个目录,文件介绍. #= ...
- python(37)- 软件开发规范
软件开发规范 一.为什么要设计好目录结构? 1.可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等.从而非常快速的了解这个项目. 2 ...
- python27期day16:序列化、json、pickle、hashlib、collections、软件开发规范、作业。
序列化模块:什么是序列化呢? 序列化的本质就是将一种数据结构(如字典.列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化.将这个字典直接写入文件是不可以的,必须转化成字符串的形式, ...
- Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型)
Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型) 一丶软件开发规范 六个目录: #### 对某 ...
- Python 入门之 软件开发规范
Python 入门之 软件开发规范 1.软件开发规范 -- 分文件 (1)为什么使用软件开发规范: 当几百行--大几万行代码存在于一个py文件中时存在的问题: 不便于管理 修改 可读性差 加载速度慢 ...
- python软件开发规范&分文件对于后期代码的高效管理
根据本人的学习,按照理解整理和补充了python模块的相关知识,希望对于一些需要了解的python爱好者有帮助! 一.软件开发规范--分文件 当代码存在一个py文件中时: 1.不便于管理 (修改,增加 ...
- python中软件开发规范,模块,序列化随笔
1.软件开发规范 首先: 当代码都存放在一个py文件中时会导致 1.不便于管理,修改,增加 2.可读性差 3.加载速度慢 划分文件1.启动文件(启动接口)--starts文件放bin文件里2.公共文件 ...
- Python_Day5_迭代器、装饰器、软件开发规范
本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 1.列表生成式,迭代器&生成器 列表生成 >>> a = [i+1 ...
随机推荐
- PAT 乙级 1031 查验身份证(15) C++版
1031. 查验身份证(15) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 一个合法的身份证号码由17位地区. ...
- [Chrome]点击页面元素后全屏
function isFullScreen() { return (document.fullScreenElement && document.fullScreenElement ! ...
- C语言强化——文件
文件操作 fopen与fclose fread与fwrite fseek fputs与fgets fscanf与fprintf fopen与fclose #include<stdio.h> ...
- python容器数据类型的特色
python容器数据类型的特色 list: 可变数据类型(不可哈希), 有序, 可索引获取, 可修改 Dict: 可变数据类型(不可哈希), 3.6版本有序, 可通 ...
- java正则表达式替换空格和换行符
public class StringUtil { public static String getStringNoBlank(String str) { if(s ...
- jmater分布式压力测试总结
总结,总是为了方便以后 1.jmeter 2000个并发,4台slave ,每台slave是500个线程即可完成测试 2.jmx文件只需要拷贝到master下 jmeter目录下(最保险的方法) 3. ...
- Missing artifact javax.transaction:jta:jar:1.0.1B
下载https://pan.baidu.com/s/1hsfyj8S到某目录,比如: /Users/yintingting/Downloads 打开terminal,cd /Users/yinting ...
- ES6学习笔记<五> Module的操作——import、export、as
import export 这两个家伙对应的就是es6自己的 module功能. 我们之前写的Javascript一直都没有模块化的体系,无法将一个庞大的js工程拆分成一个个功能相对独立但相互依赖的小 ...
- Linux终端小技巧
注释:以下都是自己遇到的问题,问题太多也记不住,每次上网查找又比较麻烦,索性记录一下随笔! 1.进程的挂载与运行 暂停运行一个进程:Ctrl+Z 其中这个进程可再被操作,如:后台运行.再次运行等 ...
- concurrent.futures模块 -----进程池 ---线程池 ---回调
concurrent.futures模块提供了高度封装的异步调用接口,它内部有关的两个池 ThreadPoolExecutor:线程池,提供异步调用,其基础就是老版的Pool ProcessPoolE ...