java 读写Parquet格式的数据 Parquet example
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Random; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.Logger;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.GroupFactory;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.ParquetReader.Builder;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.example.GroupReadSupport;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.MessageTypeParser; public class ReadParquet {
static Logger logger=Logger.getLogger(ReadParquet.class);
public static void main(String[] args) throws Exception { // parquetWriter("test\\parquet-out2","input.txt");
parquetReaderV2("test\\parquet-out2");
} static void parquetReaderV2(String inPath) throws Exception{
GroupReadSupport readSupport = new GroupReadSupport();
Builder<Group> reader= ParquetReader.builder(readSupport, new Path(inPath));
ParquetReader<Group> build=reader.build();
Group line=null;
while((line=build.read())!=null){
Group time= line.getGroup("time", 0);
//通过下标和字段名称都可以获取
/*System.out.println(line.getString(0, 0)+"\t"+
line.getString(1, 0)+"\t"+
time.getInteger(0, 0)+"\t"+
time.getString(1, 0)+"\t");*/
System.out.println(line.getString("city", 0)+"\t"+
line.getString("ip", 0)+"\t"+
time.getInteger("ttl", 0)+"\t"+
time.getString("ttl2", 0)+"\t");
//System.out.println(line.toString());
}
System.out.println("读取结束");
}
//新版本中new ParquetReader()所有构造方法好像都弃用了,用上面的builder去构造对象
static void parquetReader(String inPath) throws Exception{
GroupReadSupport readSupport = new GroupReadSupport();
ParquetReader<Group> reader = new ParquetReader<Group>(new Path(inPath),readSupport);
Group line=null;
while((line=reader.read())!=null){
System.out.println(line.toString());
}
System.out.println("读取结束");
}
/**
*
* @param outPath 输出Parquet格式
* @param inPath 输入普通文本文件
* @throws IOException
*/
static void parquetWriter(String outPath,String inPath) throws IOException{
MessageType schema = MessageTypeParser.parseMessageType("message Pair {\n" +
" required binary city (UTF8);\n" +
" required binary ip (UTF8);\n" +
" repeated group time {\n"+
" required int32 ttl;\n"+
" required binary ttl2;\n"+
"}\n"+
"}");
GroupFactory factory = new SimpleGroupFactory(schema);
Path path = new Path(outPath);
Configuration configuration = new Configuration();
GroupWriteSupport writeSupport = new GroupWriteSupport();
writeSupport.setSchema(schema,configuration);
ParquetWriter<Group> writer = new ParquetWriter<Group>(path,configuration,writeSupport);
//把本地文件读取进去,用来生成parquet格式文件
BufferedReader br =new BufferedReader(new FileReader(new File(inPath)));
String line="";
Random r=new Random();
while((line=br.readLine())!=null){
String[] strs=line.split("\\s+");
if(strs.length==2) {
Group group = factory.newGroup()
.append("city",strs[0])
.append("ip",strs[1]);
Group tmpG =group.addGroup("time");
tmpG.append("ttl", r.nextInt(9)+1);
tmpG.append("ttl2", r.nextInt(9)+"_a");
writer.write(group);
}
}
System.out.println("write end");
writer.close();
}
}
说下schema(写Parquet格式数据需要schema,读取的话"自动识别"了schema)
/*
* 每一个字段有三个属性:重复数、数据类型和字段名,重复数可以是以下三种:
* required(出现1次)
* repeated(出现0次或多次)
* optional(出现0次或1次)
* 每一个字段的数据类型可以分成两种:
* group(复杂类型)
* primitive(基本类型)
* 数据类型有
* INT64, INT32, BOOLEAN, BINARY, FLOAT, DOUBLE, INT96, FIXED_LEN_BYTE_ARRAY
*/
这个repeated和required 不光是次数上的区别,序列化后生成的数据类型也不同,
比如repeqted修饰 ttl2 打印出来为 WrappedArray([7,7_a])
而 required修饰 ttl2 打印出来为 [7,7_a]
除了用MessageTypeParser.parseMessageType类生成MessageType 还可以用下面方法
(注意这里有个坑--spark里会有这个问题--ttl2这里 as(OriginalType.UTF8) 和 required binary city (UTF8)作用一样,加上UTF8,在读取的时候可以转为StringType,不加的话会报错 [B cannot be cast to java.lang.String )
/*MessageType schema = MessageTypeParser.parseMessageType("message Pair {\n" +
" required binary city (UTF8);\n" +
" required binary ip (UTF8);\n" +
"repeated group time {\n"+
"required int32 ttl;\n"+
"required binary ttl2;\n"+
"}\n"+
"}");*/
//import org.apache.parquet.schema.Types;
MessageType schema = Types.buildMessage()
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city")
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip")
.repeatedGroup().required(PrimitiveTypeName.INT32).named("ttl")
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ttl2")
.named("time")
.named("Pair");
解决 [B cannot be cast to java.lang.String 异常:
1.要么生成parquet文件的时候加个UTF8
2.要么读取的时候再提供一个同样的schema类指定该字段类型,比如下面:
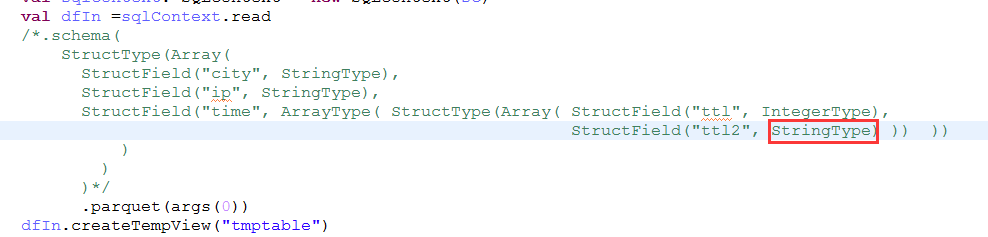
hadoop Mapreducer读写 Parquetexample
http://www.cnblogs.com/yanghaolie/p/7389543.html
maven依赖(我用的1.7)
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.7.0</version>
</dependency>
java 读写Parquet格式的数据 Parquet example的更多相关文章
- Android读写JSON格式的数据之JsonWriter和JsonReader
近期的好几个月都没有搞Android编程了,逐渐的都忘却了一些东西.近期打算找一份Android的工作,要继续拾起曾经的东西.公司月初搬家之后就一直没有网络,直到今日公司才有网络接入,各部门才開始办公 ...
- pandas(六)读写文本格式的数据
pandas提供的将表格型数据读取为DataFrame对象的函数. 函数 说明 read_csv 从文件.URL.文件型对象中加载带分隔符的数据.默认分隔符为逗号. read_table 从文件.UR ...
- JAVA 读取xml格式的数据
<?xml version="1.0" encoding="UTF-8"?> <column-enums> <type name= ...
- pandas 读写 Excel 格式的数据
import pandas as pd #读入数据: df = pd.read_excel('data_in.xlsx') #导出数据: writer = pd.ExcelWriter('data_o ...
- java 返回json格式的数据
1 阿里巴巴的fastjson import com.alibaba.fastjson.JSON; 使用的时候 JSON.toJSON(list); 2 Gson 解析json数据 import c ...
- learning java 读写其他进程的数据
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; public ...
- mapreduce 读写Parquet格式数据 Demo
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs ...
- Hive 导入 parquet 格式数据
Hive 导入 parquet 数据步骤如下: 查看 parquet 文件的格式 构造建表语句 倒入数据 一.查看 parquet 内容和结构 下载地址 社区工具 GitHub 地址 命令 查看结构: ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
随机推荐
- guava(一)Preconditions
工具类 就是封装平常用的方法,不需要你重复造轮子,节省开发人员时间,提高工作效率.谷歌作为大公司,当然会从日常的工作中提取中很多高效率的方法出来.所以就诞生了guava.. 高效设计良好的API,被G ...
- Task和async/await详解
一.什么是异步 同步和异步主要用于修饰方法.当一个方法被调用时,调用者需要等待该方法执行完毕并返回才能继续执行,我们称这个方法是同步方法:当一个方法被调用时立即返回,并获取一个线程执行该方法内部的业务 ...
- rust下根据protobuf的消息名创建对象实例
在C++里面, 我们可以根据一个消息的名称, 动态的创建一个实例 google::protobuf::Descriptor* desc = google::protobuf::DescriptorPo ...
- fiddler抓包-5-Composer功能进行接口测试
前言 fiddler是个强大的抓接口工具,轻松看出接口的所有参数,这里介绍一个Composer功能它也可以进行接口测试,平时接口可能传参错误,我们可以拖拽接口来改参数直接再请求了,非常方便! 一.Co ...
- 虚拟机安装CentOS 7
- protobuf 中import 的使用
目录结构如下: test.proto的文件内容如下: syntax="proto2"; package com.eagle.mohrss; option java_outer_cl ...
- WebRTC之框架与接口
出处:http://www.cnblogs.com/fangkm/p/4370492.html 上一篇文章简单地介绍了下WebRTC的协议流程,这一篇就开始介绍框架与接口. 一提到框架,本能地不知道从 ...
- fancybit个人简介
程序员一枚 熟悉C C++ C# js lua等多种常见开发语言 熟悉Unity游戏开发 node.js pomelo和C# scut 网游后端框架 做过.net和php网站后端 二次元文化爱好者 有 ...
- 整理:C#常用字符串操作,常用数值类型转换
一.字符串操作 1. 字符串连接 //将指定的数组所有元素拼接为一个字符串 string[] arr = {"A","B","C"}; st ...
- Haskell路线
@ 知乎 @ <I wish i have learned haskell> ———— 包括: Ranks, forall, Monad/CPS, monadic parser, FFI ...