python爬虫2
学习任务
获取去哪儿网的出发地列表
获取旅游景点列表
获取景点产品列表
存储数据
1 获取出发地站点
(1)访问touch.qunar.com
(2)按F12,单击自由行,在自由行页面点击搜索框


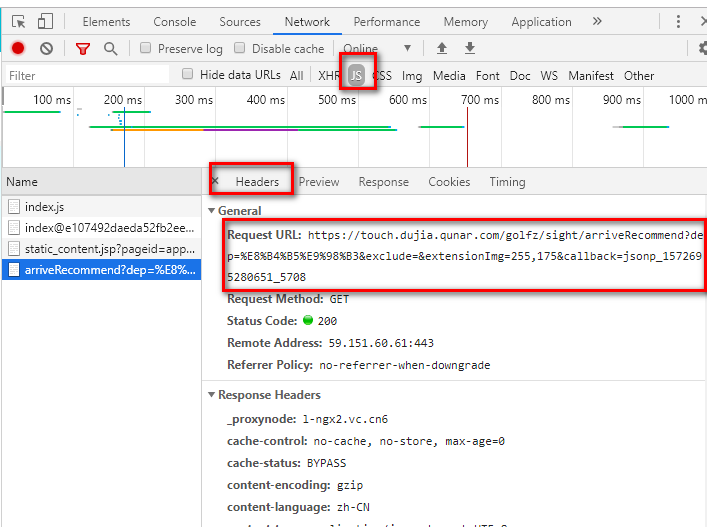
(3)单击任意一个城市,切换到headers,查看request URL如下所示。但是需要工具还原编码咋们才能知道这是啥(dep参数表示出发地,query表示目的地)。推荐网站http://www.jsons.cn/urlencode/,解码效果下面图2
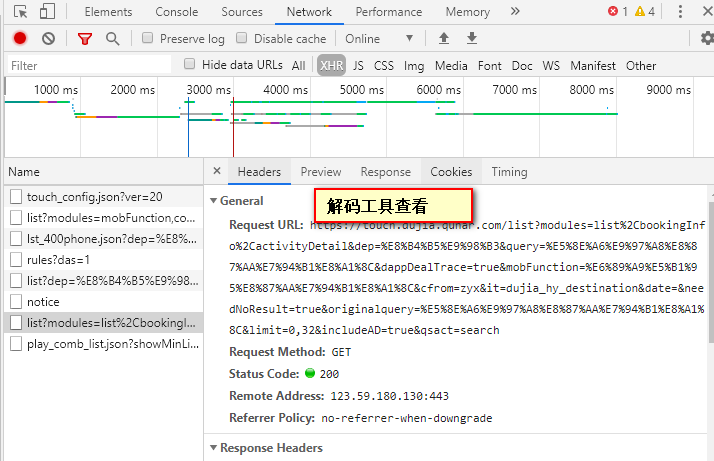

3 实现
(1)首先获得出发地站点,因为最终需要获得整个自由行的产品列表。
自由行首页中点击左侧的出发点站点,然后获取目标URL如图二

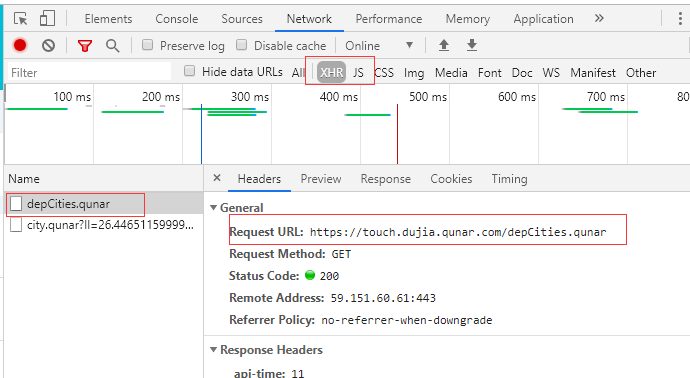
import requests
url="https://touch.dujia.qunar.com/depCities.qunar" strhtml=requests.get(url)
print(strhtml)
dep_dict=strhtml.json()
print(dep_dict)
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
print(dep)
(2)获得目的地。根据上面的分析,json工具解码以后通过拼接可得URL。
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
(3)总源码
import requests
import urllib
import time
#import pymongo # client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# sheet_qunar_zyx=book_qunar['qunar_zyx'] #获取产品列表
def get_list(dep,item):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit=0,20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item), urllib.request.quote(item))
strhtml = get_json(url)
try:
routeCount = int(strhtml['data']['limit']['routeCount'])
except:
return
for limit in range(0, routeCount, 20):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit={},20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item),
urllib.request.quote(item), limit)
strhtml = get_json(url)
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': item,
'limit': limit,
'result': strhtml
}
#sheet_qunar_zyx.insert_one(result)
print(result) # def connect_mongo():
# client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# return book_qunar['qunar_zyx'] def get_json(url):
strhtml=requests.get(url)
time.sleep(1)
return strhtml.json() if __name__ == "__main__": url='https://touch.dujia.qunar.com/depCities.qunar'
dep_dict=get_json(url)
#这里是json格式 dep_dict中内嵌勒一层
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a = []#目的地去重
#经过解码工具可以得到dep表示出发地 query和originalquery表示目的地
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
arrive_dict = get_json(url)
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
if query['query'] not in a:
a.append(query['query'])
for item in a:
get_list(dep,item)
python爬虫2的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- WebPack探索之路(1)
1. 卸载全局的webpack npm ininstall webpack webpack-cli -g 其中安装webpack-cli 是可以让webpack在命令行中执行.在webpack4.0中 ...
- 【Java】《Java程序设计基础教程》第六章学习
第六章 常用的工具包 6.1 java.lang包 6.1.1 Object类 Object类是一个超级类,是所有类的直接或间接父类. public boolean equals(Object obj ...
- Bell数入门
贝尔数 贝尔数是以埃里克·坦普尔·贝尔命名,是组合数学中的一组整数数列,开首是(OEIS的A000110数列): $$B_0 = 1, B_1 = 1, B_2 = 2, B_3 = 5, B_4 = ...
- etcd增删改查

周一测试多条件查询 要求仿照知网高级查询页面重构期中考试多条件查询功能,可以根据志愿者姓名.性别.民族.政治面目.服务类别.注册时间六种条件实现模糊查询,输出结果以列表形式显示,显示姓名.性别,民族. ...
- Android学习小结
自从学习Android以来已经经过三个月了,如今市场对于Android工程师的需求接近饱和,所以学习Android的人也少了很多,很多的培训机构也逐渐将Android课程淘汰,导致学习Android的 ...
- 微信小程序知识云开发
一个小程序最多5个服务类目,一个月可以修改3次类目 小程序侵权投诉的发起与应对 软件著作权作品登记证书 实现小程序支付功能 如何借助官方支付api简单.高效率地实现小程序支付功能 借助小程序云开发实现 ...
- Java为什么没有指针
为了摒弃指针带来的风险(当然了,也就放弃了指针带来的效率). 1.C/C++为什么有指针? 这个很简单,程序都是在内存中运行的,只要有内存,就有内存地址,有地址,就必然有指针,只是C++对内存地址的访 ...
- 让你的shell更体贴
使用shell的时候很多,特别是拉幕式终端,使用时更加方便,同时可以利用 echo "Did you know that:" ;whatis $(ls /bin | shuf -n ...
- [开源] FreeSql.AdminLTE.Tools 根据实体类生成后台管理代码
前言 FreeSql 发布至今已经有9个月,功能渐渐完善,自身的生态也逐步形成,早在几个月前写过一篇文章<ORM 开发环境之利器:MVC 中间件 FreeSql.AdminLTE>,您可以 ...