Python Web编程
1.统一资源定位符(URL)
URL用来在Web上定位一个文档。浏览器只是Web客户端的一种,任何一个向服务器端发送请求来获取数据的应用程序都被认为是客户端
URL格式:port_sch://net_loc/path;params?query#frag
port_sch 网络协议或者下载规划,如http
/net_loc 服务器位置,如www.baidu.com
path 斜杠/限定文件或者CGI应用程序的路径
params 可选参数
query 连接符&连接键值对
frag 拆分文档中的特殊锚
2.urllib模块
urlopen(urlstr,postQueryData=None) #打开一个给定URL字符串与Web连接,并返回了文件类的对象
f.read([bytes]) #从f中读出所有或bytes个字节
f.readline() #从f中读出一行
f.readlines() #从f中读出所有行并返回一个列表
f.close() #关闭f的URL的连接
f.fileno() #返回f文件的句柄
f.info() #获得f的MIME头文件,文件类型可以用哪类应用程序打开
f.geturl() #返回f所打开的真正的URL urlretrieve(urlstr,localfile=None,downloadStatusHook=None)
#可以方便地将urlstr定位到的整个HTML文件下载到本地的硬盘上。
#返回一个二元组(filename,mine_hdrs),filename是包含下载数据的本地文件名,mine_hdrs是对Web服务器响应后返回的一系列MIME文件头 quote(urldata,safe='/') #将urldata的无效的URL字符编码;在safe列的则不必编码
3.urllib.request
在Python3.3后urllib2已经不能再用,只能用urllib.request来代替,可以处理更复杂URL的打开问题,如有基本认证(登录名和密码名)需求的Web站点
基本的网络请求示例
import urllib.request
f = urllib.request.urlopen('http://www.baidu.com',data=None,timeout=10) #请求百度网页,超过10s为请求超时
print(f.read().decode('utf-8')) #读取所有字节数据并解码
print(f.status) #请求头信息 200代表成功 404代表网页未找到
urllib.request.Request(urll,data=None,headers={},method=None)
headers参数是一个字典,可以在构造Request时传参,也可以通过调用Request对象的add_header()方法来添加请求头,默认的User-Agent是Python-urllib可修改它来伪装成浏览器
method是一个字符串,用来指定请求使用的方式,如GET POST PUT
4.GET、PUT、POST
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
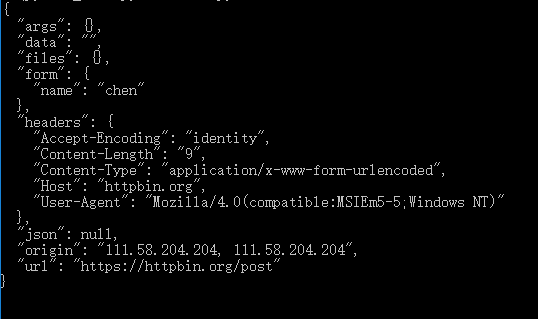
from urllib import request,parse url = "http://httpbin.org/post"
headers = { #伪装成一个火狐浏览器
"User-Agent":'Mozilla/4.0(compatible:MSIEm5-5;Windows NT)',
"host":'httpbin.org' #httpbin.org 这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、ip、headers 和登录验证等,且支持 GET、POST 等多种方法
} dict = {"name":"chen"}
data = bytes(parse.urlencode(dict),encoding="utf-8") #data如果是一个字典,可先用urllib.parse.urlencode()编码,再用bytes转换成字节流
req = request.Request(url = url,data=data,headers=headers,method='POST') #data须是字节流
response = request.urlopen(req)
print(response.read().decode('utf-8'))
返回结果:
Python Web编程的更多相关文章
- 系列文章--Python Web编程
我从网上找到了其他园友的文章,很不错,留着自己学习学习. Python Web编程(一)Python Web编程(二)Python Web编程(三)Python Web编程(四)Python Web编 ...
- python web编程-CGI帮助web服务器处理客户端编程
这几篇博客均来自python核心编程 如果你有任何疑问,欢迎联系我或者仔细查看这本书的地20章 另外推荐下这本书,希望对学习python的同学有所帮助 概念预热 eb客户端通过url请求web服务器里 ...
- python web编程-概念预热篇
互联网正在引发一场革命??不喜欢看概念的跳过,注意这里仅仅是一些从python核心编程一书的摘抄 这正是最激动人心的一部分了,web编程 Web 客户端和服务器端交互使用的“语言”,Web 交互的标准 ...
- Python web编程 初识TCP UDP
Python网络编程之初识TCP,UDP 这篇文章是读了<Python核心编程>第三版(Core Python Applications)的第二章网络编程后的自我总结. 如果有不到位或者错 ...
- python web编程 创建一个web服务器
这里就介绍几个底层的用于创建web服务器的模块,其中最为主要的就是BaseHTTPServer,很多框架和web服务器就是在他们的基础上创建的 基础知识 要建立一个Web 服务,一个基本的服务器和一个 ...
- python web编程-web客户端编程
web应用也遵循客户服务器架构 浏览器就是一个基本的web客户端,她实现两个基本功能,一个是从web服务器下载文件,另一个是渲染文件 同浏览器具有类似功能以实现简单的web客户端的模块式urllib以 ...
- python web编程CGI
CGI(通用网关接口),CGI 是Web 服务器运行时外部程序的规范,按CGI 编写的程序可以扩展服务器功能. CGI 应用程序能与浏览器进行交互,还可通过数据库API 与数据库服务器等外部数据源进行 ...
- python web编程之网络基础
1.TCP/IP协议 1)分层 应用层,传输层,网络层,接口层 2)Ip地址 3)域名 4)URL统一资源定位符 格式: [协议]://[主机]:[端口]/[路径]?[参数] 协议是HTTP,F ...
- Python的Web编程[0] -> Web客户端[1] -> Web 页面解析
Web页面解析 / Web page parsing 1 HTMLParser解析 下面介绍一种基本的Web页面HTML解析的方式,主要是利用Python自带的html.parser模块进行解析.其 ...
随机推荐
- ASP.NET Core: BackgroundService停止(StopAsync)后无法重新启动(StartAsync)的问题
这里的 BackgroundService 是指: Microsoft.Extensions.Hosting.BackgroundService 1. 问题复现 继承该BackgroundServic ...
- Asp.Net或WebAPI获取表单数据流(批量文件上传)
//Web或WebAPI获取表单数据流(批量文件上传) public JsonResult UploadFile() { //HttpPostedFi ...
- vue 获取视频时长
参考资料:js获取上传音视频文件的时长 直接通过element-ui自带的上传组件结合js即可,代码如下: HTML: <el-upload class="upload-demo&qu ...
- Java学习——日期类
Java学习——日期类 摘要:本文主要记录了Java开发中用到的和日期有关的类以及对日期的操作. 部分内容来自以下博客: https://www.cnblogs.com/talk/p/2680591. ...
- .NET同一个页面父容器与子容器通信方案
主界面: 关键主页面代码: <div id="EditDiv"> <iframe src="javascript:void(0)" id=&q ...
- 深入理解--VUE组件中数据的存放以及为什么组件中的data必需是函数
1.组件中数据的存放 ***(重点)组件是一个单独模块的封装:这个模块有自己的HTML模板,也有data属性. 只是这个data属性必需是一个函数,而这个函数返回一个对象,这个对象里面存放着组件的数据 ...
- 2.GoF 的 23 种设计模式的分类和功能
1. 根据目的来分 根据模式是用来完成什么工作来划分,这种方式可分为创建型模式.结构型模式和行为型模式 3 种. 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”.GoF ...
- Redis 3.2.x版本 redis.conf 的配置文件参数详解
[root@web01 blog]# egrep -v"#|^$" /application/redis/conf/6379.conf bind127.0.0.1 #绑定的主机地址 ...
- vs2017离线安装vs tools for unity
Visual Studio Tools for Unity 从vs2017开始就不提供单独的安装包下载,需要通过vs安装程序在线安装. vs2017离线安装vs tools for unity 那么如 ...
- Codeforces Round #590 (Div. 3) F
传送门 题意: 给出一个只含前\(20\)个字符的字符串,现在可以选择一段区间进行翻转,问区间中字符各不相同时,最长长度为多少. 思路: 首先,容易将题意转换为选择两个字符各不相同的区间,然后长度相加 ...