VLAD算法浅析, BOF、FV比较
划重点
VLAD(Vector of Aggragate Locally Descriptor)算法
VLAD算法可以分为如下几步:
1、提取图像的SIFT描述子
2、利用提取到的SIFT描述子(是所有训练图像的SIFT)训练一本码书,训练方法是K-means
3、把一副图像所有的SIFT描述子按照最近邻原则分配到码书上(也即分配到K个聚类中心)
4、对每个聚类中心做残差和(即属于当前聚类中心的所有SIFT减去聚类中心然后求和)
5、对这个残差和做L2归一化,然后拼接成一个K*128的长向量。128是单条SIFT的长度
如果不考虑海量数据的话,这个训练和建库过程已经可以了,直接保存第五步的结果(图像库),然后对查询图像做上述的操作,之后计算和图像库中每一条向量的欧式距离,输出前5个最小距离,既是一次完整的检索过程。
一、简介
虽然现在深度学习已经基本统一了图像识别与分类这个江湖,但是我觉得在某些小型数据库上或者小型的算法上常规的如BoW,FV,VLAD,T-Embedding等还是有一定用处的,如果专门做图像检索的不知道这些常规算法也免得有点贻笑大方了。
如上所说的这些算法都大同小异,一般都是基于局部特征(如SIFT,SURF)等进行特征编码获得一个关于图像的feature,最后计算feature之间的距离,即使是CNN也是这个过程。下面主要就是介绍一下关于VLAD算法,它主要是得优点就是相比FV计算量较小,相比BoW码书规模很小,并且检索精度较高。
二、VLAD算法
- 第一步自然是提取局部特征,有了OpenCV这一步就仅仅是函数调用的问题了:
SurfFeatureDetector detector;
SurfDescriptorExtractor extractor;
detector.detect( image_0, keypoints );
extractor.compute( image_0, keypoints, descriptors );如果对特征有什么要求也可以根据OpenCV的源码或者网上的源码进行修改,最终的结果就是提取到了一幅图像的局部特征(还有关于局部特征参数的控制);
- 第二步本应是量化的过程,但是在量化之前需要事先训练一本码书,而码书同BoW一样是用K-means算法训练得到的,同样OpenCV里面也集成了这个算法,所以这个过程也再简单不过了:
kmeans(descriptors, numClusters, labels,
TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, , 0.01 ),
, KMEANS_PP_CENTERS, centers);需要做的就是定义一些参数,如果自己写的话就不清楚了。另外码书的大小从64-256甚至更大不等,理论上码书越大检索精度越高。
- 第三步就是量化每一幅图像的特征了,其实如果数据库较小,可以直接使用全部图像的特征作训练,然后Kmeans函数中的labels中存储的就是量化的结果:即每一个特征距离那一个聚类中心最近。但是通常训练和量化是分开的,在VLAD算法中使用的是KDTree算法,KDTree算法是一种快速检索算法,OpenCV里同样集成了KDTree算法:
const int k=, Emax=INT_MAX;<br>KDTree T(centers,false);
T.findNearest(descriptors_row, k, Emax, idx_t, noArray(), noArray());通过KDTree下的findNearest函数找到与之最近的聚类中心,需要注意的是输入的STL的vector类型,返回的是centers的索引值;
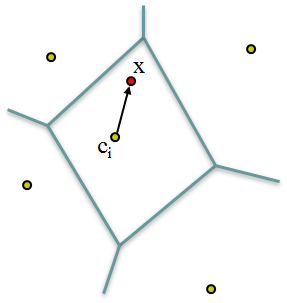
- 量化结束之后就是计算特征和中心的残差,并对每一幅图像落在同一个聚类中心上的残差进行累加求和,并进行归一化处理,最后每一个聚类中心上都会得到一个残差的累加和,进行归一化时需要注意正负号的问题(针对不同的特征)。假设有k个聚类中心,则每一个聚类中心上都有一个128维(SIFT)残差累加和向量;
- 把这k个残差累加和串联起来,获得一个超长向量,向量的长度为k*d(d=128),然后对这个超长矢量做一个power normolization处理可以稍微提升检索精度,然后对这个超长矢量再做一次归一化,现在这个超长矢量就可以保存起来了。
- 假设对N幅图像都进行了上面的编码处理之后就会得到N个超长矢量,为了加快距离计算的速度通常需要进行PCA降维处理,关于PCA降维的理论同KDTree一样都很成熟,OpenCV也有集成,没有时间自己写就可以调用了:
PCA pca( vlad, noArray(), CV_PCA_DATA_AS_ROW, );
pca.project(vlad,vlad_tt);输入训练矩阵,定义按照行或列进行降维,和降维之后的维度,经过训练之后就可以进行投影处理了,也可以直接调用特征向量进行矩阵乘法运算。这里有一点就是PCA的过程是比较费时的,进行查询的时候由于同样需要进行降维处理,所以可以直接保存投影矩阵(特征值矩阵),也可以把特征向量、特征值、均值都保存下来然后恢复出训练的pca,然后进行pca.project进行投影处理;
- 如果不考虑速度或者数据库规模不是很大时,就可以直接使用降维后的图像表达矢量进行距离计算了,常用的距离就是欧式距离和余弦距离,这里使用余弦距离速度更快。当然进行距离计算的基础就是已经设计好了训练过程和查询过程。
三、总结
可以看到,整个VLAD算法结合OpenCV实现起来还是非常简单的,并且小型数据库上的检索效果还可以,但是当数据库规模很大时只使用这一种检索算法检索效果会出现不可避免的下降。另外在作者的原文中,针对百万甚至千万级的数据库时单单使用PCA降维加速距离的计算仍然是不够的,所以还会使用称之为积量化或乘积量化(Product Quantization)的检索算法进行加速,这个也是一个很有意思的算法,以后有机会再介绍它。
VLAD算法浅析, BOF、FV比较的更多相关文章
- EM算法浅析(二)-算法初探
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.EM算法简介 在EM算法之一--问题引出中我们介绍了硬币的问题,给出了模型的目标函数,提到了这种 ...
- EM算法浅析(一)-问题引出
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.基本认识 EM(Expectation Maximization Algorithm)算法即期望 ...
- AtomicInteger的CAS算法浅析
之前浅析过自旋锁(自旋锁浅析),我们知道它的实现原理就是CAS算法.CAS(Compare and Swap)即比较并交换,作为著名的无锁算法,它也是乐观锁的实现方式之一.JDK并发包里也有许多代码中 ...
- KMP算法浅析
具体参见: KMP算法详解 背景: KMP算法之所以叫做KMP算法是因为这个算法是由三个人共同提出来的,就取三个人名字的首字母作为该算法的名字.其实KMP算法与BF算法的区别就在于KMP算法巧妙的消除 ...
- PCA算法浅析
最近频繁在论文中看到「PCA」的影子,所以今天决定好好把「PCA」的原理和算法过程弄清楚. 「PCA」是什么 PCA,又称主成分分析,英文全称「Principal Components Analysi ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- Paxos算法浅析
前言在文章2PC/3PC到底是啥中介绍了2PC这种一致性协议,从文中了解到2PC更多的被用在了状态一致性上(分布式事务),在数据一致性中很少被使用:而Paxos正是在数据一致性中被广泛使用,在过去十年 ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- 图的最短路径---弗洛伊德(Floyd)算法浅析
算法介绍 和Dijkstra算法一样,Floyd算法也是为了解决寻找给定的加权图中顶点间最短路径的算法.不同的是,Floyd可以用来解决"多源最短路径"的问题. 算法思路 算法需要 ...
随机推荐
- python写文件无法换行的问题
python写文件无法换行的问题,用'\n' 不行,直接打印的出来了. 网上查了查,都说是用 ‘\r\n’ ,但是这样打出来,不仅换行了,还加了一个空行. windows平台最后结果是 直接 ...
- Java 之 Request 对象
一.Request 对象和 Response 对象原理 request和response对象是由服务器创建的,供我们使用的. request对象是来获取请求消息,response对象是来设置响应消息. ...
- 英语dyamaund钻石
dyamaund 英文词汇,中文翻译为金刚石的;镶钻;用钻石装饰 中文名:镶钻;钻石装饰 外文名:dyamaund 目录 释义 dyamaund 读音:[ˈdaɪəmənd, ˈdaɪmənd] ...
- FI-FBV0 - No batch input data for screen SAPMF05A 0700
在预制凭证过账的时候报错:没有屏幕SAPMF05A 0700 的批输入数据 https://answers.sap.com/questions/7203025/fbv0-no-batch-input- ...
- C#对MongDB取数据的常用代码
1.使用聚合取最新的实时数据(每一个测站有多条数据,取日期最新的数据.也就是每个测站取最新的值) var group = new BsonDocument { {"_id",new ...
- oracle中的存储过程(实例一)
引子 这是测试环境存在了很久的问题.由于基础配置信息(如:代理人信息)不像生产环境有专人维护,常常会有数据过期,导致无法使用的情况. 而很多配置数据是在外围系统维护(如代理人信息,在销管系统)以往的解 ...
- jquery.widget开发(1)
jquery.widget是挂件,通过挂件模式挂载在jquery对象上,其实本质上也就是用了$.fn.extend和$.extend的扩展. http://blog.sina.com.cn/s/blo ...
- MySQL Replication--复制延迟02--exec_time测试
复制延迟(Seconds_Behind_Master)测试 测试环境: MySQL 5.7.19 测试主从时间差: 检查主从系统时间差,同时在主库和从库执行SELECT NOW()语句: 主库:-- ...
- PHP中的十进制、八进制、二进制、十六进制
我们平时用的都是十进制. 比如:987这个数字,其本质就是7*10^0+8*10^1+9*10^2 个位数上的7,1就是1,十位上的8,1就是10,百位上的9,1是100 echo '<br&g ...
- python关于time几种格式处理方法总结
一.日期时间的表示方法: 时间戳 timestamp: 简介:时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,是一个float类型 展示形式:1575278720.331 时间 ...