R 基于朴素贝叶斯模型实现手机垃圾短信过滤
# 读取数数据, 查看数据结构
df_raw <- read.csv("sms_spam.csv", stringsAsFactors=F)
str(df_raw)
length(df_raw$type) # 将数据分为特征值矩阵 X 和 类标向量y 两部分,将 y 换为因子
X <- df_raw$text
y <- factor(df_raw$type)
length(y) # 查看类标向量 y 的结构和组成
str(y)
table(y) # 安装和加载文本挖掘包
#install.packages("tm")
library(NLP)
library(tm) # 创建语料库
X_corpus <- VCorpus(VectorSource(X))
######## 1 清洗文本数据 ########
# 1.1 将文本中的字母转换为小写
X_corpus_clean <- tm_map(X_corpus, content_transformer(tolower))
# 1.2 去除文本中的数字
X_corpus_clean <- tm_map(X_corpus_clean, removeNumbers) # 1.3 去除文本中的停用词
X_corpus_clean <- tm_map(X_corpus_clean, removeWords, stopwords()) # 1.4 去除文本中的标点符号
X_corpus_clean <- tm_map(X_corpus_clean, removePunctuation) # 添加包
#install.packages("SnowballC")
library(SnowballC)
# 1.5 提取文本中每个单词的词干
X_corpus_clean <- tm_map(X_corpus_clean, stemDocument) # 1.6 删除额外的空白
X_corpus_clean <- tm_map(X_corpus_clean, stripWhitespace) # 1.7 将文本文档拆分成词语, 创建文档——单词矩阵
X_dtm <- DocumentTermMatrix(X_corpus_clean) ############# 2 准备输入数据 #############
# 2.1 划分训练数据集和测试数据集
X_dtm_train <- X_dtm[1:4169, ]
X_dtm_test <- X_dtm[4170:5559, ] y_train <- y[1:4169]
y_test <- y[4170:5559]
# 说明:因为原始数据 df_raw 是随机选取的,所以可以直直接去前 75% 的数据为测试数据 # 2.2 检查样本分分布是否偏斜
prop.table(table(y_train))
prop.table(table(y_test)) # 2.3 过滤 DTM, 选取频繁出现的单词
X_freq_words <- findFreqTerms(X_dtm_train, 5) # 此处可以试错调整,以调节模型的性能
# 过滤 DTM
X_dtm_train_freq <- X_dtm_train[, X_freq_words]
X_dtm_test_freq <- X_dtm_test[, X_freq_words] # 2.4 将矩阵文本编码为数值
# 2.4.1定义一个变量转换函数
convert_counts <- function(x) {
x <- ifelse(x > 0, "Yes", "No")
} # 2.4.2 转换训练矩阵和测试矩阵
X_train <- apply(X_dtm_train_freq, MARGIN=2, convert_counts)
X_test <- apply(X_dtm_test_freq, MARGIN=2, convert_counts) ############# 3 基于数据训练模型 ############
# install.packages("e1071")
library(e1071) # 训练模型, 拉普拉斯估计参数默认为 0
NB_classifier <- naiveBayes(X_train, y_train) ############## 4 评估模型的性能 ############# # 4.1 对测试集中的样本进行预测
y_pred <- predict(NB_classifier, X_test) # 比较预测值和真实值
# library(gmodels)
CrossTable(x=y_test, y=y_pred,
prop.chisq = F, prop.t = F, prop.c = F,
dnn = c("actural", "predict"))
模型 NB_classifier 在测试集上进行预测的混淆矩阵为:
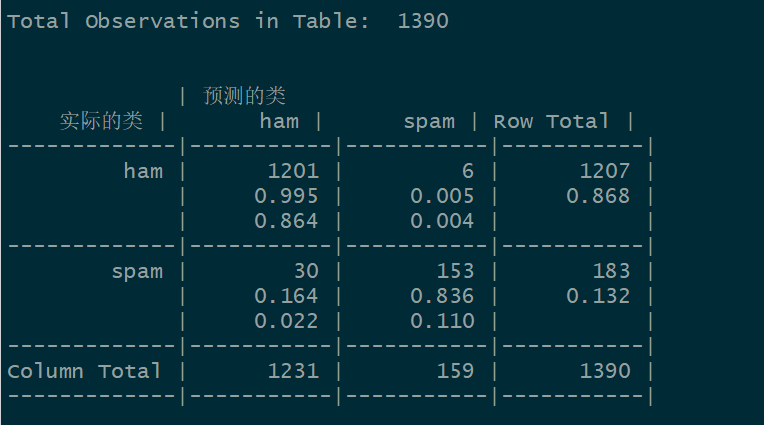
准确率 = 0.864 + 0.110 = 0.974
对模型调参
################## 5 提高模型的性能 ################## # 5.1 添加拉普拉斯估计,训练模型
NB_classifier2 <- naiveBayes(x = X_train, y = y_train, laplace = 1) # 5.2 对测试集中的样本进行预测
y_pred2 <- predict(NB_classifier2, X_test) # 5.3 比较预测值和真实值
CrossTable(x = y_test, y = y_pred2,
prop.chisq = F, prop.t = T, prop.c = F,
dnn = c("actural", "predict"))
经过参数调优后的模型 NB_classifier2 在测试集上进行预测的混淆矩阵为:
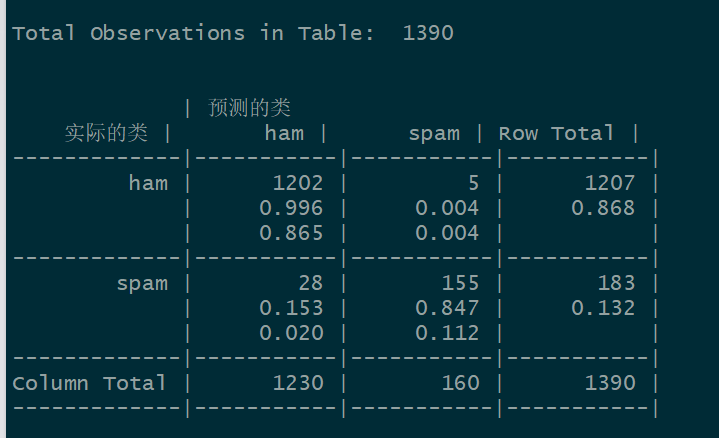
准确率 = 0.865 + 0.112 =0.977
按语:
经过拉普拉斯估计参数的调节,模型准确率有 0.974 提高至 0.977,在高准确的前提下能有提升,实属不易。
R 基于朴素贝叶斯模型实现手机垃圾短信过滤的更多相关文章
- 机器学习Matlab打击垃圾邮件的分类————朴素贝叶斯模型
该系列来自于我<人工智能>课程回顾总结,以及实验的一部分进行了总结学习机 垃圾分类是有监督的学习分类最经典的案例,本文首先回顾了概率论的基本知识.则以及朴素贝叶斯模型的思想.最后给出了垃圾 ...
- 一步步教你轻松学朴素贝叶斯模型算法Sklearn深度篇3
一步步教你轻松学朴素贝叶斯深度篇3(白宁超 2018年9月4日14:18:14) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受欢迎,对 ...
- Java实现基于朴素贝叶斯的情感词分析
朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位.在之前 ...
- PGM:贝叶斯网表示之朴素贝叶斯模型naive Bayes
http://blog.csdn.net/pipisorry/article/details/52469064 独立性质的利用 条件参数化和条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑 ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- 详解基于朴素贝叶斯的情感分析及 Python 实现
相对于「 基于词典的分析 」,「 基于机器学习 」的就不需要大量标注的词典,但是需要大量标记的数据,比如: 还是下面这句话,如果它的标签是: 服务质量 - 中 (共有三个级别,好.中.差) ╮(╯-╰ ...
- 统计学习1:朴素贝叶斯模型(Numpy实现)
模型 生成模型介绍 我们定义样本空间为\(\mathcal{X} \subseteq \mathbb{R}^n\),输出空间为\(\mathcal{Y} = \{c_1, c_2, ..., c_K\ ...
- 11.sklearn中的朴素贝叶斯模型及其应用
#1.使用朴素贝叶斯模型对iris数据集进行花分类 #尝试使用3种不同类型的朴素贝叶斯: #高斯分布型,多项式型,伯努利型 from sklearn import datasets iris=data ...
- Python实现 利用朴素贝叶斯模型(NBC)进行问句意图分类
目录 朴素贝叶斯分类(NBC) 程序简介 分类流程 字典(dict)构造:用于jieba分词和槽值替换 数据集构建 代码分析 另外:点击右下角魔法阵上的[显示目录],可以导航~~ 朴素贝叶斯分类(NB ...
随机推荐
- Node.js—基本知识
一.第一个Node代码 1. 运行Node.js 通过node E:\Node代码\hello.js运行代码:Node.js是服务器的程序,写的js语句都将运行在服务器上.返回给客户的,都是已经处 ...
- luoguP2486 [SDOI2011]染色
题目 Description 给定一棵有n个节点的无根树和m个操作,操作有2类: 1.将节点a到节点b路径上所有点都染成颜色c: 2.询问节点a到节点b路径上的颜色段数量(连续相同颜色被认为是同一段) ...
- python的wraps函数
当使用@修饰符修饰函数时,会存在这样一个问题:被修饰的函数会消失(这是因为修饰函数没有设置返回值,如果设置了返回值,则就把返回值赋给被修饰函数,比如,test1函数的返回值设置为 return 6, ...
- Gin实现依赖注入
前言 依赖注入的好处和特点这里不讲述了,本篇文章主要介绍gin框架如何实现依赖注入,将项目解耦. 项目结构 ├── cmd 程序入口 ├── common 通用模块代码 ├── config 配置文件 ...
- Harbor + Https 部署
关闭防火墙和selinux systemctl stop firewalld sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/sysconfig/selin ...
- 解决 Github 图片加载慢的问题
一.前言 本文主要介绍一种解决 Github 图片加载慢的方法,亲测有效. 笔者博客是使用 Github 作为图床,每次打开博客时的图片加载很慢或者根本加载不出来.这是因为 GitHub 的 CDN ...
- Python连载26-shelve模块
一.持久化 --shelve 持久化工具 (1)作用:类似字典,用kv对保存数据,存取方式类似于字典 (2)例子:通过一下案例创建了一个数据库,第二个程序我们读取了数据库 #使用shelve创建文件并 ...
- Eureka服务注册中心错误:com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect
报错信息 14:43:45.484 [main] INFO com.netflix.discovery.DiscoveryClient - Getting all instance registry ...
- LeetCode 160: 相交链表 Intersection of Two Linked Lists
爱写Bug(ID:iCodeBugs) 编写一个程序,找到两个单链表相交的起始节点. Write a program to find the node at which the intersectio ...
- 【shell命令】$#、$*、$n分别表示的含义
$#.$*.$n分别表示的含义 1.[$0] 表示当前脚本的文件名: 2.[$n] 表示传递给脚本的第n个参数值(n为1~9): 3.[$*] 表示传递给脚本的所有参数(不包括脚本名称的参数): 4. ...