(转载)极大似然估计&最大后验概率估计
前言
不知看过多少次极大似然估计与最大后验概率估计的区别,但还是傻傻分不清楚。或是当时道行太浅,或是当时积累不够。
这次重游机器学习之路,看到李航老师《统计学习方法》中第一章关于经验风险最小化与结构风险最小化时谈到了极大似然与最大后验的话题,第一反应是竟然在第一章就谈到了极大似然与最大后验,相信大部分初学者看到这两个词时还是怕怕的,毕竟没有太多理论基础。不过没关系,多积累,多搜集相关资料,相信这层疑惑的云雾会逐渐散去的。
这次结合西瓜书和网上大牛的资料,加上自己推荐系统的研究背景以及自己的思考,总算是有些许收获,不虚此行。点滴进步都值得被记录,一来向大家分享,二来谨防遗忘。
频率学派与贝叶斯派
在说极大似然估计(Maximum Likelihood Estimate)与最大后验概率估计(Maximum A Posteriori estimation)之前,不得不说对于概率看法不同的两大派别频率学派与贝叶斯派。他们看待世界的视角不同,导致他们对于产生数据的模型参数的理解也不同。
① 频率学派
他们认为世界是确定的。他们直接为事件本身建模,也就是说事件在多次重复实验中趋于一个稳定的值p,那么这个值就是该事件的概率。
他们认为模型参数是个定值,希望通过类似解方程组的方式从数据中求得该未知数。这就是频率学派使用的参数估计方法-极大似然估计(MLE),这种方法往往在大数据量的情况下可以很好的还原模型的真实情况。
② 贝叶斯派
他们认为世界是不确定的,因获取的信息不同而异。假设对世界先有一个预先的估计,然后通过获取的信息来不断调整之前的预估计。 他们不试图对事件本身进行建模,而是从旁观者的角度来说。因此对于同一个事件,不同的人掌握的先验不同的话,那么他们所认为的事件状态也会不同。
他们认为模型参数源自某种潜在分布,希望从数据中推知该分布。对于数据的观测方式不同或者假设不同,那么推知的该参数也会因此而存在差异。这就是贝叶斯派视角下用来估计参数的常用方法-最大后验概率估计(MAP),这种方法在先验假设比较靠谱的情况下效果显著,随着数据量的增加,先验假设对于模型参数的主导作用会逐渐削弱,相反真实的数据样例会大大占据有利地位。极端情况下,比如把先验假设去掉,或者假设先验满足均匀分布的话,那她和极大似然估计就如出一辙了。
极大似然估计与最大后验概率估计
我们这有一个任务,就是根据已知的一堆数据样本,来推测产生该数据的模型的参数,即已知数据,推测模型和参数。因此根据两大派别的不同,对于模型的参数估计方法也有两类:极大似然估计与最大后验概率估计。
① 极大似然估计(MLE)
-她是频率学派模型参数估计的常用方法。
-顾名思义:似然,可以简单理解为概率、可能性,也就是说要最大化该事件发生的可能性
-她的含义是根据已知样本,希望通过调整模型参数来使得模型能够最大化样本情况出现的概率。
- 在这举个猜黑球的例子:假如一个盒子里面有红黑共10个球,每次有放回的取出,取了10次,结果为7次黑球,3次红球。问拿出黑球的概率 是多少?
- 我们假设7次黑球,3次红球为事件
,一个理所当然的想法就是既然事件
看成一个关于
的函数,求
- 接下来就是取对数转换为累加,然后通过求导令式子为0来求极值,求出p的结果。

② 最大后验概率估计(MAP)
-她是贝叶斯派模型参数估计的常用方法。
-顾名思义:就是最大化在给定数据样本的情况下模型参数的后验概率
-她依然是根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例(万一数据量少或者数据不靠谱呢)。
-在这里举个掷硬币的例子:抛一枚硬币10次,有10次正面朝上,0次反面朝上。问正面朝上的概率 。
- 在频率学派来看,利用极大似然估计可以得到
10 / 10 = 1.0。显然当缺乏数据时MLE可能会产生严重的偏差。
- 如果我们利用极大后验概率估计来看这件事,先验认为大概率下这个硬币是均匀的 (例如最大值取在0.5处的Beta分布),那么
,是一个分布,最大值会介于0.5~1之间,而不是武断的给出
= 1。
- 显然,随着数据量的增加,参数分布会更倾向于向数据靠拢,先验假设的影响会越来越小。
经验风险最小化与结构风险最小化
经验风险最小化与结构风险最小化是对于损失函数而言的。可以说经验风险最小化只侧重训练数据集上的损失降到最低;而结构风险最小化是在经验风险最小化的基础上约束模型的复杂度,使其在训练数据集的损失降到最低的同时,模型不至于过于复杂,相当于在损失函数上增加了正则项,防止模型出现过拟合状态。这一点也符合奥卡姆剃刀原则:如无必要,勿增实体。
经验风险最小化可以看作是采用了极大似然的参数评估方法,更侧重从数据中学习模型的潜在参数,而且是只看重数据样本本身。这样在数据样本缺失的情况下,很容易管中窥豹,模型发生过拟合的状态;结构风险最小化采用了最大后验概率估计的思想来推测模型参数,不仅仅是依赖数据,还依靠模型参数的先验假设。这样在数据样本不是很充分的情况下,我们可以通过模型参数的先验假设,辅助以数据样本,做到尽可能的还原真实模型分布。
① 经验风险最小化
-MLE她是经验风险最小化的例子。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。在这里举个逻辑回归(LR)的例子,更多跟LR有联系的模型可参看拙作由Logistic Regression所联想到的...。
- 对于二分类的逻辑回归来说,我们试图把所有数据正确分类,要么0,要么1。
- 通过累乘每个数据样例来模拟模型产生数据的过程,并且最大化
。
- 我们需要通过取对数来实现概率之积转为概率之和
。
- 我们可以根据数据标签的0、1特性来把上式改为
-这样,我们通过极大似然来推导出了逻辑回归的损失函数,同时极大似然是经验风险最小化的一个特例。
② 结构风险最小化
-MAP她是结构风险最小化的例子。当模型是条件概率分布、损失函数是对数损失函数、模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验概率估计。 在这里举个推荐系统中的概率矩阵分解(PMF)的例子。
- 先说下矩阵分解的原理:推荐系统的评分预测场景可看做是一个矩阵补全的游戏,矩阵补全是推荐系统的任务,矩阵分解是其达到目的的手段。因此,矩阵分解是为了更好的完成矩阵补全任务(欲其补全,先其分解之)。之所以可以利用矩阵分解来完成矩阵补全的操作,那是因为基于这样的假设-假设UI矩阵是低秩的,即在大千世界中,总会存在相似的人或物,即物以类聚,人以群分,然后我们可以利用两个小矩阵相乘来还原评分大矩阵。
- 它假设评分矩阵中的元素
是由用户潜在偏好向量
和物品潜在属性向量
的内积决定的,并且服从均值为
,方差为
的正态分布:
。
- 则观测到的评分矩阵条件概率为:

- 同时,假设用户偏好向量与物品偏好向量服从于均值都为0,方差分别为
,
的正态分布:
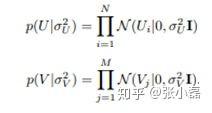
- 根据最大后验概率估计,可以得出隐变量
的后验概率为:
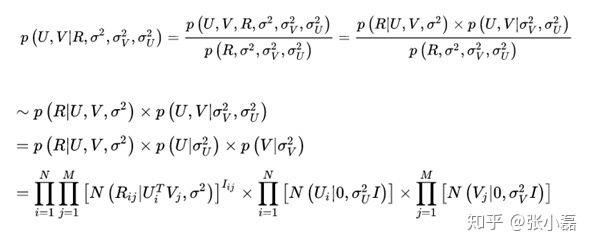
- 接着,等式两边取对数
,并且将正态分布展开后得到:
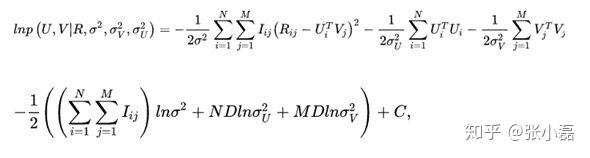
-这样,我们通过最大后验概率估计推导出了概率矩阵分解的损失函数。可以看出结构风险最小化是在经验风险最小化的基础上增加了模型参数的先验。
MLE与MAP的联系
-在介绍经验风险与结构风险最小化的时候以具体的逻辑回归(LR)与概率矩阵分解(PMF)模型来介绍MLE和MAP,接下里从宏观的角度,不局限于具体的某个模型来推导MLE与MAP。
-假设数据是满足独立同分布(i.i.d.)的一组抽样
,接下来就利用两种参数估计方法来求解。
- MLE对参数
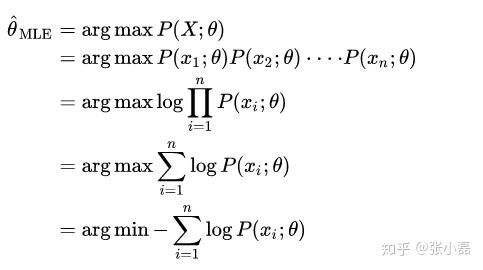
- MAP对
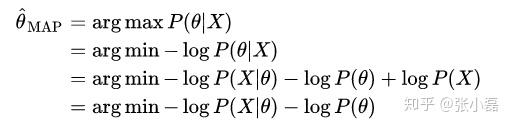
-所以MAP和MLE在优化时的不同就是在于增加了一个先验项。
-通过以上的分析可以大致给出他们之间的联系: 。
参考资料
- 《统计学习方法》 李航
- 《机器学习》周志华
- 聊一聊机器学习的MLE和MAP:最大似然估计和最大后验估计
- 最大似然估计和逻辑回归
- 渣君:最大似然估计和最小二乘法怎么理解?
致谢
至此,频率学派与贝叶斯派,MLE与MAP,经验风险最小化与结构风险最小化的区别与联系已经介绍完毕了,由于本人不是数据专业出身的,并且也是机器学习初学者,难免在叙述或者思考的过程中有不严谨或者不正确的东西,希望大家批判的去看待。
再次感谢以上参考资料以及大牛们的分享。
作者:张小磊
链接:https://zhuanlan.zhihu.com/p/40024110
来源:知乎
(转载)极大似然估计&最大后验概率估计的更多相关文章
- [白话解析] 深入浅出 极大似然估计 & 极大后验概率估计
[白话解析] 深入浅出极大似然估计 & 极大后验概率估计 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解 极大似然估计 & 极大后验概率估计,并且从名著中找 ...
- 极大似然估计&最大后验概率估计
https://guangchun.wordpress.com/2011/10/13/ml-bayes-map/ http://www.mi.fu-berlin.de/wiki/pub/ABI/Gen ...
- 极大似然估计、贝叶斯估计、EM算法
参考文献:http://blog.csdn.net/zouxy09/article/details/8537620 极大似然估计 已知样本满足某种概率分布,但是其中具体的参数不清楚,极大似然估计估计就 ...
- 机器学习(二十五)— 极大似然估计(MLE)、贝叶斯估计、最大后验概率估计(MAP)区别
最大似然估计(Maximum likelihood estimation, 简称MLE)和最大后验概率估计(Maximum aposteriori estimation, 简称MAP)是很常用的两种参 ...
- 详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
转载声明:本文为转载文章,发表于nebulaf91的csdn博客.欢迎转载,但请务必保留本信息,注明文章出处. 原文作者: nebulaf91 原文原始地址:http://blog.csdn.net/ ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 【机器学习基本理论】详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
[机器学习基本理论]详解最大似然估计(MLE).最大后验概率估计(MAP),以及贝叶斯公式的理解 https://mp.csdn.net/postedit/81664644 最大似然估计(Maximu ...
- 浅议极大似然估计(MLE)背后的思想原理
1. 概率思想与归纳思想 0x1:归纳推理思想 所谓归纳推理思想,即是由某类事物的部分对象具有某些特征,推出该类事物的全部对象都具有这些特征的推理.抽象地来说,由个别事实概括出一般结论的推理称为归纳推 ...
- MLE极大似然估计和EM最大期望算法
机器学习十大算法之一:EM算法.能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么是神,因为神能做很多人做不了的事.那么EM ...
随机推荐
- WPF系列 —— 控件添加依赖属性
依赖属性的概念,用途 ,如何新建与使用.本文用做一个自定义TimePicker控件来演示WPF的依赖属性的简单应用. 先上TimePicker的一个效果图. 概念 和 用途:依赖属性是对传统.net ...
- 项目Beta冲刺(团队)——05.27(5/7)
项目Beta冲刺(团队)--05.27(5/7) 格式描述 课程名称:软件工程1916|W(福州大学) 作业要求:项目Beta冲刺(团队) 团队名称:为了交项目干杯 作业目标:记录Beta敏捷冲刺第5 ...
- python应用-判断回文素数
from math import sqrt number=int(input('请输入一个整数:')) def is_prime(num): for rea in range(2,int(sqrt(n ...
- xargs的用法
处理带有空格的文件名 #我们创建了3个日志文件, 且故意让文件名称中都含有空格 [roc@roclinux ~]$ ;i<;i++)); do touch "test ${i}.log ...
- TCP/IP通信过程(以发送电子邮件为例)(转)
1.应用程序处理 (1)A用户启动邮件应用程序,填写收件人邮箱和发送内容,点击“发送”,开始TCP/IP通信: (2)应用程序对发送的内容进行编码处理,这一过程相当于OSI的表示层功能: (3)由A用 ...
- WHAT IS THE DIFFERENCE BETWEEN REACT.JS AND REACT NATIVE?
Amit Ashwini - 09 SEPTEMBER 2017 React.js was developed by Facebook to address its need for a dynami ...
- swift与oc的关系
swift是对oc的扩展 Swift是没有消息机制的Objective-C https://www.oschina.net/translate/inside-swift: swift保持了oc的类结构 ...
- ZOJ3261-Connections in Galaxy War-(逆向并查集+离线处理)
题意: 1.有n个星球,每个星球有一个编号(1-n)和一个能量值. 2.一开始将某些星球连通. 3.开战后有很多个操作,查询某个星球能找谁求救或者摧毁两颗星球之间的连通路径,使其不能连通.如果连通则可 ...
- JS实现继承的几种方法
父类: // 定义一个动物的类 function Animal (name) { // 属性 this.name = name || 'Animal'; // 实例方法 this.sleep = fu ...
- LeetCode 886. Possible Bipartition
原题链接在这里:https://leetcode.com/problems/possible-bipartition/ 题目: Given a set of N people (numbered 1, ...