SparkStreaming+kafka Receiver模式
1.图解
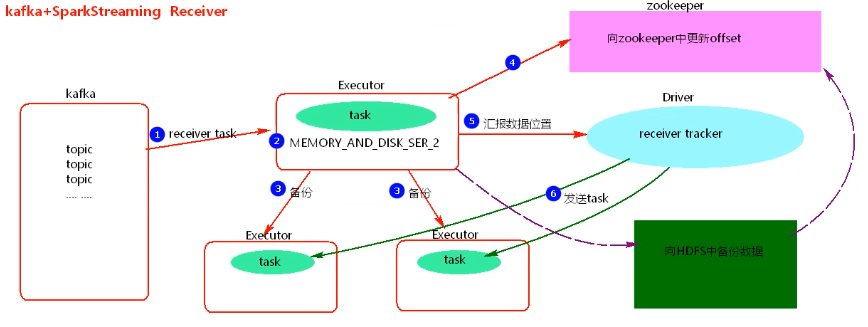
2.过程
1.使用Kafka的High Level Consumer API 实现,消费者不能自己去维护消费者offset,而且kafka也不关心数据是否丢失。
2.当向zookeeper中更新完offset后,Driver如果挂到,Driver下的Executors会被kill掉,会造成数据丢失。
3.开启WAL【Write Ahead Log】预写日志机制,将数据备份到HDFS中一份,再去更新zookeeper中的offset,此时需调整spark存储基本,去掉备份两次【MEMORY_AND_DISK_SER_2中的_2】。开启WAL机制会加大application处理的时间。
3.特点
1.receiver模式依赖zookeeper管理offset。
2.receiver模式的并行度由spark.streaming.blockInterval决定,默认是200ms。
3.receiver模式接收block.batch数据后会封装到RDD中,这里的block对应RDD中的partition。
4.在batchInterval一定的情况下,减少spark.streaming.Interval参数值,会增大DStream中的partition个数,建议spark.streaming.Interval最低不能低于50ms。
4.代码实现
package big.data.analyse.streaming import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkContext, SparkConf} /**
* Created by zhen on 2019/5/11.
*/
object SparkStreamingReceiverKafka {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("SparkStreamingReceiverKafka")
conf.set("spark.streaming.kafka.maxRatePerPartition", "")
conf.setMaster("local[2]") val sc = new SparkContext(conf)
sc.setLogLevel("WARN") val ssc = new StreamingContext(sc, Seconds()) // 创建streamingcontext入口 val quorum = "master,worker1,worker2"
val groupId = "zhenGroup"
val map : Map[String, Int] = Map("zhenTopic" -> ) // topic名称为zhenTopic,每次使用1个线程读取数据 val dframe = KafkaUtils.createStream(ssc, quorum, groupId, map, StorageLevel.MEMORY_AND_DISK_SER_2) dframe.foreachRDD(rdd => { // 操作方式和rdd类似,必须使用action算子才会触发程序执行!
rdd.foreachPartition(partition =>{
partition.foreach(println)
})
})
}
}
SparkStreaming+kafka Receiver模式的更多相关文章
- 【Spark篇】---SparkStreaming+Kafka的两种模式receiver模式和Direct模式
一.前述 SparkStreamin是流式问题的解决的代表,一般结合kafka使用,所以本文着重讲解sparkStreaming+kafka两种模式. 二.具体 1.Receiver模式 原理图 ...
- SparkStreaming+Kafka 处理实时WIFI数据
业务背景 技术选型 Kafka Producer SparkStreaming 接收Kafka数据流 基于Receiver接收数据 直连方式读取kafka数据 Direct连接示例 使用Zookeep ...
- SparkStreaming+Kafka整合
SparkStreaming+Kafka整合 1.需求 使用SparkStreaming,并且结合Kafka,获取实时道路交通拥堵情况信息. 2.目的 对监控点平均车速进行监控,可以实时获取交通拥堵情 ...
- [Spark]Spark-streaming通过Receiver方式实时消费Kafka流程(Yarn-cluster)
1.启动zookeeper 2.启动kafka服务(broker) [root@master kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh con ...
- 【SparkStreaming学习之四】 SparkStreaming+kafka管理消费offset
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark-Streaming kafka count 案例
Streaming 统计来自 kafka 的数据,这里涉及到的比较,kafka 的数据是使用从 flume 获取到的,这里相当于一个小的案例. 1. 启动 kafka Spark-Streaming ...
- Kafka KRaft模式探索
1.概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据.其核心组件包含Producer.Broker.Consumer,以及依赖的Zookeeper集群. ...
- kafka单机模式部署安装,zookeeper启动
在root的用户下 1):前提 安装JDK环境,设置JAVA环境变量 2):下载kafka,命令:wget http://mirrors.shuosc.org/apache/kafka/0.10.2 ...
- java kafka单列模式生产者客户端
1.所需要的依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="ht ...
随机推荐
- 面试突击(六)——JVM如何实现JAVA代码一次编写到处运行的?
声明:本文图片均来自网络,我只是进行了选择,利用一图胜千言的力量来帮助自己快速的回忆相关的知识点 JVM是 JAVA Virtual Machine 三个英文单词的首字母缩写,翻译成中文就是Java虚 ...
- Linux performance monitor tool
https://www.tecmint.com/command-line-tools-to-monitor-linux-performance/ https://www.tecmint.com/lin ...
- Java13新特性 -- 文本块
在JDK 12中引入了Raw String Literals特性,但在发布之前就放弃了.这个JEP与引入多行字符串文字(text block) 在意义上是类似的. 这条新特性跟 Kotlin 里的文本 ...
- word 条件多项式公式对齐
条件多项式公式对齐 觉得有用的话,欢迎一起讨论相互学习~Follow Me 对于使用word编写具有多个多项式的公式时,经常会有所偏移 最不优雅的方式就是使用逗号进行分隔和排版使其公式上下对齐 第二种 ...
- [No000019A]IDEA 设置手册
[No000019A]idea设置手册.rar IDEA 设置手册 IDEA 设置手册 plugin lgnore files and folesrs 代码管控 程序框架 部署方式 useless 3 ...
- MySQL创建触发器的时候报1419错误( 1419 - You do not have the SUPER privilege and binary logging is enabled )
mysql创建触发器的时候报错: 解决方法:第一步,用root用户登录:mysql -u root -p第二步,设置参数log_bin_trust_function_creators为1:set gl ...
- Java之布尔运算
对于布尔类型boolean,永远只有true和false两个值. 布尔运算是一种关系运算,包括以下几类 比较运算符:>,>=,<,<=,==,!= 与运算 && ...
- JobStorage.Current property value has not been initialized. You must set it before using Hangfire Client or Server API.
JobStorage.Current property value has not been initialized. You must set it before using Hangfire Cl ...
- 世界视频编码器大赛结果揭晓,腾讯V265编码器勇夺两项第一
2019年10月22日,由莫斯科国立大学(Moscow State University)举办的MSU世界视频编码器大赛成绩揭晓, 腾讯内部开源协同的V265编码器再创佳绩,一举拿下PSNR(峰值信噪 ...
- SQL Server中的GAM页和SGAM页
简介 我们已经知道SQL Server IO最小的单位是页,连续的8个页是一个区.SQL Server需要一种方式来知道其所管辖的数据库中的空间使用情况,这就是GAM页和SGAM页. Global A ...