reshape2 数据操作 数据融合 (melt)
前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致。
下面我们来看下,melt这个函数以及它的特点。
melt(data, ..., na.rm = FALSE, value.name = "value")
从这里来看函数的参数也相对比较简单,data表示要处理的数据,na.rm表示缺失值处理办法,value.name用于重命名值所在列的名称
另外,melt函数的难点在于,不同数据结构,用到的参数可能是不一样的。
首先,要融合的数据为数组、表以及矩阵,那么melt的表达式为:
melt(data, varnames = names(dimnames(data)), ..., na.rm = FALSE, as.is = FALSE, value.name = "value")
varnames用户命名变量名称
其次,要融合的数据为数据框,那么melt的表达式为:
melt(data, id.vars, measure.vars, variable.name = "variable", ..., na.rm = FALSE, value.name = "value", factorsAsStrings = TRUE)
id.vars 设置融合后单独显示的变量,可以用变量位置及名称表示,没写表示使用所有非measure.vars值
measure.vars 通常根据id.vars 设置的变化而变化
最后,要融合的数据为列表,那么melt的表达式为:
melt(data, ..., level = 1)
下面来看些具体的例子
data<- array(c(1:22, NA,"wo"), c(2,3,4))
data

melt(data)
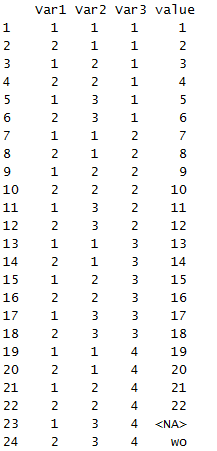
可以看出数据融合后,可读性比数组的情况下强了好多,var1表示数组的行,var2表示数组的列,var3表示数组序列。
比如,18位置就是第3数组,2行3列的位置,11则是第2数组,1行3列。
melt(a, na.rm = TRUE)

可以看到数组中的缺失值被移除了。
melt(data, varnames=c("hang","lie","Zu"))
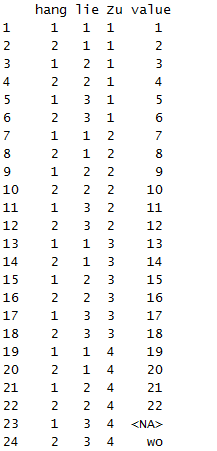
对融合后的每个变量进行重命名。
下面来看下数据为数据框的情况。
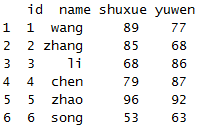
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x
melt(x,id=c("id","name"))
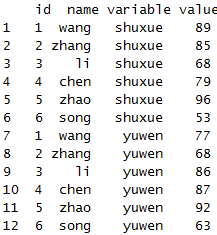
melt(x,id=1:2,variable.name="kemu",value.name="zhi")
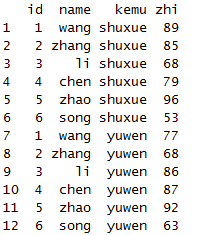
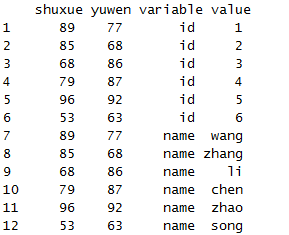
melt(x,measure.vars=c("id","name"))
最后,来看下如果数据是列表的情况
shuju<- list(matrix(1:4, ncol=2), array(1:27, c(3,3,3)))
shuju

这个列表的机构比较复杂,读起来有点难度
下面melt融合后的结果
melt(shuju)
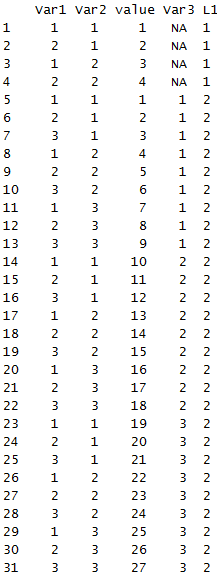
可以看出数据变得非常简洁。
reshape2 数据操作 数据融合 (melt)的更多相关文章
- reshape2 数据操作 数据融合( cast)
我们在做数据分析的时候,对数据进行操作也是一项极其重要的内容,这里我们同样介绍强大包reshape2,其中的几个函数,对数据进行操作cast和melt两个函数绝对少不了. 首先是cast,把长型数据转 ...
- dplyr 数据操作 数据排序 (arrange)
在R中,我们在整理数据时,经常需要对数据排序,以便数据增强数据的可读性. 下面我们来看下dplyr中的,arrange函数 arrange(.data, ...) 跟filter()类似,arrang ...
- dplyr 数据操作 数据过滤 (filter)
在R的使用过程中我们几乎都绕不开Hadley Wickham 开发的几个包,前面说过的ggplot2.reshape2以及即将要讲的dplyr 因为这几个包可以非常轻易的使我们从复杂的数据操作中逃离, ...
- HIVE之 DDL 数据定义 & DML数据操作
DDL数据库定义 创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create dat ...
- pandas模块的数据操作
数据操作 数据操作最重要的一步也是第一步就是收集数据,而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问,第二种就是需要到网站的API处获取数据或者网页上爬取数据, ...
- Appium+python自动化(三十)- 实现代码与数据分离 - 数据配置-yaml(超详解)
简介 本篇文章主要介绍了python中yaml配置文件模块的使用让其完成数据和代码的分离,宏哥觉得挺不错的,于是就义无反顾地分享给大家,也给大家做个参考.一起跟随宏哥过来看看吧. 思考问题 前面我们配 ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- Redis 安装,配置以及数据操作
Nosql介绍 Nosql:一类新出现的数据库(not only sql)的特点 不支持SQL语法 存储结构跟传统关系型数据库中那种关系表完全不同,nosql中存储的数据都是k-v形式 Nosql的世 ...
- MySQL 数据操作与查询笔记 • 【第1章 MySQL数据库基础】
全部章节 >>>> 本章目录 1.1 数据库简介 1.1.1 数据和数据库定义 1.1.2 数据库发展阶段 1.1.3 数据库系统组成 1.1.4 关系型数据库 1.2 M ...
随机推荐
- 汇农PC个人中心总结
1. 技巧总结 1. 使用 padding 编写灵活的 登录 | 注册, '|' 竖线, 参考: http://www.imooc.com/learn/710 font-size: 0; border ...
- trove最新命令简单分类解析
usage: trove [--version] [--debug] [--service-type <service-type>] [--service-name <service ...
- public static void speckOnWin7(string text),在win7中读文字
public static void speckOnWin7(string text) { //洪丰写的,转载请注明 try { string lsSource = ""; ...
- Ubuntu 14.04 登陆界面循环问题解决
今天手贱startx然后虚拟机就卡死了,再开输过密码就无限跳到登陆界面,其他账户可用.怀疑/home未挂载. 解决方法:(alf改成你的用户名) $ cd ~$ sudo chown alf:alf. ...
- Linux网络常用头文件说明
sys/types.h:数据类型定义 sys/socket.h:提供socket函数及数据结构 netinet/in.h:定义数据结构sockaddr_in arpa/inet.h:提供IP地址转换函 ...
- c# base和this在构造函数中的应用
构造函数可以使用 base 关键字来调用基类的构造函数.例如: public class Manager : Employee{ public Manager(int annualSalary) : ...
- 排序 之 快排、归并、插入 - <时间复杂度>----掌握思想和过程
俗话说:天下武功无坚不破,唯快不破.对于算法当然也是要使用时间最短.占用空间最小的算法来实现了. 注意:我代码里面打的备注仅供参考,建议不要背模板(因为没有固定的模板),可以写一个数列按着代码跑两圈或 ...
- js---疑点代码段解析
function count() { var arr = []; for (var i=1; i<=3; i++) { console.log("iii---"+i); ar ...
- oracle中关于Oracle Database 11g Express Edition 打不开的问题
报的错误是http://127.0.0.1:...什么的找不到该文件 如果是127.0.0.1没问题,而且oracle中5个服务没问题,而且oracle可以启动.. 最后的问题是8080端口冲突,如果 ...
- vue实例生命周期
实例生命周期 var vm = new Vue({ data: { a: 1 }, created: function () { // `this` 指向 vm 实例 console.log('a i ...