StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
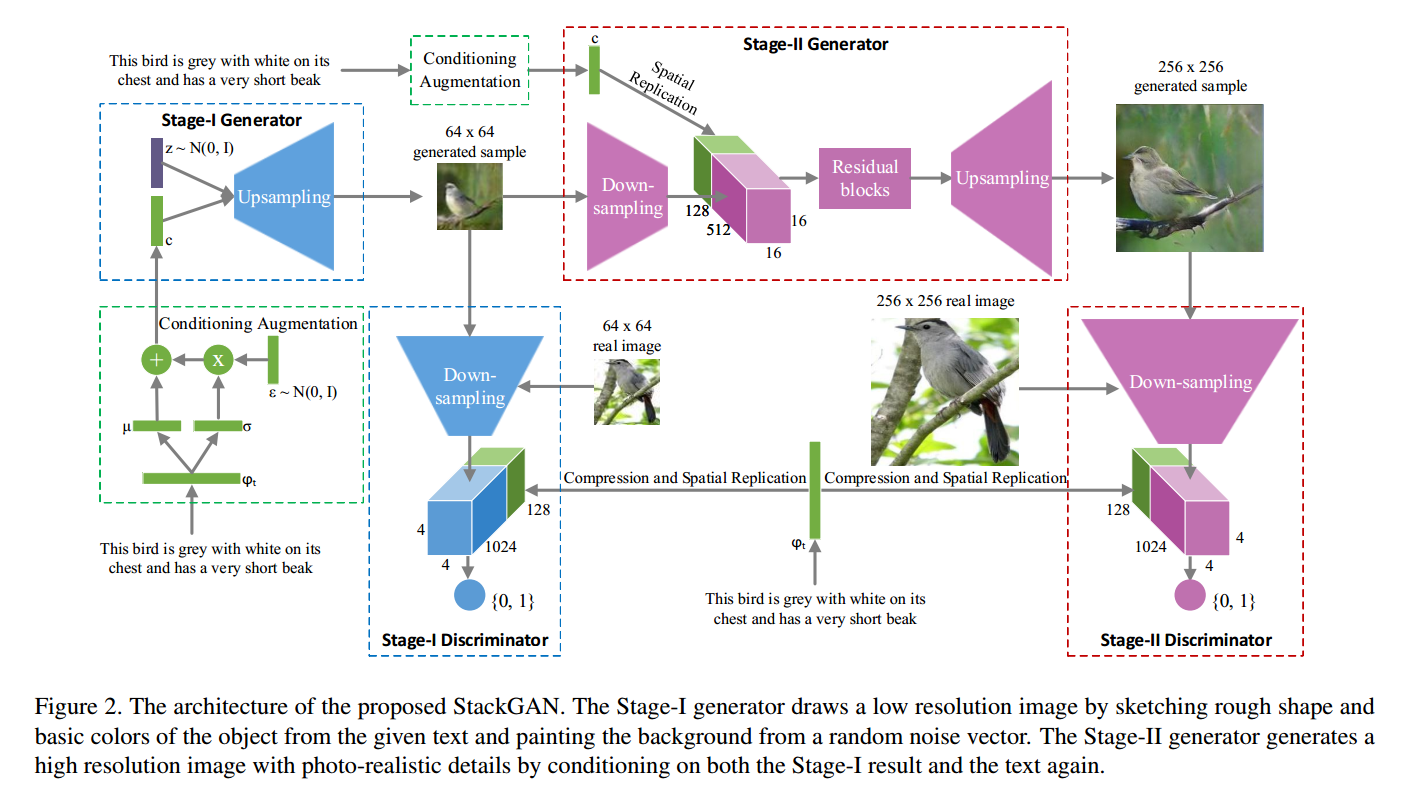
本文将利用 GANs 进行高质量图像生成,分为两个阶段进行,coarse to fine 的过程。据说可以生成 256*256 的高清图像。
基于文本生成对应图像的工作已经有了,比如说 Attribute2Image,以及 最开始的基于文本生成图像的文章等等。

Stacked Generated Adversarial Networks.
所涉及到的两个阶段分别为:
Stage-I GAN:基于文本描述,我们得到初始的形状,基础的色彩;然后从随机 noise 绘出背景分布,产生低分辨率的图像;
Stage-II GAN:通过在此的结合文本描述,进行图像的细致化绘制,产生高质量的 Image。
为了缓解条件文本描述 t 产生的高维的 latent space,但是有限的训练数据,可能导致 latent data manifold 的非连续性,
这对于训练产生器来说,可能不是很好。
为了解决这个问题,作者引入了 条件增强技术 来产生更多的条件变量。从一个独立的高斯分布 N 中随机的采样 latent variables,其均值 $\mu$ 和 对角协方差矩阵 是 text embedding 的函数。所提出的公式可以进一步的提升对小的扰动的鲁棒性,并且在给定少量 image-text pairs 的条件下,产生更多的训练样本。为了进一步的提升平滑性,给产生器的目标函数,添加了一个正则化项:

其中,上式就是 标准高斯分布 和 条件高斯分布的 KL-散度。
基于高斯条件变量 c0,阶段一的 GAN 迭代的进行两个目标函数的训练:

第二个阶段的 GAN 和第一阶段的非常类似。

不同的地方,在于产生器不再以 noise Z 作为输入,而是 s0 = G0(z,c0)。





虽然整体来说,并没有太多的创新,不过这个实验结果,的确是非常 impressive。
启发:
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记的更多相关文章
- (PatchGANs)Pecomputed Real-time Texture Synthesis With Markovian Generative Adversarial Networks
Introduction: Deconvolution; Computational costs; Strided convolutional nets; Markov patches; 1. Q ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
- AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记 这 ...
- 《StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN》论文笔记
出处:arxiv 2016 尚未出版 Motivation 根据文字描述来合成相片级真实感的图片是一项极具挑战性的任务.现有的生成手段,往往只能合成大体的目标,而丢失了生动的细节信息.StackGAN ...
- 论文笔记之:Generative Adversarial Text to Image Synthesis
Generative Adversarial Text to Image Synthesis ICML 2016 摘要:本文将文本和图像练习起来,根据文本生成图像,结合 CNN 和 GAN 来有效的 ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- CSAGAN:LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network - 1 - 论文学习
ABSTRACT 在本文中,我们探讨了从线条生成逼真的人脸图像的任务.先前的基于条件生成对抗网络(cGANs)的方法已经证明,当条件图像和输出图像共享对齐良好的结构时,它们能够生成视觉上可信的图像.然 ...
- 论文笔记:Variational Capsules for Image Analysis and Synthesis
Variational Capsules for Image Analysis and Synthesis 2018-07-16 16:54:36 Paper: https://arxiv.org/ ...
- #论文笔记# [pix2pixHD] High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. "High-Res ...
随机推荐
- NC台网震相走时获取及 HYPOINVERSE 格式读取
HYPOINVERSE格式介绍:http://www.ncedc.org/ftp/pub/doc/man5/ncsn.phase.5 获取网站: http://www.ncedc.org/ncedc/ ...
- 2014年7月份第1周51Aspx源码发布详情
QF万能视频播放器源码 2014-6-30 [VS2010]本源码是一个万能视频播放器源码.可实现各种格式的影片播放功能. 1.点击[开始]按钮,弹出窗口,选择影片路径,确定后即可播放.可拖拽滚 ...
- android原生ExpandableListView
android原生可扩展ExpandableListView就是可以伸缩的listView,一条标题下面有多条内容. 这个list的adapter对的数据要求与普通ListView的数据要求也有一些差 ...
- Android实战技巧:ViewStub的应用
在开发应用程序的时候,经常会遇到这样的情况,会在运行时动态根据条件来决定显示哪个View或某个布局.那么最通常的想法就是把可能用到的View都写在上面,先把它们的可见性都设为View.GONE,然后在 ...
- 关于HTML标签那些事儿
关于html相信对于每一个互联网从业者来说实在熟悉不过的一个名词,特别是web前端工程师来说更是基础中的基础.html是hyper text markup language的首字母缩写,翻译过来就是超 ...
- [转]透过 Linux 内核看无锁编程
非阻塞型同步 (Non-blocking Synchronization) 简介 如何正确有效的保护共享数据是编写并行程序必须面临的一个难题,通常的手段就是同步.同步可分为阻塞型同步(Blocking ...
- UIView---汇总
视图.绘图.贴图.手势.变形.布局.动画.动力.特效 UIBezierPath.UIGestureRecognizer.CGAffineTransform.frame.bounds.center.tr ...
- jdbc mysql写入中文乱码解决
一. 问题 数据库编码:utf8 mysql> create database dbnameDEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; ...
- 网站统计中的数据收集原理及实现(share)
转载自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html 网站数据统计分析工 ...
- web开发实战--弹出式富文本编辑器的实现思路和踩过的坑
前言: 和弟弟合作, 一起整了个智慧屋的小web站点, 里面包含了很多经典的智力和推理题. 其实该站点从技术层面来分析的话, 也算一个信息发布站点. 因此在该网站的后台运营中, 富文本的编辑器显得尤为 ...