cloudera learning2:HDFS
存入HDFS的文件会按块(block)划分,默认每块128MB。默认1个block还有2个备份。备份增加了数据的可靠性和提高计算效率(数据本地化)。
HDFS部署可选择不支持HA,也可选择支持HA。
NameNode内存中有metadata,metadata里主要记录的信息包括:file location,ownership,permissions,block's name and location。
metadata持久化在fsimage文件中,每次NameNode启动时加载到内存。Block location的信息并不存在fsimage中,而是启动后,dataNode定时发给NameNode.
对metadata进行的操作不仅保留在内存中,同时也会写到edit log文件中。当NameNode关闭后,内存中的metadata会消失,下次启动时,会动过edit log一条条还原所有的修改,这个过程导致NameNode启动非常的慢,后来增加了SecondaryNameNode,NameNode会定期的把fsimage和edit log传给Secondary NameNode. Secondary NameNode合并fsimage和log成为新的fsimg并传回NameNode,这样下次启动的时候,就可以只读fsimage了,大大减少启NameNode启动时间。每次SecondaryNameNode对fsimage的update叫做一次checkpoint。
SecondaryNameNode并不是NameNode的failover Node,只是它的“小秘书”。
SecondaryNameNode只在非HA的模式下存在,应该安装在与NameNode不同的机器上,SecondaryNameNode同样需要NameNode一样多的内存。
HDFS的HA是为了解决NameNode的单点问题。两个NameNode一个active,一个standby。standby负责checkpoint.
DataNode控制block的访问权限并保持与NameNode的通信。
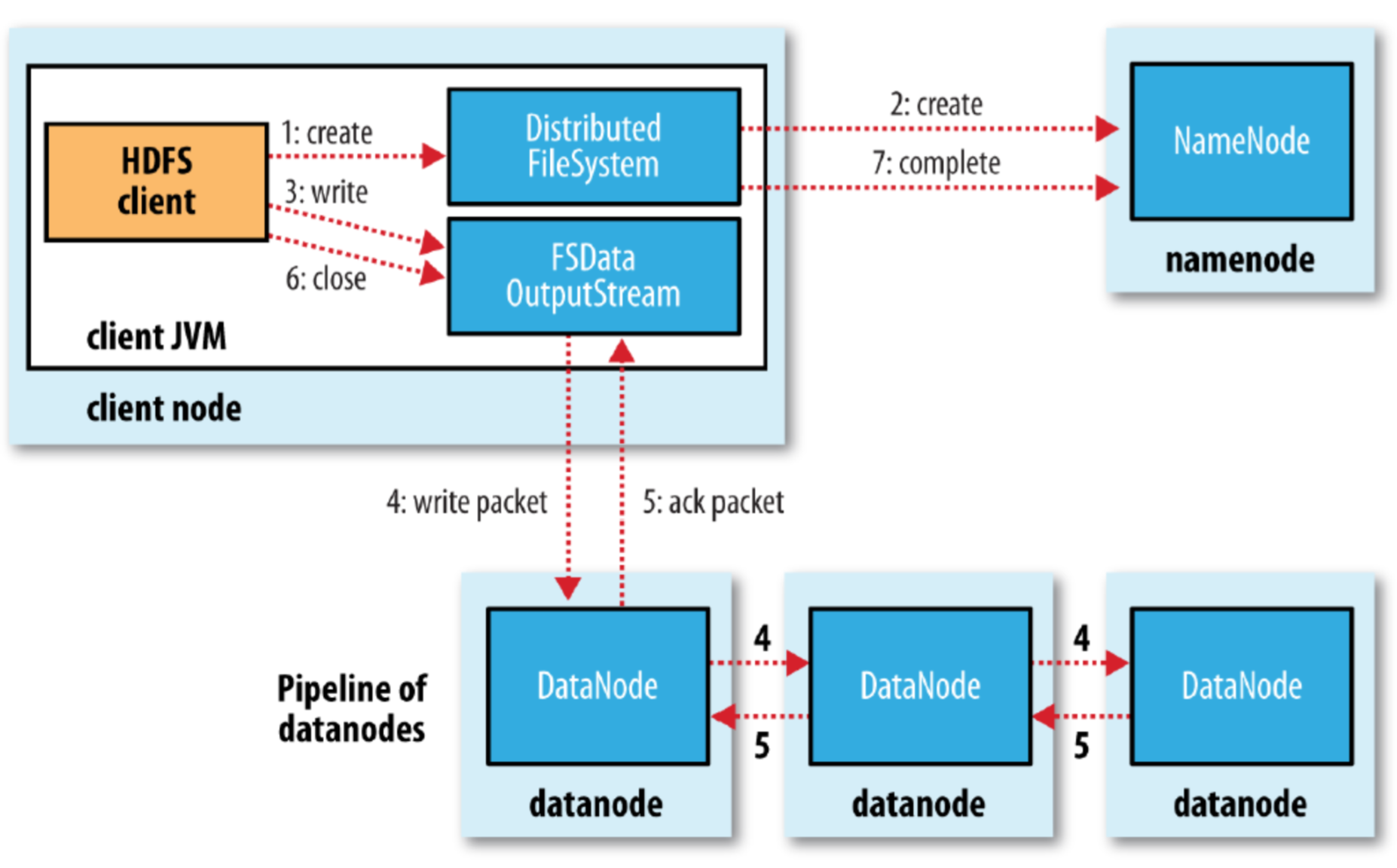
1.client connect to NameNode。
2.NameNode在metadata中为要写入的文件建立一条记录并返回可以写入的blockname和dataNode lists给client。
3.client connect 第一个DataNode,send data。
4.第一个DataNode接收到data后connect第二个DataNode,send data.
5.第二个DataNode又connect第三个dataNode,send data。
6.请求写入结果,并返回给client
7.client向NameNode发送写入完成信息。
在写入的过程中,如果第一个DataNode的pipeline断掉了,会有一个新的pipline建立起来,向第二个dataNode继续写。NameNode会继续找新的dataNode进行备份。
在block被写入时,client会对每一个block计算checksum同时发给dataNode,从而保持数据的完整性。
HDFS读数据流程:

1.client connect to NameNode。
2.Namenode返回要读出的数据所存放的datanode list(list中datanode的排序安照离client又近到远)和开头的几个block的名字。
3.client链接datanode读取数据,如果第一个datanode失去链接,则client去链接list中下一个datanode。
读取的过程中同样执行checksum。
Hadoop是机架感知的,在配好机架信息的前提下,hdfs的备份会存放在不同的机架。
DataNode每隔三秒向NameNode发送一次heartbeat,表示自己是health的。如果一段时间内NameNode没有收到某DataNode发送的heartbeat,则可认定这个DataNode lost,NameNode会把改dataNode上存储的blocks再在系统里进行一次备份,保证每个block的3备份。
Data never travels via a Namedata.
NameNode运行时,所有的metadata都在内存中,默认的NameNode堆大小为1G。1G的内存可以hold住1million的hdfs block。
cloudera learning2:HDFS的更多相关文章
- cloudera hbase集群简单思路
文章copy link:http://cloudera.iteye.com/blog/889468 链接所有者保留所有权! http://www.csdn.net/article/2013-05-10 ...
- hadoop cdh 4.5的安装配置
春节前用的shark,是从github下载的源码,自己编译.shark的master源码仅支持hive 0.9,支持hive 0.11的shark只是个分支,不稳定,官方没有发布release版,在使 ...
- Apache Pig处理数据示例
Apache Pig是一个高级过程语言,可以调用MapReduce查询大规模的半结构化数据集. 样例执行的环境为cloudera的单节点虚拟机 读取结构数据中的指定列 在hdfs上放置一个文件 [cl ...
- Hadoop-Impala学习笔记之入门
CDH quickstart vm包含了单节点的全套hadoop服务生态,可从https://www.cloudera.com/downloads/quickstart_vms/5-13.html下载 ...
- cdh日常维护常见问题及解决方案
为数据节点添加新硬盘 - 挂载硬盘到指定文件夹.如`/dfs_diskb`: - 打开cloudera manager -> hdfs -> 配置 -> DataNode -> ...
- 《ProgrammingHive》阅读笔记-第二章
书本第二章的一些知识点,在cloudera-quickstart-vm-5.8.0-0上进行操作. 配置文件 配置在/etc/hive/conf/hive-site.xml文件里面,采用mysql作为 ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- CDH 5.16.1 离线部署 & 通过 CDH 部署 Hadoop 服务
参考 Cloudera Enterprise 5.16.x Installing Cloudera Manager, CDH, and Managed Services Installation Pa ...
- Hello World on Impala
Cloudera Impala 官方教程 <Impala Tutorial>,解说了Impala一些基本操作,但操作步骤前后缺少连贯性,本文节W选<Impala Tutorial&g ...
随机推荐
- 使用jquery实现单选框、多选框取消选中状态
function radioReset(){ /*方式一*/ /* var radios = $("input[type='radio']"); for (i=0; i<ra ...
- mac tomcat https
一.HTTPS的基本工作原理: HTTPS在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息.TLS/SSL协议不仅仅是一套加密传输的协议 ...
- caffe下训练时遇到的一些问题汇总
1.报错:“db_lmdb.hpp:14] Check failed:mdb_status ==0(112 vs.0)磁盘空间不足.” 这问题是由于lmdb在windows下无法使用lmdb的库,所以 ...
- NYOJ题目20吝啬的国度
-----------------------------------------n-1条边的无向连通图是一棵树,又因为树上两点之间的路径是唯一的,所以解是唯一的.(注意并不一定是二叉树,所以最好采用 ...
- Lex使用指南
Lex是由美国Bell实验室M.Lesk等人用C语言开发的一种词法分析器自动生成工具,它提供一种供开发者编写词法规则(正规式等)的语言(Lex语言)以及这种语言的翻译器(这种翻译器将Lex语言编写的规 ...
- 3.Java异常进阶
3.JAVA异常进阶 1.Run函数中抛出的异常 1.run函数不会抛出异常 2.run函数的异常会交给UncaughtExceptionhandler处理 3.默认的UncaughtExceptio ...
- MVC和WebForm 中国省市区三级联动
MVC和WebForm是微软B/S端的两条腿,两种不同的设计理念,相对来说MVC更优于WebForm对于大数据的交互,因为WebForm是同一时间传输所有数据,而MVC它只是传输所用到的数据,更精确, ...
- div宽高设置为百分比
如果你将div的width和height设置为百分比,但是发现页面都不见了,这是因为父标签也要设置为百分比,也就是说body和html的宽高也需要设置为百分比 #containter{ width:1 ...
- RUDP之三 —— Virtual Connection over UDP
原文链接 原文:http://gafferongames.com/networking-for-game-programmers/virtual-connection-over-udp/ Introd ...
- Sharepoint页面项目展示画廊纯前端实现,后端用list/library简单维护
需求背景: Sharepoint页面项目展示画廊.图片+文字,要求图片与文字用Sharepoint Library维护,然后在sharepoint页面上被调用,生成项目展示画廊. 解决方案(纯前端), ...