三 Buffer
使用Buffer一般遵循以下四个步骤
- 写入数据到Buffer
- 调用flip()
- 从Buffer中读取数据
- 调用clear()或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据,一旦要读取数据,需要通过flip()将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer到所有数据。
一旦读取完所有到数据,就需要清空缓冲区,让它可以再次被写入。
- claer():清空所有缓冲区。
- compact():只会清除已经读过的数据。任何未读取的数据都被移动到缓冲区的起始处,新写入的数据将放在缓冲区未读数据的后面。
public class FileChannelDemo{
public static void main(String[] args) throws Exception {
RandomAccessFile rFile = new RandomAccessFile("D:\\data.txt","rw");
FileChannel inChannel = rFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate();
int bytesRead = inChannel.read(buf); //
while(bytesRead != -){
System.out.println("Read "+bytesRead);
buf.flip();//
while(buf.hasRemaining()){
System.out.println((char)buf.get());//
}
buf.clear();//
bytesRead = inChannel.read(buf);
}
rFile.close();
}
}
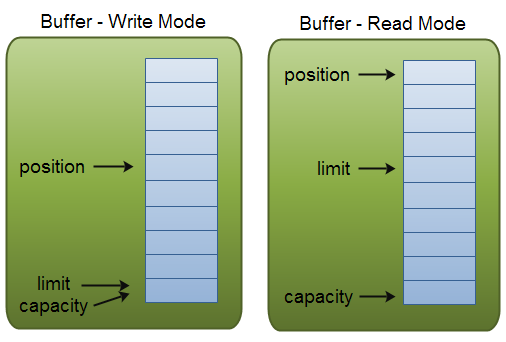
Buffer的capacity,position和limit
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被装成NIO Buffer对象,并提供一组方法,用开方便的访问该块内存。
Buffer提供了三个属性
- capacity
- position
- limit
position和limit的含义取决于Buffer处于读模式还是写模式。不管Buffer处在什么位置,capacity含义总是一样的。
capacity
作为一个内存块,Buffer有一个固定的大小值,一般创建Buffer时初始化写入-->ByteBuffer.allocate(capacity),你只能往capacity里写byte、long、char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续往里面写数据
pisition
当你写数据到Buffer中,position表示当前的位置。初始位置的position值为0,当一个byte、long等数据写到Buffer后,position会向前移动到下一个可插入数据的Buffer单元。
position最大可为capacity-1(因为position的初始值为0)
当读取数据时,也是从某个特定位置读,当Buffer从写模式切换到读模式,position会被重置为0,当从Buffer的position处读取数据时,position向前移动到下一个可读位置。
limit
在写模式中,Buffer的limit表示你最多往Buffer中写多少数据。写模式下,limit=capacity
在读模式中,limit表示你最多能读多少数据。因此,当切换读模式,limit会被设置成写模式下的position值(你能读到之前写入的所有数据)
Buffer的类型
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
如你所见,这些Buffer类型代表了不同的数据类型。换句话说,就是可以通过char,short,int,long,float 或 double类型来操作缓冲区中的字节。
MappedByteBuffer 有些特别,在涉及它的专门章节中再讲。
Buffer的分配
想要获得一个Buffer对象首先要进行分配。每一个Buffer类都有一个allocate()方法
下面是一个分配48字节的capacity的ByteBuffer
ByteBuffer buf = ByteBuffer.allocate();
这是一个可储存1024字符的CharBuffer
CharBuffer buf = CharBuffer.allocate();
向Buffer中写数据
- 从Channel中写到Buffer。
- 通过Buffer的put()写到Buffer中
从Channel写到Buffer
int bytesRead = inChannel.read(buf);
通过put方法
buf.put(123);
flip()方法
该方法是将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值(position表示标记读的位置,limit表示之前写进多少个字节等---》现在能读多少个字节)
从Buffer中读取数据
- 从Buffer中读取数据到Channel
- 使用get()方法从Buffer中读取数据
从Buffer读取数据到Channel的例子:
//read from buffer into channel.
int bytesWritten = inChannel.write(buf);
使用get()方法从Buffer中读取数据的例子
byte aByte = buf.get();
rewind()方法
Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据。limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)。
clear()和compact()
一旦读完Buffer中的数据,需要让Buffer准备好再次被写入,可以通过clear()或者compact()来完成。
如果调用的是clear(),position将被设为0,limit将被设为capacity的值,换句话说,Buffer被清空来,Buffer中的数据并未清除,只说这些标记告诉我们可以从哪里开始往Buffer中写数据了。如果里面还有数据,调用clear(),这些数据将被遗忘,意味着不再有任何标记会告诉你哪些数据被读过,哪些没有。
如果Buffer中未读的数据,并且以后还需要,那么使用compact()方法。
compact方法将所有未读的数据copy到Buffer起始处,然后将position设到最后一个未读数据的后面。limit属性仍然和clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
mark()与reset()方法
通过Buffer.mark()方法,可以标记Buffer中的一个特定的position,之后可以通过调用Buffer.reset()恢复到这个position。①
equals()与compareTo()方法
equals()
- 有相同的类型byte、char等。
- Buffer中剩余的byte、char等的个数相同。
- Buffer中所有剩余的byte、char等相同。
compareTO()
第一个不相等的元素小于另一个Buffer中对应的元素
所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)
转载自并发编程网 – ifeve.com本文链接地址: Java NIO系列教程(三) Buffer
①
import java.io.BufferedInputStream;
import java.io.ByteArrayInputStream;
import java.io.IOException; public class MarkDemo {
public static void main(String[] args) { try {
// 初始化一个字节数组,内有5个字节的数据
byte[] bytes = { 1, 2, 3, 4, 5 };
// 用一个ByteArrayInputStream来读取这个字节数组
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
// 将ByteArrayInputStream包含在一个BufferedInputStream,并初始化缓冲区大小为2。
BufferedInputStream bis = new BufferedInputStream(in, 2);
// 读取字节1
System.out.print(bis.read() + ",");
// 在字节2处做标记,同时设置readlimit参数为1
// 根据JAVA文档mark以后最多只能读取1个字节,否则mark标记失效,但实际运行结果不是这样
System.out.println("mark");
bis.mark(1);
/*
* 连续读取两个字节,超过了readlimit的大小,mark标记仍有效
*/
// 连续读取两个字节
System.out.print(bis.read() + ",");
System.out.print(bis.read() + ",");
// 调用reset方法,未发生异常,说明mark标记仍有效。
// 因为,虽然readlimit参数为1,但是这个BufferedInputStream类的缓冲区大小为2,
// 所以允许读取2字节
System.out.println("reset");
bis.reset(); /*
* 连续读取3个字节,超过了缓冲区大小,mark标记失效。
* 在这个例子中BufferedInputStream类的缓冲区大小大于readlimit, mark标记由缓冲区大小决定
*/
// reset重置后连续读取3个字节,超过了BufferedInputStream类的缓冲区大小
System.out.print(bis.read() + ",");
System.out.print(bis.read() + ",");
System.out.print(bis.read() + ",");
// 再次调用reset重置,抛出异常,说明mark后读取3个字节,mark标记失效
System.out.println("reset again");
bis.reset();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
三 Buffer的更多相关文章
- 转:Java NIO系列教程(三) Buffer
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的. 缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
- nodejs(三)Buffer module & Byte Order
一.目录 ➤ Understanding why you need buffers in Node ➤ Creating a buffer from a string ➤ Converting a b ...
- Java NIO 之 Buffer(缓冲区)
一 Buffer(缓冲区)介绍 Java NIO Buffers用于和NIO Channel交互. 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels. Bu ...
- Java NIO:NIO概述
Java NIO:NIO概述 在上一篇博文中讲述了几种IO模型,现在我们开始进入Java NIO编程主题.NIO是Java 4里面提供的新的API,目的是用来解决传统IO的问题.本文下面分别从Java ...
- (转载)Java NIO:NIO概述(一)
Java NIO:NIO概述 在上一篇博文中讲述了几种IO模型,现在我们开始进入Java NIO编程主题.NIO是Java 4里面提供的新的API,目的是用来解决传统IO的问题.本文下面分别从Java ...
- ESP8266---TCP Client
ESP8266WiFi库里面还有其他重要内容,比如跟http相关的 WiFiClient.WiFiServer,跟https相关的 WiFiClientSecure.WiFiServerSecure ...
- NIO-BufferAPI
一 核心要素 capacity (容量):不能为负,不可更改:就是buffer的长度(buffer.length) limit (限制):指第一个不可被读入缓冲区元素的位置:不可为负,若positio ...
- JAVA NIO系列(三) Buffer 解读
缓冲区分类 NIO中的buffer用于和通道交互,数据是从通道读入缓冲区,从缓冲区中写入通道的.Buffer就像一个数组,可以保存多个类型相同的数据.每种基本数据类型都有对应的Buffer类: 缓冲区 ...
- Java NIO系列教程(三) Buffer(转)
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的. 缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
随机推荐
- [ActionScript 3.0] 对数组中的元素进行排序Array.sort()的方法
对数组中的元素进行排序. 此方法按 Unicode 值排序. (ASCII 是 Unicode 的一个子集.) 默认情况下,Array.sort()按以下方式进行排序: 1. 排序区分大小写(Z优先于 ...
- CentOS7-Minimal1708安装设置python3
使用 python -V 命令查看一下是否安装Python然后使用命令 which python 查看一下Python可执行文件的位置可见执行文件在/usr/bin/ 目录下,切换到该目录下执行 ll ...
- redis中存储小数
在做一个活动的需求时,需要往redis中有序的集合中存储一个小数,结果发现取出数据和存储时的数据不一致 zadd test_2017 1.1 tom (integer) zrevrange test_ ...
- @functools.wrapes
保证被装饰函数的__name__属性不变
- falsk 请求钩子
请求钩子是通过装饰器的形式实现,Flask支持如下四种请求钩子:before_first_request在处理第一个请求前执行before_request在每次请求前执行如果在某修饰的函数中返回了一个 ...
- 原生js 实现旋转木马
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 在Mondrian Virtual OLAP Cube中观察星座模型多事实表度量值的聚合
这样设置的Schema文件会怎么样呢?用Saiku预览一下. 如果这时候想同时引用两个项目进行计算就会出问题了.那么这种情况怎么解决? 参考网上一段实现思路 <VirtualCube name= ...
- 干掉Vivado幺蛾子(2)-- 快速替换debug probes
目录 1. 什么是ECO 2. 操作步骤 参考文献: 我们做项目,进入找bug阶段时,需要用ILA捕获相关的信号.之前我做项目,每改动一次探针(debug probes),都要重新综合.实现,通常要花 ...
- [转] kerberos安装配置与使用
[From] https://blog.csdn.net/lovebomei/article/details/79807484 1.Kerberos协议: Kerberos协议主要用于计算机网络的身份 ...
- FreeRTOS-06任务运行时间信息统计
根据正点原子FreeRTOS视频整理 单片机:STM32F207VC FreeRTOS源码版本:v10.0.1 * 1. 要使用vTaskGetRunTimeStats()函数,需满足以下条件: * ...