day5-python中的序列化与反序列化-json&pickle
一、概述
玩过稍微大型一点的游戏的朋友都知道,很多游戏的存档功能使得我们可以方便地迅速进入上一次退出的状态(包括装备、等级、经验值等在内的一切运行时数据),那么在程序开发中也存在这样的需求:比较简单的程序,对象的处理都在内存中直接实现,程序退出后对象就消失;但对于功能需求稍微拔高一点的程序来讲,很多时候往往需要需要把对象持久化保存起来,以便下次启动程序时还能直接进入最后一次的状态。
这个处理过程在程序开发中就是序列化与反序列化。
二、序列化与反序列化的概念
概述中引入了一个游戏存档的场景,本质上是游戏程序把运行时的对象转换成可以持久存储的对象,然后保存(到数据库)的过程。还是以这个为引子来讲讲序列化与反序列化的概念(以下概念整合自网络资料,个人认为解释比较到位了)。
- 序列化
我们把程序运行时内存中的数据结构或对象转换成二进制串字节序列的过程称之为序列化,这样我们就可以对对象实现持久化存储或网络传输。
请注意以下重点:
1. 序列化的对象
是内存中的数据结构或对象,也就是我们在程序运行中操纵的一切对象(这是一个面向对象的时代,当然包括很多地方说的变量啦~)
2. 序列化后的对象
变为二进制串字节序列,这个不作过多解释,要持久化保存到硬件或进行网络传输,必须是bytes对象。
3. 序列化的目的
想想自己玩游戏时存档的那种便利性和必要性把,有些对象必须能够持久化地保存(一般文件,数据库,巴拉巴拉…)或进行网络传输(分布式程序),才能满足功能需求。 - 反序列化
反序列化就是序列化的逆向过程,持久化保存或网络传输数据的最终目的也是为了后续使用,必须可以逆向加载到内存中二次利用,这就是反序列化。
python中的序列化与反序列化模块有json和pickle,下面就来看看怎么玩转它们。
三、json模块
json模块提供了dumps,loads,dump和load四种方法,下面展开来阐述:
- dumps序列化和loads反序列化
dumps和loads是成对出现的:
dumps用于将python中的简单数据类型(典型的是字典和列表,还有字符串)进行json格式encode编码,转换为符合json格式的字符串(返回标准的json格式字符串);
loads则刚好相反,用于把符合json格式的字符串decode成python中特定的数据类型(注意是简单的数据类型,下文会详细解释)。1 >>> import json
2 >>> list1=['a','b','c']
3 >>> print(type(list))
4 <class 'type'>
5
6 #dumps序列化,可以理解为encode json过程
7 >>> print(json.dumps(list1))
8 ["a", "b", "c"]
9 >>> print(type(json.dumps(list1)))
10 <class 'str'> #list dumps处理后变为str类型
11 >>> dict1={'id':'001','name':'Maxwell'}
12 >>> print(type(dict1))
13 <class 'dict'>
14 >>> print(type(json.dumps(dict1)))
15 <class 'str'> #dict经过dumps处理后也变成str类型
16 >>>
17
18 #loads反序列化
19 >>> print(json.loads(json.dumps(list1)))
20 ['a', 'b', 'c']
21 >>> print(json.loads(json.dumps(dict1)))
22 {'id': '001', 'name': 'Maxwell'}
23 >>> print(type(json.loads(json.dumps(list1))))
24 <class 'list'> #把经过json dumps处理过的字符串loads序列化,可还原为原来的数据类型
25 >>> print(type(json.loads(json.dumps(dict1))))
26 <class 'dict'> #把经过json dumps处理过的字符串loads序列化,可还原为原来的数据类型以上代码仅仅是展示loads方法的效果,实际使用中我们可以把符合python中json格式的自定义字符串(比如程序中的输入)转换成特定的数据类型,这样就可以在程序中跑起来:
1 >>> str1='["a", "b", "c"]'
2 >>> print(type(json.loads(str1)))
3 <class 'list'> #反序列化为list
4 >>> print(json.loads(str1))
5 ['a', 'b', 'c']
6 >>> str2='{"id":"001","name":"Maxwell"}'
7 >>> print(json.loads(str2))
8 {'id': '001', 'name': 'Maxwell'}
9 >>> print(json.loads(str2))
10 {'id': '001', 'name': 'Maxwell'}
11 >>> print(type(json.loads(str2)))
12 <class 'dict'> #反序列化为dict注意:通过loads方法反序列化自定义的字符串时,外层的引号必须是单引号,内层的引号是双引号(可以对照dumps后输出的引号是双引号来看),这是python的规范,别问为什么了。
好了,以上展示了dumps和loads的处理过程,我们的目的不是把python中的运行时对象能进行持久化保存或网络传输吗?下面展示通过dumps处理后保存到文本文件和从文本文件中loads出历史保存的数据效果:
(1) dumps序列化后保存1 import json
2 dict1={'id':'001','name':'Maxwell'}
3 with open('dumps.txt','w',encoding='utf-8') as f:
4 f.write(json.dumps(dict1))
5看看保存后的文本文件dumps.txt的内容:
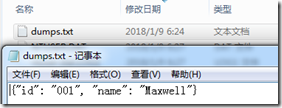
(2) loads反序列化从文件中加载数据1 >>> import json
2 >>> with open('dumps.txt','r',encoding='utf-8') as f:
3 ... content = f.read()
4 >>> print(json.loads(content))
5 {'id': '001', 'name': 'Maxwell'}
6 >>> print(type(json.loads(content)))
7 <class 'dict'> #loads反序列化后成功还原为原来的数据类型dict
8 >>> print(json.loads(content).get('name'))
9 Maxwell #此时可以应用dict的各种大法了
10 >>> print(json.loads(content)['name'])
11 Maxwell - dump序列化和load反序列化
dump和load也是成对出现的,dump可以把python中的特定数据类型(比较多用的还是dict和list)转换为json格式,并直接写入写入一个file-like Object(操作的对象包括未转换的python对象和file-like Object),load则与此相反,可从文件对象中反序列化出python的原生对象出来。1 >>> import json
2 >>> dict1={'id': '001', 'name': 'Maxwell'}
3 >>> with open('dump.txt','w',encoding='utf-8') as f:
4 ... json.dump(dict1,f) #dump序列化,直接操作原生数据类型对象和文件句柄
5 ...
6
7 #load反序列化
8 >>> with open('dump.txt','r',encoding='utf-8') as f:
9 ... content = json.load(f) #注意这里先用一个对象把load的内容保存起来,否则关闭文件后就不能再访问了
10 ...
11 >>> print(content)
12 {'id': '001', 'name': 'Maxwell'}
13 >>> print(type(content))
14 <class 'dict'> #成功反序列化成dict
15 >>> print(content['name'])
16 Maxwell #试试dict大法 - (dumps & loads) VS (dump & load)
对比下dumps & loads和dump & load吧:
(1)dumps & loads
只能解决python中可以被json模块处理的对象和json格式字符串之间相互转换的问题,它们操作的对象分别是可以被json模块处理的对象和json格式
字符串。
(2)dump和load
可以理解为json文件处理函数,操作的对象是python中可以被json模块处理的对象和file-like Object,屏蔽或者说省略了json格式字符串这一细节
综合对比起来,如果要通过文件保存或从文件中加载运行时对象,使用dump和load更方便,代码更少;反之如果仅仅需要进行json格式处理,则建议使用dumps和loads。
四、pickle
pickle模块实现了用于对Python对象结构进行序列化和反序列化的二进制协议,与json模块不同的是pickle模块序列化和反序列化的过程分别叫做 pickling 和 unpickling,且转换前后是二进制字节码,不再是简单的可阅读的字符串:
- pickling: 是将Python对象转换为字节流的过程;
- unpickling: 是将字节流二进制文件或字节对象转换回Python对象的过程;
- dumps序列化和loads反序列化
与jsonddumps和loads非常类似,不同的就在于转换后的格式是二进制字节码1 >>> import pickle
2 >>> dict1={'id':'001','name':'Maxwell'}
3 >>> pickle.dumps(dict1)
4 b'\x80\x03}q\x00(X\x02\x00\x00\x00idq\x01X\x03\x00\x00\x00001q\x02X\x04\x00\x00\
5 x00nameq\x03X\x07\x00\x00\x00Maxwellq\x04u.' #序列化成二进制字节码
6 >>> print(type(pickle.dumps(dict1)))
7 <class 'bytes'>
8 >>> pickle.loads(pickle.dumps(dict1)) #成功反序列化
9 {'id': '001', 'name': 'Maxwell'}
10 >>> print(type(pickle.loads(pickle.dumps(dict1))))
11 <class 'dict'>
12 >>> pickle.loads(pickle.dumps(dict1))['name']
13 'Maxwell'由于pickle序列化后数据类型变为二进制字节码,因此在保存文件和读取文件时需要分别以wb和rb模式打开:
1 >>> import pickle
2 >>> dict1={'id':'001','name':'Maxwell'}
3 >>> with open('picklt.txt','wb') as f: #以wb模式打开文件后写入dumps内容
4 ... f.write(pickle.dumps(dict1))
5 ...
6
7 >>> with open('picklt.txt','rb') as f: #以rb模式打开后读取内容
8 ... data = pickle.loads(f.read())
9 ...
10 >>> print(data)
11 {'id': '001', 'name': 'Maxwell'}通过dumps写入后,由于是二进制字节码,所以打开会有乱码显示了:

- dump序列化和load反序列化
同理,pickle的dump序列化和load反序列化也和json的dump、load非常类似,还是看相同的例子吧:1 >>> import pickle
2 >>> dict1={'id': '001', 'name': 'Maxwell'}
3 >>> with open('pickle.txt','wb') as f:
4 ... pickle.dump(dict1,f)
5 ...
6 >>> with open('pickle.txt','rb') as f:
7 ... content = pickle.load(f)
8 ...
9 >>> print(content)
10 {'id': '001', 'name': 'Maxwell'}
11 >>> print(content['name'])
12 Maxwelldump保存写入的文件内容:

- 序列化函数
(1)序列化1 # !/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 __author__ = 'Maxwell'
4
5 import pickle
6
7 def sayhi(name):
8 print('Hello:', name)
9
10 info = {'name':'Maxwell', 'func':sayhi} #func对应的值是一个函数
11
12 with open('test.txt', 'wb') as f:
13 data = pickle.dumps(info)
14 f.write(data)
15(2)反序列化
1 # !/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 __author__ = 'Maxwell'
4
5 import pickle
6
7 def sayhi(name): #此处需要定义出函数,因为它不能被直接加载到内存中
8 print('Hello:',name)
9
10 with open('test.txt','rb') as f:
11 data = pickle.loads(f.read())
12
13 print(data.get('name'))
14 data.get('func')('Tom')
15
16 结果输出:
17 Maxwell
18 Hello: Tom
四、json和pickle对比
- JSON是一种文本序列化格式(它输出的是unicode文件,大多数时候会被编码为utf-8),而pickle是一个二进制序列化格式;
- JOSN处理的是python对象和字符串的转换问题,是我们可以读懂的数据格式,而pickle是二进制格式,我们无法读懂;
- JSON是与特定的编程语言或系统无关的,且它在Python生态系统之外被广泛使用,而pickle使用的数据格式是特定于Python的;
- 默认情况下,JSON只能表示Python内建数据类型,而且是仅限于比较简单的数据类型,如dict,list和str,对于自定义数据类型需要一些额外的工作来完成;pickle可以直接表示大量的Python数据类型,包括自定数据类型(其中,许多是通过巧妙地使用Python内省功能自动实现的;复杂的情况可以通过实现specific object API来解决)
以上内容摘自http://www.cnblogs.com/yyds/p/6563608.html
day5-python中的序列化与反序列化-json&pickle的更多相关文章
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- python类库32[序列化和反序列化之pickle]
一 pickle pickle模块用来实现python对象的序列化和反序列化.通常地pickle将python对象序列化为二进制流或文件. python对象与文件之间的序列化和反序列化: pi ...
- python中的序列化和反序列化
~~~~~~滴滴,,什么是序列呢?可以理解为序列就是字符串.序列化的应用 写文件(数据传输) 网络传输 序列化和反序列化的概念 序列化模块:将原本的字典.列表等内容转换成一个字符串的过程就叫做序列 ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- python操作文件——序列化pickling和JSON
当我们在内存中定义一个dict的时候,我们是可以随时修改变量的内容的: >>> d=dict(name='wc',age=28) >>> d {'name': 'w ...
- Python中的序列化以及pickle和json模块介绍
Python中的序列化指的是在程序运行期间,变量都是在内存中保存着的,如果我们想保留一些运行中的变量值,就可以使用序列化操作把变量内容从内存保存到磁盘中,在Python中这个操作叫pickling,等 ...
- python接口测试之序列化与反序列化(四)
在python中,序列化可以理解为:把python的对象编码转换为json格式的字符串,反序列化可以理解为:把json格式 字符串解码为python数据对象.在python的标准库中,专门提供了jso ...
- Jackson序列化和反序列化Json数据完整示例
Jackson序列化和反序列化Json数据 Web技术发展的今天,Json和XML已经成为了web数据的事实标准,然而这种格式化的数据手工解析又非常麻烦,软件工程界永远不缺少工具,每当有需求的时候就会 ...
- 浅谈C#中的序列化与反序列化
今天我利用这篇文章给大家讲解一下C#中的序列化与反序列化.这两个概念我们再开发中经常用到,但是我们绝大部分只用到了其中的一部分,剩下的部分很多开发人员并不清楚,甚至可以说是不知道.因此我希望通过这篇文 ...
随机推荐
- windows下使用IIS创建git服务
Bonobo Git Server 下载地址: https://bonobogitserver.com/ 安装方法:https://bonobogitserver.com/install/ 配置简单, ...
- django博客项目11
.....................
- centos7 只需两步安装rabbitmq
# yum -y install rabbitmq-server # systemctl start rabbitmq-server && systemctl enable rabb ...
- 简明python教程三-----函数
函数通过def关键字定义.def关键字后跟一个函数的表标识符名称,然后跟一对圆括号. 圆括号之中可以包括一些变量名,该行以冒号结尾.接下来是一块语句,它们是函数体. def sayHello(): p ...
- Flash本地共享对象 SharedObject
以下内容是对网上一些资料的总结 Flex SharedObject 介绍(转自http://www.eb163.com/club/thread-3235-1-1.html): Flash的本地共享对象 ...
- MyBatis For .NET学习- 初识MyBatis
MyBatis的框架. Introduction MyBatis本是apache的一个开源项目iBatis,2010年这个项目由 apache software foundation迁移到了googl ...
- 144. Binary Tree Preorder Traversal (二叉树前序遍历)
Given a binary tree, return the preorder traversal of its nodes' values. For example:Given binary tr ...
- cdoj1341卿学姐与城堡的墙
地址:http://acm.uestc.edu.cn/#/problem/show/1341 题目: 卿学姐与城堡的墙 Time Limit: 2000/1000MS (Java/Others) ...
- 菩提树下的杨过.Net 的《hadoop 2.6全分布安装》补充版
对菩提树下的杨过.Net的这篇博客<hadoop 2.6全分布安装>,我真是佩服的五体投地,我第一次见过教程能写的这么言简意赅,但是又能比较准确表述每一步做法的,这篇博客主要就是在他的基础 ...
- 20145219 《Java程序设计》实验四 Android开发基础设计实验报告
20145219 <Java程序设计>实验四 Android开发基础设计实验报告 实验内容 安装Andriod Studio并配置软件 使用Andriod Studio软件实现Hello ...