Directed Graphs
有向图
Introduction
就是边是有方向的,像单行道那样,也有很多典型的应用。

点的出度指从这个点发出的边的数目,入度是指向点的边数。当存在一条从点 v 到点 w 的路径时,称点 v 能够到达点 w ,但要注意这并不意味着点 w 可以到达点 v 。
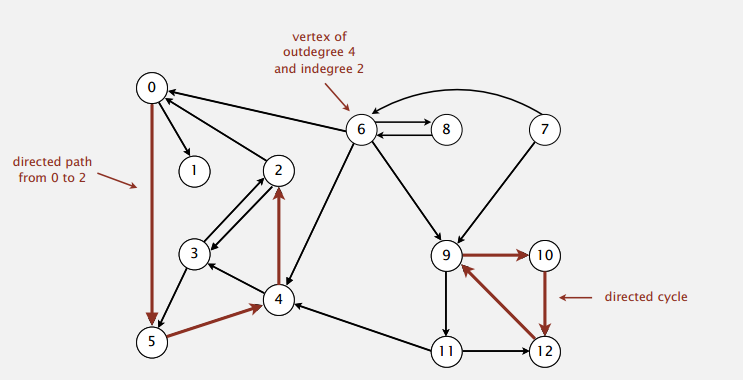
Digraph API
先给出表示有向图的 API 以及简单的测试用例,booksite-4.2 上可以找到完整的。
API

Sample Client

运行示例
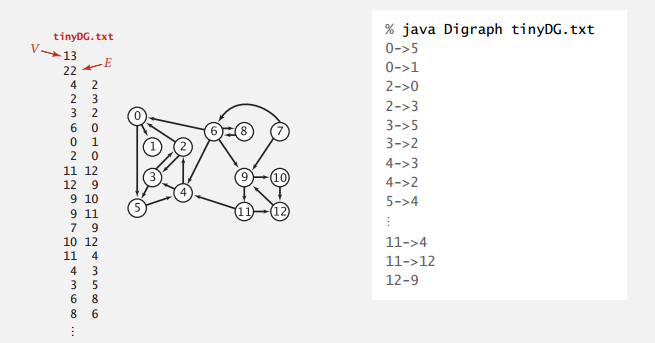
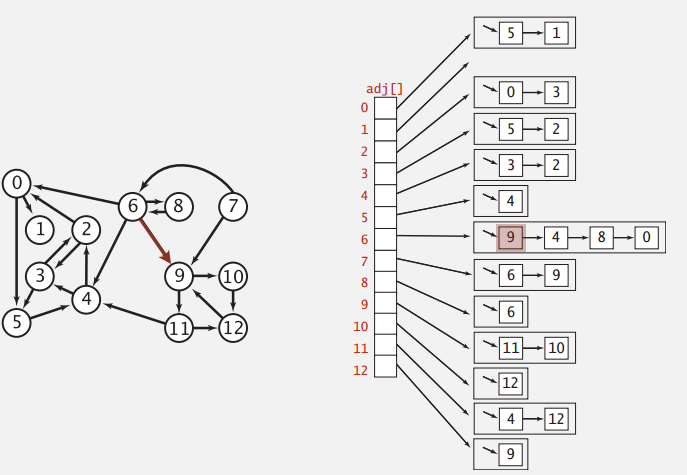
仍然使用邻接表来实现有向图,比无向图还简单其实。
Adjacency-list
Java Implementation
public class Digraph {
private final int V;
private final Bag<Integer>[] adj; // adjacency lists
public Digraph(int V) {
this.V = V;
// create empty graph with V vertices
adj = (Bag<Integer>[]) new Bag[V];
for (int v = 0; v < V; v++) {
adj[v] = new Bag<Integer>();
}
}
// add edge v->w
public void addEdge(int v, int w) {
adj[v].add(w);
}
// iterator for vertices pointing from v
public Iterable<Integer> adj(int v) {
return adj[v];
}
}
用邻接表来表示有向图,类似的内存使用正比于 E+V ,常数时间就能加入新边,判断点 v 到 w 是否有条边需要正比于点 v 出度的时间,遍历从点 v 发出的边也是。
Digraph Search
同样的,可以直接用 Undirected Graphs 提到的 DFS 和 BFS 这两种搜索策略。
DFS
public class DirectedDFS {
private boolean[] marked; // true if path from s
// constructor marks vertices reachable from s
public DirectedDFS(Digraph G, int s) {
marked = new boolean[G.V()];
dfs(G, s);
}
// recursive DFS does the work
private void dfs(Digraph G, int v) {
marked[v] = true;
for (int w : G.adj(v)) {
if (!marked[w]) {
dfs(G, w);
}
}
}
// client can ask whether any vertex is reachable from s
public boolean visited(int v) {
return marked[v];
}
}
示例
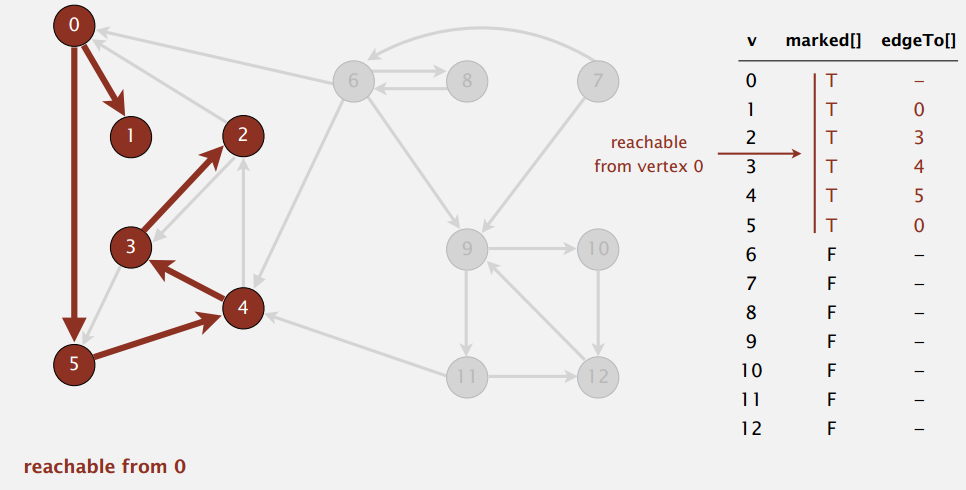
BFS
随便来张图感受一下。
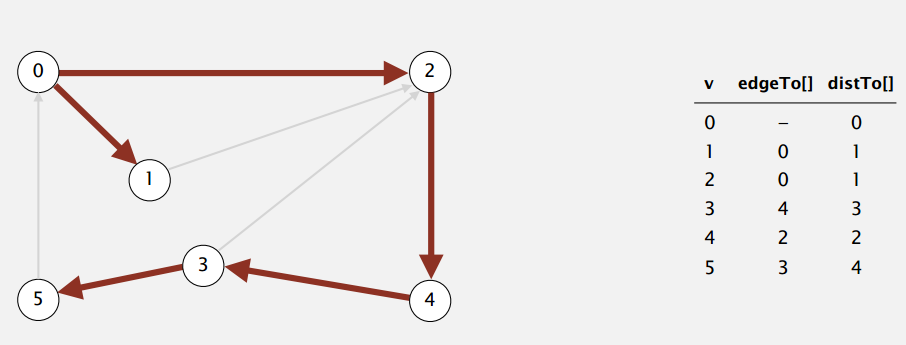
Topological Sort
拓扑排序。就是把有向图整理成箭头都朝同一个方向,像把下面的中间变成右边那种。应用也很广泛啦,比如说大学里某些课要上先修课才行,拓扑排序就可以帮我们安排课程顺序。
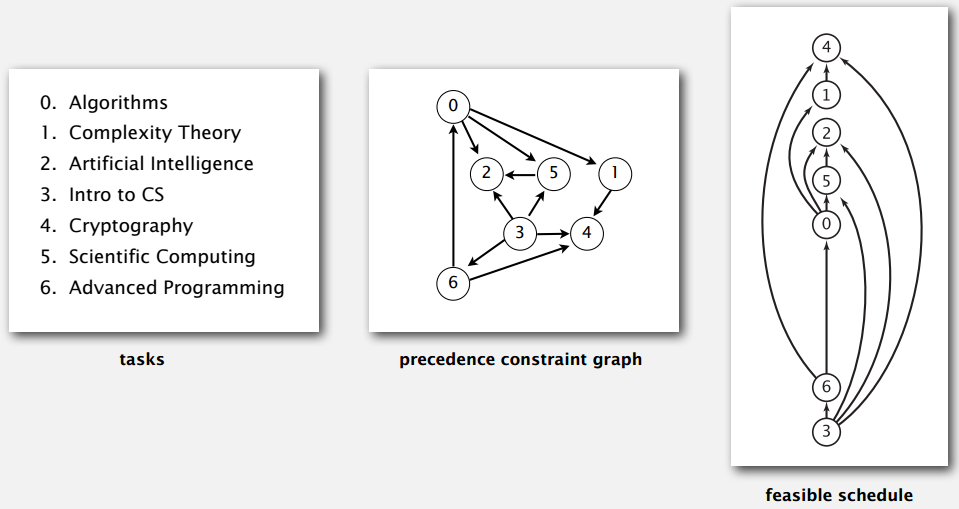
另外,拓扑排序是针对有向无环图(DAG, directed acyclic graph)来说的,设想 a 的完成依赖于 b,b 的完成又依赖于 a ,显然没有解。
Solution
DFS 稍作修改,就可以帮我们完成拓扑排序。因为 DFS 正好只会访问每个顶点一次,如果将 dfs() 参数之一的点保存在一个数据结构中,遍历这个数据结构实际上就能访问图中的所有顶点,遍历的顺序取决于这个数据结构的性质以及是在递归调用之前还是之后进行保存。在典型的应用中,人们感兴趣的是点的以下 3 种排列顺序。
- 前序(Preorder):在递归调用之前将点加入队列。
- 后序(Postorder):在递归调用之后将点加入队列。
- 逆后序(Reverse postorder):在递归调用之后将点压入栈。
前序就是 dfs() 的调用顺序,后序就是点遍历完成的顺序,而逆后序就是拓扑排序。
样图
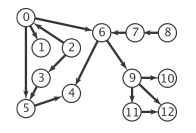
模拟

前序和后序看上图感受一下,对于逆后序就是拓扑排序可以这么想:对于任意边 v->w,在调用 dfs(v) 之时,可能的情况有三种。
- dfs(w) 已经被调用过且返回了(w 已经被标记)。
- dfs(w) 还没有被调用(w 还未被标记),因此 v->w 会直接或间接调用并返回 dfs(w),且 dfs(w) 会在 dfs(v) 返回前返回。
- dfs(w) 已经被调用但还未返回。证明的关键在于,在 DAG 中这种情况是不可能出现的,这是由于递归调用链意味着存在从 w 到 v 的路径,再加上现在的边 v->w 则刚好补成一个环。
所以在 DAG 中只可能有前面两种情况,其中 dfs(w) 都会在 dfs(v) 之前完成,也就是说后序排序中 v 指向的点都会在其前面,那么逆后序就是把 v->w 中的 w 排在 v 后面啦。具体实现把 DFS 改一下就好,加些数据结构存点,完整示例可以参见:DepthFirstOrder.java。
Directed Cycle Detetion
上面提到过,当且仅当有向图没有有向环时,它才有拓扑排序,DFS 也能用于检测图是否含有环。因为系统维护的递归调用的栈表示的正是“当前”正在遍历的有向路径,如果我们遇到了一条边 v->w ,而 w 已经在栈里,就找到了一个环 v->w->v。
Implementation
public class DirectedCycle {
private boolean[] marked;
private int[] edgeTo;
private Stack<Integer> cycle; // 有向环中的所有顶点(如果存在)
private boolean[] onStack; // 递归调用的栈上的所有顶点
public DirectedCycle (Digraph G) {
onStack = new boolean[G.V()];
edgeTo = new int[G.V()];
marked = new boolean[G.V()];
for (int v = 0; v < G.V(); v++) {
if (!marked[v]) {
dfs(G, v);
}
}
}
private void dfs(Digraph G, int v) {
onStack[v] = true; // 递归调用开始时标记为在栈中
marked[v] = true;
for (int w : G.adj(v)) {
if (this.hasCycle()) {
return;
}
else if (!marked[w]) {
edgeTo[w] = v;
dfs(G, w);
}
// v->w 中 w 已经在栈中,保存环 v->w->...->v到 cycle 里
else if (onStack[w]) {
cycle = new Stack<Integer>();
for (int x = v; x != w; x = edgeTo[x]) {
cycle.push(x);
}
cycle.push(w);
cycle.push(v);
}
onStack[v] = false; // 递归调用结束时标记为不在栈中
}
}
public boolean hasCycle() {
return cycle != null;
}
public Iterable<Integer> cycle() {
return cycle;
}
}
Strong Components
强连通。在有向图中,若同时存在路径 v->w 和 w->v,则称点 v 和 w 是强连通的。类似的,这显然也是一个等价关系,满足:
- symmetric: 自反性, v 和 v 自身是强连通的。
- reflexive: 对称性, v 和 w 强连通,则 w 和 v 强连通。
- transitive: 传递性,如果 v 和 w 强连通,又有 w 和 x 强连通,那么 v 和 x 强连通。
强连通分量也很好理解,就是区域里面的点之间都是强连通的。
Demo
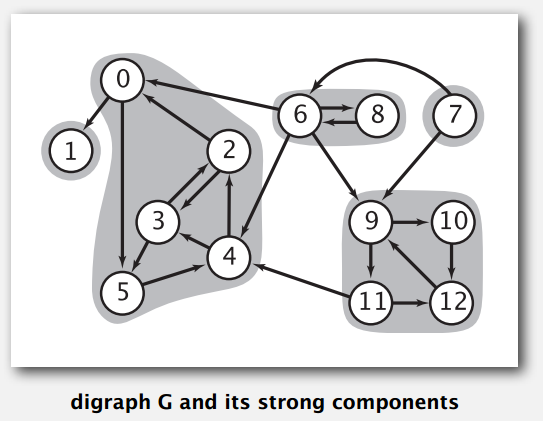
强连通分量可以帮助生物学家理解食物链中能量的流动,帮助程序员组织程序模块等。

在 Undirected Graphs 中提到的连通分量问题,可以用 DFS 预处理图,然后就可以在常数时间回应查询。同样的强连通问题也可以用 DFS 解决,用 kosaraju-sharir 算法,分成两步用两次 DFS。算法思想是计算核心 DAG (把强连通分量当成一个点)的拓扑排序,再按逆拓扑序列对点跑 DFS。我也不知道在说什么,看下面证明。
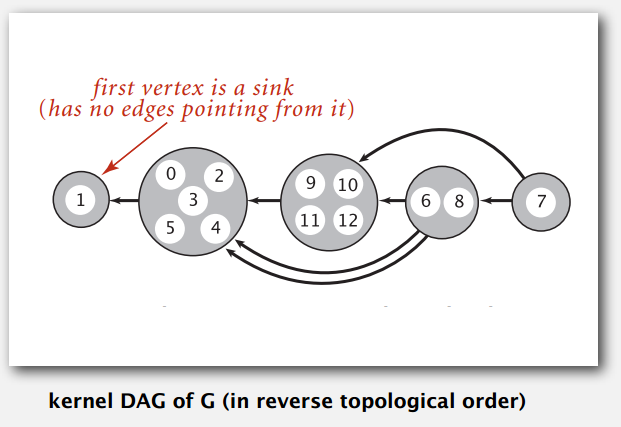
Phase 1
用 DFS 计算图 G 的反向图 \(G^{R}\) (边的方向相反)的逆后序序列。
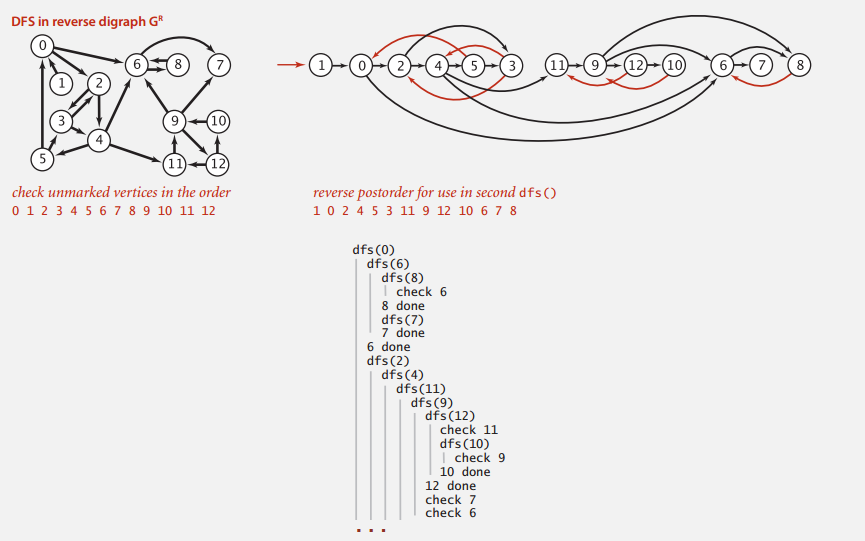
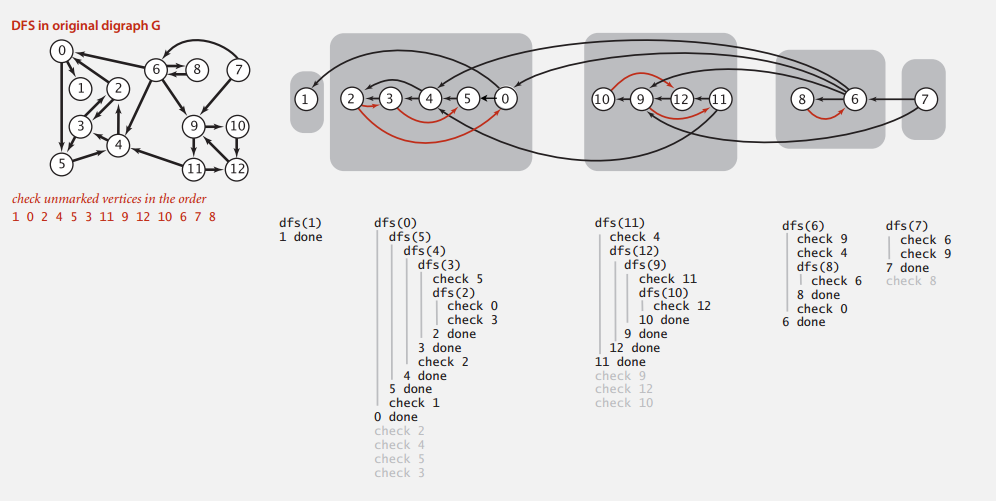
Phase 2
按第一步中的逆后序序列来对图 G 进行 DFS 。
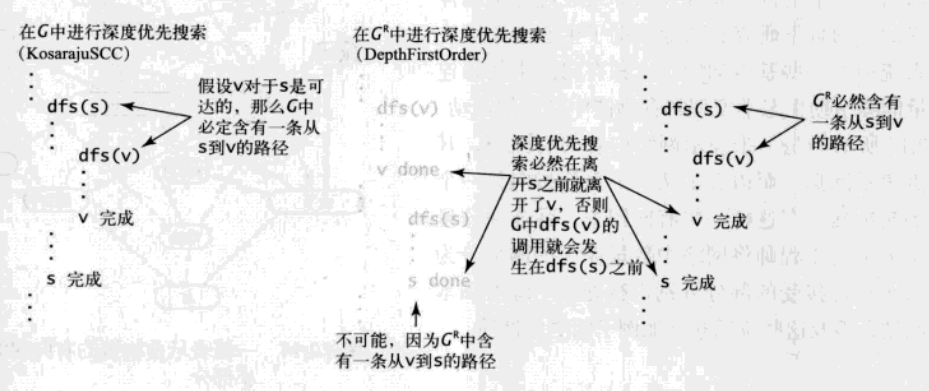
证明
分两点证明该算法的正确性。
第二步构造函数中调用的 dfs(G, s) 会访问每个和 s 强连通的点
反证法。假设某个和点 s 强连通的点 v 没有在 dfs(G, s) 中被访问,那就意味着 marked[v] 为 true,即点 v 在 s 之前就已经被访问过了。又因为两点强连通,故存在着从 v 到 s 的路径,所以访问 v 的时候的 dfs(G, v) 就会调用 dfs(G, s),而不会轮到构造函数来调用。矛盾,得证。
构造函数调用的 dfs(G, s) 所到达的任意点 v 都必然和 s 强连通
v 能被 dfs(G, s) 访问到,说明存在路径 s->v ,那么只要再证明存在路径 v->s 就能说明两点是强连通的。即等价于在 \(G^{R}\) 中找路径 s->v,且是在已知存在路径 v->s 的前提下。因为在 \(G^{R}\) 的逆后序中 v 排在 s 后面,所以 dfs(G, v) 结束得比 dfs(G, s) 早,那就只有两种情况:
- 调用 dfs(G, v) 结束在调用 dfs(G, s) 开始之前。
- 调用 dfs(G, v) 开始在 dfs(G, s) 调用开始之后且结束在 dfs(G, s) 结束之前。
又因为已知存在路径 v->s ,所以第一种情况是不可能的,而第二种则意味着存在路径 s->v,证毕,再来张没什么大用的图。
实现
实现只要对 Undirected Graphs 中的 “Implementation With DFS” 代码稍作修改就好其实。
public class KosarajuSharirSCC {
private boolean[] marked;
private int[] id;
private int count;
public KosarajuSharirSCC(Digraph G) {
marked = new boolean[G.V()];
id = new int[G.V()];
DepthFirstOrder dfs = new DepthFirstOrder(G.reverse());
// 按逆后序进行 DFS
for (int v : dfs.reversePost()) {
if (!marked[v]) {
dfs(G, v);
count++;
}
}
}
private void dfs(Digraph G, int v) {
marked[v] = true;
id[v] = count;
for (int w : G.adj(v)) {
if (!marked[w]) {
dfs(G, w);
}
}
}
public boolean stronglyConnected(int v, int w) {
return id[v] == id[w];
}
}
Directed Graphs的更多相关文章
- Java数据结构——带权图
带权图的最小生成树--Prim算法和Kruskal算法 带权图的最短路径算法--Dijkstra算法 package graph; // path.java // demonstrates short ...
- 3-HOP: A High-Compression Indexing Scheme for Reachability Query
title: 3-HOP: A High-Compression Indexing Scheme for Reachability Query venue: SIGMOD'09 author: Ruo ...
- JSON-LD
RDF RDF用于信息需要被应用程序处理而不是仅仅显示给人观看的场合.RDF提供了一种用于表达这一信息.并使其能在应用程序间交换而不丧失语义的通用框架.既然是通用框架,应用程序设计者可以利用现成的通用 ...
- Markov Random Fields
We have seen that directed graphical models specify a factorization of the joint distribution over a ...
- 【Python排序搜索基本算法】之深度优先搜索、广度优先搜索、拓扑排序、强联通&Kosaraju算法
Graph Search and Connectivity Generic Graph Search Goals 1. find everything findable 2. don't explor ...
- zz A list of open source C++ libraries
A list of open source C++ libraries < cpp | links http://en.cppreference.com/w/cpp/links/libs Th ...
- Leetcode: Graph Valid Tree && Summary: Detect cycle in undirected graph
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), ...
- [zt]Which are the 10 algorithms every computer science student must implement at least once in life?
More important than algorithms(just problems #$!%), the techniques/concepts residing at the base of ...
- Ural1387 Vasya's Dad
Description Vasya's dad is good in maths. Lately his favorite objects have been "beautiful" ...
随机推荐
- Mathematik
Ausdruck auf Deutsch Lösen Problem der Abteilung. 求导. Die Abteilung von 3x ist 3. 3x的导数是3 Lösen Prob ...
- 自定义ContentTypeHandler在struts2-rest-2.3.16.2不生效
需要使用自定义的ContentHandler格式化json中的时间类型为指定模式. 在struts.xml中增加了自定义的ContentHandler,但不会生效. http://blog.csdn. ...
- Java求一个数组中的最大值和最小值
原创作品,转载请注明出处:https://www.cnblogs.com/sunshine5683/p/9927186.html 今天在工作中遇到对一个已知的一维数组取出其最大值和最小值,分别用于参与 ...
- #if, #elif, #else, #endif 使用
程序想要通过简单地设置一些参数就生成一个不同的软件,在不同的情况下可能只用到一部分代码,就没必要把所有的代码都写进去,就可以用条件编译,通过预编译指令设置编译条件,在不同的需要时编译不同的代码. (一 ...
- 原型模式(GOF23)
依赖关系的倒置 基本假设在于抽象变化的慢,而依赖于抽象的细节变化的快,所以要做到抽象不依赖于实现的细节,而实现细节应该依赖于抽象 设计模式不是代码的复用,而是经验的复用,通过分析来定义抽象和细节,不要 ...
- HTML网页随笔笔记
文档设置标记 1.格式标记 1.<br> 强制换行标记 让后面的文字.图片.表格等等,显示在下一行 2.<p> 换段落标记 换段落,由于多个空格和回车在HTML中会被等效为 ...
- BZOJ4598: [Sdoi2016]模式字符串(点分治 hash)
题意 题目链接 Sol 直接考虑点分治+hash匹配 设\(up[i]\)表示\(dep \% M = i\)的从下往上恰好与前\(i\)位匹配的个数 \(down\)表示\(dep \% M = i ...
- js 对象数组去重
var arr = [{ "name": "ZYTX", "age": "Y13xG_4wQnOWK1QwJLgg11d0pS4h ...
- 面向对象第四章(封装、static)
1.package: 1)作用:避免类名的冲突 2)包名可以有层次结构 3)类的全称: 包名.类名,同包中的类不能同名 4)建议:包名所有字母都小写 import: 1)同包中的类可以直接访问, 不同 ...
- (生产)vue-lazyload - 图片延迟加载
参考:https://www.npmjs.com/package/vue-lazyload CDN https://unpkg.com/vue-lazyload/vue-lazyload.js Usa ...