Django知识总结(二)
拾 ● 模型(M)
一 ● ORM(对象关系映射, Object Relational Mapping)
|
类----一张表 类的实例对象----表中的一条记录 |
|
映射关系 ①python的类名对应的SQL语句的表名 ② python的类属性对应的SQL语句的表名下的字段 ③ python的类属性的约束对应的SQL语句的表名下的字段类型 |
二● 开始使用Django的ORM
|
|
① model字段类型都继承自抽象类django.db.models.Field 普通字段: 模型类中除外键外的字段属性, 如: CharField(), IntegerField(), FloatField(), DateField(), EmailField() ② 有一些每个字段都可以设置的公共参数: ● primary_key = True--字段是否为主键 ● unique=True--在数据库中是否是唯一的字段 ③ class Meta中的tb_table是映射的数据表名, 例如: tb_table = 'moments' 如果不提供上述字段, 自动生成表名, 格式为"应用名_模型名" |
|
※ model字段类型 & 表单字段类型总结: (这些字段其实都是类!!!) model字段类型 & 字段选项 http://mode1943.blog.163.com/blog/static/7921843620140641159627/ 表单字段类型 http://python.usyiyi.cn/documents/django_182/ref/forms/fields.html#built-in-field-classes 对比: "Django的表单系统: 主要分两种"这一节 |
三● 查询记录
1 ● 单表查询
|
① 使用API 13个API查询:all,filter,get ,values,values_list,distinct,order_by ,reverse , exclude,count,first,last,exists(判断是否存在) ② 基于双下划线查询 |
● ※ 单表查询详解
|
① 使用API |
|
(1)Student.objects.all() #返回的QuerySet类型(集合对象), 查询所有记录 [obj1,obj2....] (2)Student.objects.filter() #返回的QuerySet类型, 查询所有符合条件的记录 (3)Student.objects.exclude() #返回的QuerySet类型, 查询所有不符合条件的记录 (4)Student.objects.get() #返回的models对象, 查询结果必须有且只有一个,否则报错 (5)Student.objects.all().first() #返回的models对象, 查询结果集合中的第一个 (6)Student.objects.filter().last( #返回的models对象, 查询结果集合中的最后一个 (7)Student.objects.all().values("name","class_id") #返回的QuerySet类型 ,列表中存放的是字典 (8)Student.objects.all().values_list("name","class_id") #返回的QuerySet类型 ,列表中存放的是元组 (9)Student.objects.all().order_by("class_id") # 按指定字段排序,不指定,按主键排序 (10)Student.objects.all().count() # 返回的记录个数 (11)Student.objects.all().values("name").distinct() # 从返回剔除重复纪录的结果 (12)Student.objects.all().values("name").reverse() #对查询结果反向排序 (13)Student.objects.all().exist() # 如果QuerySet包含某数据,就返回True,否则返回False |
|
② 基于双下划线查询 |
|
(1)models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且小于10的值 (2)models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 (3)models.Tb1.objects.exclude(id__in=[11, 22, 33]) # 相当于not in (4)models.Tb1.objects.filter(name__contains="ven") # 包含 (5)models.Tb1.objects.filter(name__icontains="ven") # icontains对大小写不敏感 (6)models.Tb1.objects.filter(id__range=[1, 2]) # 范围吗相当于bettwen and (7)startswith, istartswith(对大小写不敏感) (8)endswith, iendswith(对大小写不敏感) |
2 ● 跨表查询
|
① 基于对象跨表查询(对应sql的子查询) ② 基于双下划线查询(对应sql的join查询) |
● ※ 跨表查询详解
|
|
3 ● 聚合查询
|
与SQL的聚合函数相关 aggregate(*args, **kwargs) aggregate是只选择你感兴趣的,返回的是一个字典 |
4 ● 分组查询
|
为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数), 该统计值对应一个字段 可理解为我们可以给该模型加个字段作为注释。 annotate是在返回原来的queryset的基础之上,再加上额外的存储统计值字段。 例如: 查询每一本书的名字,对应出版社名称以及作者的个数 bookList = Book.objects.annotate(authorsNum=Count('authors')) 那么for book_obj in bookList: print(book_obj.__dict__); 我们可以发现多了一个authorsNum属性. |
5 ● F查询
|
※ 前面的例子是比较字段值与某个常量 ※ 现在要比较两个字段的值, 例如: ※ 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__gt=F('keepNum')) |
6 ● Q查询
|
※ filter()等函数实现的查询是"逻辑与(AND)"的查询, 现在要实现"逻辑或(OR)"的查询 from django.db.models import Q bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon")) 等价于sql的: WHERE name ="yuan" OR name ="egon" |
● 四、添加记录
1 ● 单表添加记录
|
方式1: s=Student(name='Arroz',age=18) # 指定多个键值对, 也可以写成s=Student(**{"name":"Arroz", "age":18}) s.save() 方式2: stu_obj=Student.objects.create(name='Arroz',age=18) # stu_obj是添加的记录对象 |
2 ● 跨表添加记录
|
一对多添加方式: 方式1: # 建立出版社和书的一对多的关系 book_obj=Book.objects.create(title="python",price=223,publisher_id=2) 方式2: book_obj=Book.objects.get(nid=1) print(book_obj.publisher) # 是nid=1的这本书的关联的出版社对象(一个对象) book_obj=Book(title="Linux",price=122,publisher=publish_obj) 多对多的添加方式: ManyToManyField: # 绑定关系 book_obj=Book.objects.get(nid=2) author_list=Author.objects.all() # 建立书和作者的多对多的关系 book_obj.authors.add(*author_list) # book_obj.authors: nid=2 的书籍关联的作者的对象集合 # 解除关系 book_obj.authors.clear() #解除所有绑定关系 book_obj.authors.remove(author) #解除单个绑定关系 手动创建第三张表: Book2Author.objects.create(book_id=1,author_id=1) |
● ※ 中介模型(intermediate model)
|
对于"多对多"关系的两张表, Django会为我们自动创建第三张表,但是这张表只有关联字段; 如果要添加额外的字段(extra field) 或者约束(如联合唯一索引),此时就需要自己建立第三张表, 即中介模型(此时, 关联字段没有自动创建, 需要自己创建) |
五● 修改记录
|
|
六● 删除记录
|
拾壹 ● 模板(T)
一 ● 模板定义
|
模块----模板包含① HTML代码( 输出静态部分) + ② 逻辑控制代码(动态插入部分)
|

※ 模板语法
二 ● 模板语法之变量
|
语法:{{var_name}} |
|
|
|
注意:句点符也可以用来引用对象的方法(无参数的方法)。 <h4>字典:{{ dic.name.upper }}</h4> <!--YUAN--> |
|
※ 调试方法 >>> python manage.py shell (进入该django项目的环境) >>> from django.template import Context, Template >>> t = Template('My name is {{ name }}.') >>> c = Context({'name': 'Stephane'}) >>> t.render(c) 'My name is Stephane.' |
三 ● 模板语法之过滤器
|
语法 {{obj|filter_name:param}} |
|
1、default:如果一个变量是false或者为空,使用给定的默认值。否则,使用变量的值。例如: |
|
2、length:返回值的长度。它对字符串和列表都起作用。例如: {{ value|length }} 如果 value 是 ['a', 'b', 'c', 'd'],那么输出是 4。 |
|
3、filesizeformat:将值格式化为一个 "人类可读的" 文件尺寸(例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如: 如果 value 是 123456789,输出将会是 117.7 MB。 |
|
4、date: value=datetime.datetime.now() {{ value|date:"Y-m-d" }} |
|
5、slice:切片 如果 value="hello world" |
|
6、truncatechars: 截断 如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列("...")结尾。 参数:要截断的字符数()、单词数 value="Arroz is a boy" <p>截断字符:{{ value|truncatechars:10 }}</p> <!----> <p>截断单词:{{ value|truncatewords:4 }}</p> <!----> |
|
7、safe 为了安全, Django的模板中会对HTML标签和JS等语法标签进行自动转义,safe过滤器告诉Django这段代码是安全的,不必转义: value="<a href="">点击</a>" {{ value|safe}} |
|
其它过滤器详见: http://python.usyiyi.cn/translate/django_182/ref/templates/builtins.html#ref-templates-builtins-tags |
四 ● 模板语法之标签(流程控制)
|
语法: {% tag %} |
|
1、for标签(注:循环序号可以通过{{forloop}}显示) |
|
2、for....empty :for 标签带有一个可选的{% empty %} 从句,给出的列表为或列表不存在时,执行此处: |
|
3 |
|
4 |
|
5 |
|
6 |
● ※ (了解)自定义标签和过滤器
|
1、在settings中的INSTALLED_APPS列表中配置当前app,不然django无法找到自定义的simple_tag. 2、在app中创建templatetags包(包名只能是templatetags) 3、在templatetags里面创建任意 .py 文件,如:my_tags.py
4、在需要使用自定义的simple_tag和filter的html文件中导入之前创建的 my_tags.py 5、使用filter和simple_tag(注意如何调用) ※ 过滤器:{{ var|filter_name:参数 }} # 参数只能是两个,一个参数是变量var ,一个是filter_name:后面的那个参数 ※ 标签:{% simple_tag 参数1 参数2 ... %}
※ 自定义过滤器函数的参数只能两个,可以进行逻辑判断; 自定义标签无参数限制,不能进行逻辑判断. 也就是说: filter可以用在if等语句后,simple_tag不可以(因为simple_tag也用的是{% %}(调用的时候必须加) 会和外层if的{% %} 冲突) |
五 ● 模板语法之继承
|
定义:模板继承可以减少页面内容的重复定义,实现页面内容的重用 典型应用:网站的头部、尾部是一样的,这些内容可以定义在父模板中,子模板不需要重复定义, 例如:
|

● 继承中用到的两个标签
|
block标签:在父模板中预留区域,在子模板中填充 extends标签:继承,写在模板文件的第一行 |
● 继承的步骤
|
1, 定义父模板base.html |
|
|
2, 定义子模板index.html |
|
{ % extends "base.html" %} <!--在子模板中使用block填充预留区域--> { %block block_name%} 实际填充内容 { %endblock%} |
● 模板语法总结
|
{{ item }} {% for item in item_list %} <a>{{ item }}</a> {% endfor %} forloop.counter forloop.first forloop.last {% if ordered_warranty %} {% else %} {% endif %} 母板:{% block title %}{% endblock %} 子板:{% extends "base.html" %} {% block title %}{% endblock %} 帮助方法: {{ item.event_start|date:"Y-m-d H:i:s"}} {{ bio|truncatewords:"30" }} {{ my_list|first|upper }} {{ name|lower }} |
拾贰 ● Django静态文件的引入使用
|
项目中的CSS、图片、js都是静态文件 |
|
分两种情况: ① 在开发环境中引入静态文件 ② 部署到nginx等web服务器时引入静态文件 |
一 ● 在开发环境中引入静态文件
|
|
|
# settings.py |
二 ● 部署到nginx等web服务器时引入静态文件
|
URI请求-----> 按照Web服务器里面的配置规则先处理,以nginx为例,主要求配置在nginx.conf里的location ----如果是静态文件,则由nginx直接处理 ----如果不是则交由Django处理,Django根据urls.py里面的规则进行匹配 |
● ※ URI和URL的区别
|
URI (Uniform Resoure Locator, 统一资源标识符)是从虚拟根路径开始的 URL(Uniform Resoure Identifier, 统一资源定位符)是整个链接 例如: URL---http://zhidao.baidu.com/question/68016373.html URI----/question/68016373.html搜索 Baidu的服务器上把http://zhidao.baidu.com/制作成了虚拟的路径的根 |
● ※ media配置
|
static和media的区别: static是不变的,形成网站的核心部件,如 CSS文件,JS文件,背景图片等; media是变动的,由用户定义的文件,如用户头像,用户上传的图片或视频等。 |
|
拾叁 ● cookie和session
● 一、cookie
|
定义和作用 ookie是在客户端记录用户信息的键值对 cookie 是怎么在浏览器和服务器之间交互的? 是通过http的响应头和请求头使客户端和服务器端进行交互的。 cookie数据格式 { name : value, name : value,... } 例如: { "is_login" : True, "csrftoken" : "vdfvdfdfgf43r32", "sessionid" :"asdfghjkasdfghjk" # 随机字符串"asdfghjkasdfghjk"是服务端session 的name } ※ 手动抓包两种方法 wireshark抓包和fiddler抓包 详见: http://www.chinaz.com/web/2015/0326/393344.shtml |
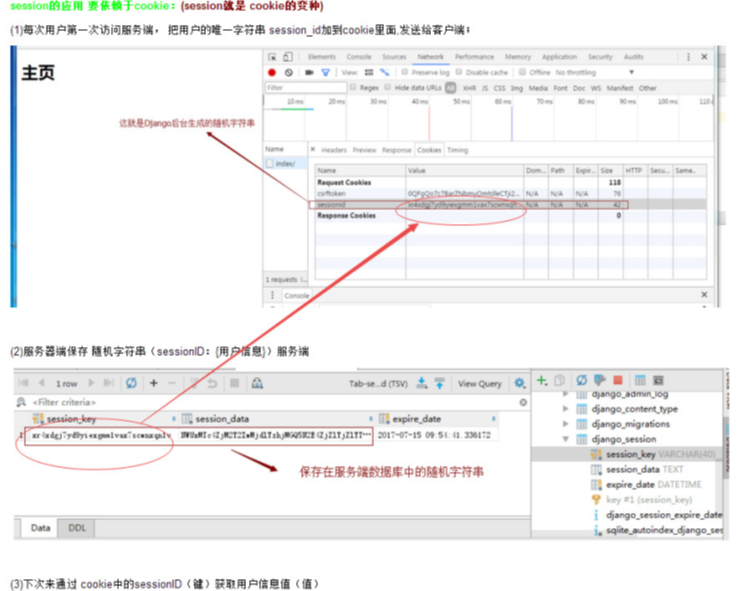
● 二、session
|
定义和作用 session是在服务端记录用户信息的键值对, 避免密码等敏感信息保存在客户端,并且防止客户端修改cookie信息. session数据格式 { session_key(随机字符串) : {session_data}(加了密的用户1的信息字典), session_key(随机字符串) : {session_data}(加了密的用户2的信息字典), ... ... } 例如: { "asdfghjkasdfghjk" : {id:1, name:"alex"}, "zxcvbnmzxcvbnm" : {id:1, name:"eric"} } ※ {id:1,nam:"alex",account:1000000000 }这些数据会被加密, 例如:
|

● 三、session依赖于cookie
|
|
|
|

● ※ Django的session与cookie的实现原理
|
版本一: ① 服务器会生成两份相同的cookie字符串,一份保存在本地,一份发向浏览器。 ② 浏览器将收到的cookie字符串保存下来,当下次再请求时,会将这段cookie发送到服务器, 服务器得到这段cookie会与本地保存的那份判断是否相同,如果相同就表示用户已经登录成功,保存用户登录成功的状态。 ※ Django cookie的有一个key是sessionid, value是随机字符串 ※ Django session保存在数据库的数据相当于一个大字典,key(session_key)为cookie的随机字符串, value(session_data)是一个加密的字典,字典的key和value为用户设置的相关信息。 ※ 如过打开一个网页没有提交sessionID上来,服务器会认为你是一个全新的请求,服务器会给你分配一个新的sessionID,这就是为什么我们每次打开一个新的浏览器的时候(无论之前我们有没有登录过)都会产生一个新的sessionID(或者是会让我们重新登录)。 |
|
版本二: |
● ※ JQuery中$.cookie()方法的使用
|
使用背景 ① 浏览器存储了cookie ② 借助jquery.cookie.js插件 |
|
Django知识总结(二)的更多相关文章
- Python 学习第十九天 django知识
一,django 知识总结 1,同一个name属性的标签,多个值获取 <form action="/login/" method="POST" encty ...
- Python学习---django知识补充之CBV
Django知识补充之CBV Django: url --> def函数 FBV[function based view] 用函数和URL进行匹配 url --> ...
- Django学习笔记二
Django学习笔记二 模型类,字段,选项,查询,关联,聚合函数,管理器, 一 字段属性和选项 1.1 模型类属性命名限制 1)不能是python的保留关键字. 2)不允许使用连续的下划线,这是由dj ...
- Django之Models(二)
Django之Models(二) 创建一对多的关系 一个出版商可以有多本出版的书 一本书只有一个出版商 创建一对多的语法: 字段名= models.ForeignKey(关联表(类名),on_dele ...
- Django开发笔记二
Django开发笔记一 Django开发笔记二 Django开发笔记三 Django开发笔记四 Django开发笔记五 Django开发笔记六 1.xadmin添加主题.修改标题页脚和收起左侧菜单 # ...
- {django模型层(二)多表操作}一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询、分组查询、F查询和Q查询
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 xxx 七 ...
- Java JDBC的基础知识(二)
在我的上一篇Java JDBC的基础知识(一)中,最后演示的代码在关闭资源的时候,仅仅用了try/catch语句,这里是有很大的隐患的.在程序创建连接之后,如果不进行关闭,会消耗更多的资源.创建连接之 ...
- Django 知识补漏单例模式
Django 知识补漏单例模式 单例模式:(说白了就是)创建一个类的实例.在 Python 中,我们可以用多种方法来实现单例模式: 1.文件导入的形式(常用) s1.py class Foo(obje ...
- 基于Ubuntu Server 16.04 LTS版本安装和部署Django之(二):Apache安装和配置
基于Ubuntu Server 16.04 LTS版本安装和部署Django之(一):安装Python3-pip和Django 基于Ubuntu Server 16.04 LTS版本安装和部署Djan ...
随机推荐
- linux下配置zookeeper注册中心及运行dubbo服务
dubbo和zookeeper的关系 简单来说打个比方:dubbo就是动物园的动物,zookeeper是动物园.如果游客想看动物的话那么就去动物园看.比如你要看老虎,那么动物园有你才能看到.换句话说我 ...
- iOS QQ 扫一扫 捷径URL
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- P3953 逛公园
传送门 花了一个下午才 A 的毒瘤题 思路: 这题需要建两个图,一个正向图,一个反向图. 先在正向图上跑一遍 dijkstar ,计算出每个点到 点1 的最短路径 . 然后在反向图上开始记忆化搜索: ...
- mysql分库 分页查询
Mysql海量数据分表分库如何列表分页? 1.现在使用ElasticSearch了.基于Lucene的解决方案 2.必须将mysql里的数据写入到类似hbase这样的分布式数据库,查询快.但分页.查询 ...
- Axure下拉列表的交互事件 + 自定义元件库
下拉列表的交互事件: 场景:当点击第一个下拉列表框的江苏时,第二个列表框会显示江苏省的城市:当点击第一个下拉列表框的北京时,第二个列表框会显示北京市的区 操作:把第二个列表框设置为动态面板,设置为两种 ...
- GT sport真实赛道详解 - Brands Hatch | 伯蘭士赫治GP賽車場
参考:GT sport所有赛道简介 GT Sport - Tip/Guide For FASTER LAP TIMES (Brands Hatch) 赛道介绍.跑法.赛事网上都有大把的视频. GT s ...
- 2018-2019-2 20165303《网络对抗技术》Exp2 后门原理与实践
实验内容 (1)使用netcat获取主机操作Shell,cron启动 (0.5分) (2)使用socat获取主机操作Shell, 任务计划启动 (0.5分) (3)使用MSF meterpreter( ...
- js判断输入的input内容是否为数字
有时候我们输入的input的内容需要判断一下是否是数字,所以为了更好的客户体验,在前端先处理一下: <input type="text" name="val&quo ...
- 20190407 Word合并单元格
很长一段时间没处理word合并单元格,又忘记了采取忽略错误的方式测试出相应单元格的行列坐标这种方式.真是浪费时间.以后再也不想为此在深夜熬命. 今晚算是和它杠上了,很想弄清楚合并单元格之后行列坐标重新 ...
- imp、exp命令导出优化
本文对Oracle数据的导入导出 imp ,exp 两个命令进行了介绍, 并对其对应的參数进行了说明,然后通过一些演示样例进行演练,加深理解.文章最后对运用这两个命令可能出现的问题(如权限不够,不同o ...