SparkStreaming流处理
一、Spark Streaming的介绍
1. 流处理
流式处理(Stream Processing)。流式处理就是指源源不断的数据流过系统时,系统能够不停地连续计算。所以流式处理没有什么严格的时间限制,数据从进入系统到出来结果可能是需要一段时间。然而流式处理唯一的限制是系统长期来看的输出速率应当快于或至少等于输入速率。否则的话,数据岂不是会在系统中越积越多(不然数据哪去了)?如此,不管处理时是在内存、闪存还是硬盘,早晚都会空间耗尽的。就像雪崩效应,系统越来越慢,数据越积越多。
2、spark架构
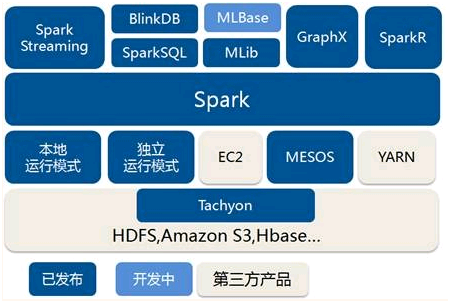
3、Spark Streaming特点
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
能运行在100+的结点上,并达到秒级延迟。
使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
能集成Spark的批处理和交互查询。
为实现复杂的算法提供和批处理类似的简单接口。
Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
4、程序流程
引入头文件
|
import org.apache.spark._ |
1. 创建StreamingContext对象 同Spark初始化需要创建SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置;
|
|
- 创建InputDStream Spark Streaming需要指明数据源。如上例所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括Kafka、 Flume、HDFS/S3、Kinesis和Twitter等数据源;
|
val lines = |
- 操作DStream对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的WordCount执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用Map和ReduceByKey方法进行计算,当然最后还有使用print()方法输出结果;
|
val words = val pairs = |
- 启动Spark Streaming之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。
|
ssc.start() ssc.awaitTermination() |
5、单词统计例子
|
object Count ssc.awaitTermination() } |
二、SparkStreaming累加器及广播变量的使用
Spark Streaming的累加器和广播变量无法从checkpoint恢复。如果在应用中既使用到checkpoint又使用了累加器和广播变量的话,最好对累加器和广播变量做懒实例化操作,这样才可以使累加器和广播变量在driver失败重启时能够重新实例化。
定义累加器
|
Object DroppedWordsCounter { |
定义广播变量
|
object |
删除重复的单词
|
object SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[2]") |
主函数
|
def |
SparkStreaming流处理的更多相关文章
- Spark之 Spark Streaming流式处理
SparkStreaming Spark Streaming类似于Apache Storm,用于流式数据的处理.Spark Streaming有高吞吐量和容错能力强等特点.Spark Streamin ...
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- (转)park1.0.0生态圈一览
转自博客:http://www.tuicool.com/articles/FVBJBjN Spark1.0.0生态圈一览 Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验 ...
- Spark1.0.0 生态圈一览
Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验室精心打造的,力图在算法(Algorithms).机器(Machines).人(People)之间通过大规模集 ...
- Storm简介及使用
一.Storm概述 网址:http://storm.apache.org/ Apache Storm是一个免费的开源分布式实时计算系统.Storm可以轻松可靠地处理无限数据流,实现Hadoop对批处理 ...
- 基于Hadoop生态SparkStreaming的大数据实时流处理平台的搭建
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理.用户行为分析.场景业务分析等等,传统的写日志方式根本满足不了业务的实时处理需求,所以本人准备开始着手改造原系统中的数据处理方式, ...
- Spark-Streaming 常用流式计算算子
UpdateStateByKey 使用说明:维护key的状态. 使用注意:使用该算子需要设置checkpoint 使用示例: object UpdateStateByKeyTest { def mai ...
- 大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计
1.安装并配置zk 2.安装并配置Kafka 3.启动zk 4.启动Kafka 5.创建topic [root@mini3 kafka]# bin/kafka-console-producer. -- ...
- SparkStreaming(源码阅读十二)
要完整去学习spark源码是一件非常不容易的事情,但是咱可以积少成多嘛~那么,Spark Streaming是怎么搞的呢? 本质上,SparkStreaming接收实时输入数据流并将它们按批次划分,然 ...
随机推荐
- Parco_Love_String
二维的kmp直接搞出来emmm, 后缀自动机都没这个快(本弱鸡不会后缀自动机) #include <bits/stdc++.h> using namespace std; #define ...
- 铁大Facebook隐私保护NABCD
隐私保护功能: N:满足了用户保护自己隐私信息的需求 A:对每一项用户可能需要保护的信息,我们都会添加仅自己可见.指定人可见.部分人可见或所有人可见设置 B:让用户的信息受到更全面的保护,而不仅仅是对 ...
- javaweb 发布目录
一个Java Web项目要运行,它首先要放在tomcat之类的容器中:该JavaWeb项目的构成一定要包含下面几种文件以及文件夹: META-INF : 存放一些meta information相关的 ...
- Oracle中hex和raw的相互转换
可以参考以下语句: select hextoraw(rawtohex('你好')) from dual select utl_raw.cast_to_varchar2(hextoraw('E4BDA0 ...
- ld命令
ld 用于把目标代码文件连接为可执行文件或者库文件 参数 -b: 指定目标代码输入文件的格式 -Bstatic: 只使用静态库 -Bdynamic: 只使用动态库 -Bsymbolic: 把引用捆绑到 ...
- OpenStack-Neutron-Fwaas-代码【一】
Kilo的代码中对Fwaas做了优化,可以将规则应用到单个路由上 但是juno里面还是应用到租户的所有路由上的,因此对juno的代码做了修改 1. 介绍 在FWaaS中,一个租户可以创建多个防火墙,而 ...
- 监控单个进程占用cpu与内存的使用情况
#!/bin/bashinterval=1if [ "$1" != "" ]then interval=$1fiecho "检查时间间隔(单位秒):& ...
- web接口文档apidoc的使用
1.安装 npm install apidoc -g 2.新建src文件夹,里面放2个文件,test.js和apidoc.json 3.test.js /** * @api {get} /query_ ...
- 20175208 《Java程序设计》第七周学习总结
20175208<Java程序设计>第七周学习总结 第八章-常用实用类String类 构造String对象 string类: (1)常量对象:常量池中的数据在程序运行期间再也不允许改变. ...
- sehll 小脚本的编写{基础}
1.模拟linnux登录shell #/bin/bash echo -n "login:" read name echo -n "password:" read ...