Spark MLlib
MLlib
数据挖掘与机器学习
数据挖掘体系
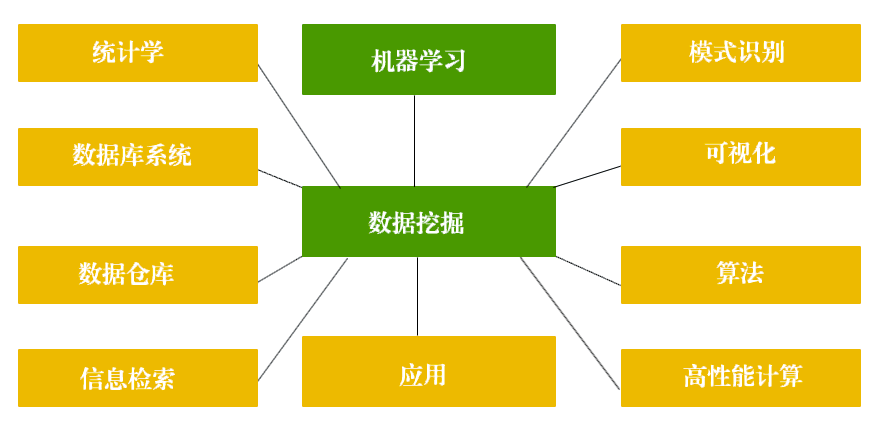
数据挖掘:也就是data mining,是一个很宽泛的概念,也是一个新兴学科,旨在如何从海量数据中挖掘出有用的信息来。
数据挖掘这个工作BI(商业智能)可以做,统计分析可以做,大数据技术可以做,市场运营也可以做,或者用excel分析数据,发现了一些有用的信息,然后这些信息可以指导你的business,这也属于数据挖掘。
机器学习:machine learning,是计算机科学和统计学的交叉学科,基本目标是学习一个x->y的函数(映射),来做分类、聚类或者回归的工作。之所以经常和数据挖掘合在一起讲是因为现在好多数据挖掘的工作是通过机器学习提供的算法工具实现的,例如广告的ctr预估,PB级别的点击日志在通过典型的机器学习流程可以得到一个预估模型,从而提高互联网广告的点击率和回报率;个性化推荐,还是通过机器学习的一些算法分析平台上的各种购买,浏览和收藏日志,得到一个推荐模型,来预测你喜欢的商品。
深度学习:deep learning,机器学习里面现在比较火的一个topic,本身是神经网络算法的衍生,在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。
总结:数据挖掘是个很宽泛的概念,数据挖掘常用方法大多来自于机器学习这门学科,深度学习也是来源于机器学习的算法模型,本质上是原来的神经网络。
监督学习和无监督学习
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有导师训练。
常见的监督学习算法
1.线性回归
2.逻辑回归
3.朴素贝叶斯
4.KNN(最近邻算法)
5.决策树
6.支持向量机
7.某些可用于分类或预测功能的神经网络模型
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
常见的无监督学习算法
1.系统聚类
2.K-means
3.K-中值聚类
3.K-众数法
4.某些神经网络模型,比如BP神经网络等
5.受限玻尔兹曼机
概述
MLlib is Apache Spark's scalable machine learning library.
MLlib是一个构建在Spark上的、专门针对大数据处理的并发式高速机器学习库,其特点是采用较为先进的迭代式、内存存储的分析计算,使得数据的计算处理速度大大高于普通的数据处理引擎
目前MLlib中已经有通用的学习算法和工具类,包括统计、分类、回归、聚类、降维等。
MLlib采用Scala语言编写,Scala语言是运行在JVM上的一种函数式编程语言,特点就是可移植性强,“一次编写,到处运行”是其最重要的特点。
借助于RDD数据统一输入格式,让用户可以在不同的IDE上编写数据处理程序,通过本地化测试后可以在略微修改运行参数后直接在集群上运行
对结果的获取更为可视化和直观,不会因为运行系统底层的不同而造成结果的差异与改变。
MLlib基本数据模型
RDD是MLlib专用的数据格式,它参考了Scala函数式编程思想,并大胆引入统计分析概念,将存储数据转化成向量和矩阵的形式进行存储和计算,这样将数据定量化表示,能更准确地整理和分析结果。
MLlib先天就支持较多的数据格式,从最基本的Spark数据集RDD到部署在集群中的向量和矩阵。同样,MLlib还支持部署在本地计算机中的本地化格式。
一、本地向量
MLlib使用的本地化存储类型是向量,这里的向量主要由两类构成:稀疏型数据集(spares)和密集型数据集(dense)
二、向量标签的使用
向量标签用于对MLlib中机器学习算法的不同值做标记。例如分类问题中,可以将不同的数据集分成若干份,以整型数0、1、2……进行标记,即程序的编写者可以根据自己的需要对数据进行标记。
三、本地矩阵的使用
大数据运算中,为了更好地提升计算效率,可以更多地使用矩阵运算进行数据处理。部署在单机中的本地矩阵就是一个很好的存储方法。
分布式矩阵的使用
1. 行矩阵
行矩阵是最基本的一种矩阵类型。行矩阵是以行作为基本方向的矩阵存储格式,列的作用相对较小。可以将其理解为行矩阵是一个巨大的特征向量的集合。每一行就是一个具有相同格式的向量数据,且每一行的向量内容都可以单独取出来进行操作。
2. 带有行索引的行矩阵
单纯的行矩阵对其内容无法进行直接显示,当然可以通过调用其方法显示内部数据内容。有时候,为了方便在系统调试的过程中对行矩阵的内容进行观察和显示,MLlib提供了另外一个矩阵形式,即带有行索引的行矩阵。
MLlib统计量基础
数理统计中,基本统计量包括数据的平均值、方差,这是一组求数据统计量的基本内容。在MLlib中,统计量的计算主要用到Statistics类库。
计算基本统计量
这里主要调用colStats方法,接受的是RDD类型数据。
这里需要注意的是,其工作和计算是以列为基础进行计算,调用不同的方法可以获得不同的统计量值,其方法内容如下表所示。
二、计算相关系数
相关系数是一种用来反映变量之间相关关系密切程度的统计指标,在现实中一般用于对两组数据的拟合和相似程度进行定量化分析。常用的一般是皮尔逊相关系数,MLlib中默认的相关系数求法也是使用皮尔逊相关系数法。
距离度量和相似度度量
在数据分析和数据挖掘的过程中,我们经常需要知道个体间差异的大小,进而评价个体的相似性和类别。而如何来度量数据之间的差异则成为关键,分类算法或聚类算法的本质都是基于某种度量(距离度量和相似度度量)来实现的。
距离度量
距离度量(Distance)用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大。
欧几里得距离(Euclidean Distance)
1.欧氏距离
2.明可夫斯基距离
3.曼哈顿距离
4.切比雪夫距离
5.马氏距离
相似度度量
1.向量空间余弦相似度(Cosine Similarity)
2.皮尔森相关系数(Pearson Correlation Coefficient)
Spark MLlib的更多相关文章
- Spark MLlib - LFW
val path = "/usr/data/lfw-a/*" val rdd = sc.wholeTextFiles(path) val first = rdd.first pri ...
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Spark MLlib 之 Basic Statistics
Spark MLlib提供了一些基本的统计学的算法,下面主要说明一下: 1.Summary statistics 对于RDD[Vector]类型,Spark MLlib提供了colStats的统计方法 ...
- Spark MLlib Data Type
MLlib 支持存放在单机上的本地向量和矩阵,也支持通过多个RDD实现的分布式矩阵.因此MLlib的数据类型主要分为两大类:一个是本地单机向量:另一个是分布式矩阵.下面分别介绍一下这两大类都有哪些类型 ...
- Spark MLlib - Decision Tree源码分析
http://spark.apache.org/docs/latest/mllib-decision-tree.html 以决策树作为开始,因为简单,而且也比较容易用到,当前的boosting或ran ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
- spark mllib配置pom.xml错误 Multiple markers at this line Could not transfer artifact net.sf.opencsv:opencsv:jar:2.3 from/to central (https://repo.maven.apache.org/maven2): repo.maven.apache.org
刚刚spark mllib,在maven repository网站http://mvnrepository.com/中查询mllib后得到相关库的最新dependence为: <dependen ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- spark Mllib基本功系列编程入门之 SVM实现分类
话不多说.直接上代码咯.欢迎交流. /** * Created by whuscalaman on 1/7/16. */import org.apache.spark.{SparkConf, Spar ...
随机推荐
- Cocos Creator中使用事件中心
export class EventCenter { /** 监听数组 */ private listeners = {}; /** * 注册事件 * @param name 事件名称 * @para ...
- gcd前缀和-蒜头君的数轴
题目: 今天蒜头君拿到了一个数轴,上边有 n个点,但是蒜头君嫌这根数轴不够优美,想要通过加一些点让它变优美,所谓优美是指考虑相邻两个点的距离,最多只有一对点的距离与其它的不同. 蒜头君想知道,他最少需 ...
- JSTree如何实现第二级菜单异步从数据库读取。
参考文档: https://www.cnblogs.com/luozhihao/p/4679050.html http://jsfiddle.net/vakata/2kwkh2uL/5/ 核心的关键点 ...
- 第k个素因子只有3 5 7 的数
题目描述 有一些数的素因子只有3.5.7,请设计一个算法,找出其中的第k个数. 给定一个数int k,请返回第k个数.保证k小于等于100. 测试样例: 3 返回:7 int findKth(int ...
- USCiLab cereal json 序列化
cereal json 序列化 https://blog.csdn.net/sunnyloves/article/details/51373793?utm_source=blogxgwz8 http: ...
- Analysis CDI
CDI是一组服务,它们一起使用,使开发人员可以轻松地在Web应用程序中使用企业bean和JavaServer Faces技术.CDI设计用于有状态对象,还有许多更广泛的用途,允许开发人员以松散耦合但类 ...
- RabbitMQ 官方demo1
public class RabbitMqSend { public static void Test() { var factory = new ConnectionFactory() { Host ...
- JVM服务进程挂掉问题定位查询思路
昨天有朋友咨询了个RegionServer宕机找不到日志无法定位原因的问题,干脆就系统整理下JVM服务宕机的可能原因,方便按照思路去找真正的宕机原因. 1. abort()/halt()/exit() ...
- 3.1circle
就是括号匹配的题目,如果有交集就是NO #include<iostream> #include<cstring> #include<stdio.h> #includ ...
- Spring + SpringMVC + Mybatis项目中redis的配置及使用
maven文件 <!-- redis --> <dependency> <groupId>redis.clients</groupId> <art ...