Scrapy爬虫错误日志汇总
1、数组越界问题(list index out of range)

原因:第1种可能情况:list[index]index超出范围,也就是常说的数组越界。
第2种可能情况:list是一个空的, 没有一个元素,进行list[0]就会出现该错误,这在爬虫问题中很常见,比如有个列表爬下来为空,统一处理就会报错。
解决办法:从你的网页内容解析提取的代码块中找找看啦(人家比较习惯xpath + 正则),加油 ~
---------------------------------------------------华丽的分隔符------------------------------------------------------------
2、http状态代码没有被处理或不允许(http status code is not handled or not allowed)

原因:第1种情况:就是你的http状态码没有被识别,需要在settings.py中添加这个状态码信息,相当于C语言中的#define预处理宏定义命令吧
第2种情况:403是网页状态码,表示访问拒绝或者禁止访问。应该是你触发到网站的反爬虫机制了。
解决办法:如果是第1种情况,在你的setting.py中,添这么一句短小精悍的话就OK了,紧接着就等着高潮吧您呐:HTTPERROR_ALLOWED_CODES = [403]
如果是第2种情况,a.伪造报文头部user-agent(网上有详细教程不用多说)
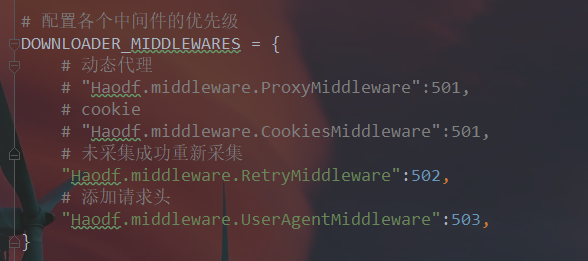
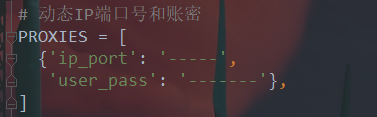
b.使用可用代理ip,如果你的代理不可用也会访问不了
c.是否需要帐户登录,使用cookielib模块登录帐户操作
如果以上方法还是不行,那么你的ip已被拉入黑名单静止访问了。等一段时间再操作。如果等等了还是不行的话:
d.使用phatomjs或者selenium模块试试。
还不行使用别的scrapy爬虫框架看看。
以上都不行,说明这网站反爬机制做的很好,爬不了了,没法了,不过我觉得很少有这种做得很好的网站
---------------------------------------------------华丽的分隔符------------------------------------------------------------
此篇文章持续更新,未完待续....
欢迎大家留下自己的问题,互相讨论,互相学习,互相总结,,,,
Scrapy爬虫错误日志汇总的更多相关文章
- Python2.7集成scrapy爬虫错误解决
运行报错: NotSupported: Unsupported URL scheme 'https':.... 解决方法:降低对应package的版本 主要是scrapy和pyOpenSSL的版本 具 ...
- Scrapy爬虫框架示意图汇总
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- scrapy爬虫框架setting模块解析
平时写爬虫的时候并不需要设置setting里所有的参数,今天心血来潮,花了点时间查了一下setting模块创建后自动写入的所有参数的含义,记录一下. 模块相关说明信息 # -*- coding: ut ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 基于scrapy爬虫的天气数据采集(python)
基于scrapy爬虫的天气数据采集(python) 一.实验介绍 1.1. 知识点 本节实验中将学习和实践以下知识点: Python基本语法 Scrapy框架 爬虫的概念 二.实验效果 三.项目实战 ...
随机推荐
- Android APT
APT APT(Annotation Processing Tool)是一种处理注释的工具,它对源代码文件进行检测找出其中的Annotation,使用Annotation进行额外的处理. Annota ...
- 清理 zabbix 历史数据, 缩减 mysql 空间
zabbix 由于历史数据过大, 因此导致磁盘空间暴涨, 下面是结局方法步骤 1. 停止 ZABBIX SERER 操作 [root@gd02-qa-plxt2-nodomain-web-95 ~] ...
- js-day03-事件响应和练习题
DOM事件编程 事件驱动编程:所谓事件驱动,简单地说就是你点什么按钮(即产生什么事件),电脑执行什么操作(即调用什么函数).当然事件不仅限于用户的操作. 当对象处于某种状态时,可以发出一个消息通知,然 ...
- C++或C#调用外部exe的分析
假如有个外部程序名为A.exe,放在目录E:\temp\下,然后我们用C++或者C#写一个程序调用这个A.exe的话(假设这个调用者所在的路径在D:\invoke),通常会采用下面的代码: // C# ...
- SUSE12Sp3-Nginx安装
1.安装pcre(nginx 依赖) 把安装包pcre-8.12.tar.gz复制到服务器指定目录 tar -zxvf pcre-8.12.tar.gz # 解压 cd pcre-8.12 #进入目录 ...
- [Swift]LeetCode163. 缺失区间 $ Missing Ranges
Given a sorted integer array where the range of elements are [0, 99] inclusive, return its missing r ...
- [Swift]LeetCode256.粉刷房子 $ Paint House
There are a row of n houses, each house can be painted with one of the three colors: red, blue or gr ...
- [Swift]LeetCode443. 压缩字符串 | String Compression
Given an array of characters, compress it in-place. The length after compression must always be smal ...
- [Swift]LeetCode593. 有效的正方形 | Valid Square
Given the coordinates of four points in 2D space, return whether the four points could construct a s ...
- [Swift]LeetCode697. 数组的度 | Degree of an Array
Given a non-empty array of non-negative integers nums, the degreeof this array is defined as the max ...