python使用redis
版本:
python 3.5
redis 3.0.1(redis的安装 pip install redis)
1、连接
import redis
r = redis.Redis(host='192.168.222.129', port='6379', db=0,password=password)
(这里通过本地远程连接redis的时候,会有一些问题,请见注一)
创建了redis实例后,就可以开始向redis中设置数据了:

2、使用连接池(connection pool)
就像我们在使用线程的时候,会选择线程池一样,redis的连接,我们也会选择使用connection pool来管理对一个redis server的所有连接,
避免每次建议释放连接的开销。默认每个redis实例都会维护一个自己的连接池。
当然我们也可以自己创建一个连接池,然后作为参数Redis,这样就可以实现多个redis实例共享一个连接池。
如下,我们创建了一个线程池,然后创建了两个redis实例,通过任何一个实例都可以获取到线程池中的成员。

3、redis常用API
1)String操作
使用格式:r.set(key, value, ex, px, nx, xx)
ex:过期时间(秒)
px:过期时间(毫秒)
nx:如果设置为True,只有在key不存在的时候才能成功执行
xx:如果设置为True,只有在key存在的时候才能成功执行
添加数据:r.set("name","fiona")
获取数据:r.get("name")
追加数据:r.append("name", " is cute!")
获取原值并重新赋值:r.getset("name","airo")
删除数据:r.delete("name")
默认自增1:r.incr("age", count=1) (如果key对应的value不能转化为数字,会报错,如果key不存在,会创建该key并赋值为0再执行自增1,可以指定count,就自增count)
增量:r.incrby("age") (同上)
自减1:r.decr("age") (同上)
减量:r.decrby("age") (同上)
批量设置:r.mset({"key1":"value1", "key2":"value2"})
批量获取:r.mget("key1", "key2")
2)hash
格式:r.hset(name, key, value)
设置数据:r.hset("myhash","name","fiona")
批量设置数据:r.hmset("myhash",{"name":"fiona","age":18})
获取数据:r.hget("myhash","name")
获取所有数据:r.hgetall("myhash")
获取指定成员值:r.hmget("myhash","name","age")
删除指定成员field:r.hdel("myhash","name")
删除整个hash key:r.delete("myhash")
增加:r.incrby("myhash","age", amount=1) (同上面string的incrby)
判断field是否存在:r.exists("myhash","age")
查看成员包含的fields个数:r.hlen("myhash")
查看成员包含的所有field:r.hkeys("myhash")
查看成员包含的所有values:r.hvals("myhash")
3)list
向list左边/右边插入数据:r.lpush("mylist","a",'b','c')、r.rpush("mylist",1,2 ,3)
查看list的值:r.lrange("myhash", 0,-1)、r.lrange("mylist",0,-2)
弹出左边/右边值:r.lpop("myhash")、r.rpop("mylist")
只有当key存在的时候,才能正确执行:r.lpushx("mylist1","aa")
从左到右删除指定个数的指定元素:r.lrem("mylist", 2,"a")
从右到左删除指定个数的指定元素:r.lrem("mylist",-2,'b')
删除所有的指定元素:r.lrem("mylist",0,'c')
删除指定key:r.delete("mylist")
替换指定位置的元素:r.lset("mylist", 1, "aaa") 将第二个元素设置为aaa
在某个元素之前/之后插入新的元素:r.linsert("mylist","before/after","aaa",'vvv')
从原列表中弹出最后一个元素并保存到新列表中:r.rpoplpush("mylist", "mylist1")
4)set
添加元素:r.sadd("myset","a",'b')
查看所有元素:r.smembers("myset")
判断某个元素是否存在集合中:r.sismember("myset","a")
求两个集合的差集:r.sdiff("myset","myset1")
求两个集合的差集并将差集保存在新的集合中:r.sdiffstore('newset',"myset","myset1")
求两个集合的并集:r.sunion("myset","myset1")
求两个集合的并集并将差集保存在新的集合中:r.sunionstore('newset',"myset","myset1")
求两个集合的交集:r.sinter("myset","myset1")
求两个集合的交集并将差集保存在新的集合中:r.sinterstore('newset',"myset","myset1")
求集合中元素的个数:r.scard("myset")
从集合中随机取出一个元素:r.srandmember("mylist")
5)zset
添加元素:r.zadd("myzset",{"fiona":100,"airo":90})
获取元素个数:r.zcard("myset")
获取指定分数间的元素个数:r.zcount("myset",50,100)
获取指定元素区间个元素个数:r.zlexcount("myset",'[fiona','[airo')
按照元素下标返回指定下标范围内的元素:r.zrange("myset",0,3, withscores=True)
按照元素下标倒叙返回指定下标范围内的元素:r.zrevrange("myset",0,-1,withscores=True)
按照元素区间返回指定范围内的元素:r.zrangebylex("myset",'[fiona','[airo')
按照分数范围返回指定范围内的元素:r.zrangebyscore("myset",50,100,withscores=True)
按照分数范围倒叙返回指定范围内的元素:r.zrevrangebyscore("myset",'100,50,withscores=True')
给指定的元素增加指定值:r.zincrby("myset",10,'airo')
返回指定元素在集合中对应的的索引:r.zrank("myset",'airo')
返回指定元素在倒叙集合中对应的索引:r.zrevrank("myset",'airo')
删除指定元素:r.zrem("myset",'age')
删除指定元素区间的元素:r.zremrangebylex("myset",'[airo','[airo')
删除指定索引区间的元素:r.zremrangebyrank("myset",0,1)
返回指定元素的分数:r.zscore("myset",'fiona')
获取两个有序集合的差集并存入新的有序集合:r.zinterstore("myset2",['myset','myset1'], aggregate='min')
注:aggregate取值为min,max,sum。默认是sum。即新的集合中对相同成员做取小、取大或求和操作
获取两个集合的并集并存入到新的有序集合:r.zunionstore("myset3",['myset','myset1'],aggregate='max')
获取两个集合交集并存入到新的有序集合中:r.zdiffstore("myset4",['myset','myset1'], aggregate='sum')
4、redis通用API
查看redis中保存的所有key:r.keys("*") 参数为正则表达式
判断key是否存在:r.exists("myset")
重命名key:r.rename("myset","myset1")
设置key的过期时间:r.expire("myset",10)
查看key的剩余过期时间:r.ttl("myset")
查看key的类型:r.type("myset")
5、redis的两个特性:
1)多数据库
可以通过select index命令切换数据库
2)事务性
redis开启事物后,所有的命令都将被串行化,事物执行期间,redis不会再为其他客户端提供任何服务,从而保证事物中的所有命令都被原子化执行。
和关系型数据库中的原子性不同的是,如果redis事物中的一个命令执行失败,它后面的其他命令还会继续执行。
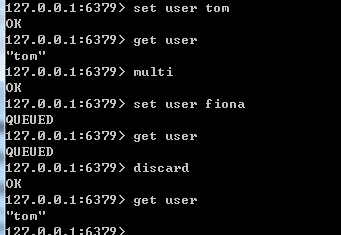
redis中通过multi开启事物,它后面所有执行命令都将会被存到一个队列中,直到遇到exec这个命令。
exec相当于关系型数据库中的提交事务
discard相当于事物回滚
在事物开启之前,如果客户端和服务器之间通讯出现故障导致网络断开,事物中的所有的语句都将不会被服务器执行
如果故障出现在exec之后,那么这个事物中的所有命令都将会被服务器执行。
如下:
事物演示:
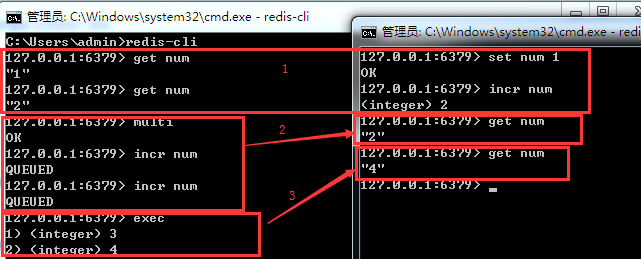
1)我开启了两个客户端连接redis服务,窗口2中set num 1,然后可以在窗口1中获取,自增后,也可以在窗口1中获取到变化值
2)在窗口1中使用multi 开启事物,然后给num自增两次,这时候去窗口2中查询num,发现值还是2
3)执行exec,然后再去窗口2中查询num,发现数据被完成了自增
事物回滚演示:
6、redis持久化
RDB持久化
默认是支持的,指在指定时间间隔将内存中的数据快照写入磁盘中。
优势:
1)整个redis数据库将会只包含一个文件,这对于文件备份是非常好的。
比如我们希望每隔1小时归档最近24小时的数据,同时还要每天归档一次最近30天的数据,那么可以通过这样的备份策略,一旦系统出现灾难性的故障,我们可以非常容易恢复
2)对于灾难恢复而言,RDB是非常不错的选择,因为我们可以非常轻松的把一个单独文件压缩后再转移的其他的存储介质
3)性能最大化。对于redis服务进程而已,在开始持久化的时候,唯一需要做的是,分叉出一些进程,之后再由子进程完成这些持久化操作。这样就可以极大的避免服务器进程执行IO操作。
相比AOF的操作,如果数据集很大,RDB启动效率更高
缺点:
1)如果想保证数据的高可用性,即最大限度的避免数据的丢失,RDB不是一个很好的选择,因为系统可能会在定时持久化之前出现一些宕机的情况,还没有来得及向硬盘写的时候,数据就丢失了。
2)由于RDB通过fork分叉的方式,子进程来协助完成持久化操作,所以当数据量很大的时候,可能会导致整个服务器会停止一段时间。
配置:
redis.conf中:

save 900 1:每900秒至少有一个key发生变化,那么它会持久化1次。
save 300 10:每300秒至少有10个key发生变化,它会往硬盘写一次。
save 60 1000:每60秒,至少有10000个key发生变化,它会持久化一次。
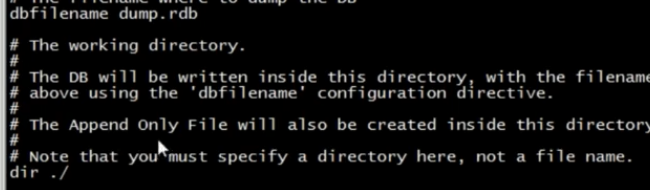
数据的保存名:dump.rdb
数据的保存路径:./当前文件夹下
AOF持久化
将以日志文件的形式记录服务器所处理的每一个操作。在redis启动之初,它会读取日志中的信息来重新构建数据库,保证启动后数据库中数据的完整性。
优势:
1)可以带来更高的安全性,redis提供了三种同步策略:每秒同步(异步的),修改同步(同步持久化,效率最高但是最安全),不同步
2)对于日志的写入操作采用的是append追加模式,所以即使操作过程中出现宕机的情况,也不会破坏文件的已经存在的内容
如果我们本次写入只写入了一半数据,就出现了崩溃的问题,我们可以在redis下次启动的前,可以通过redis.check.aof工具来解决数据一致性问题。
3)如果日志过大,redis可以自动启动重写机制。redis以append模式不断将数据写入老的文件中,同时redis还会创建一个新的文件来记录此期间来产生了哪些修改命令被执行,因此,在进行重写却换的时候,可以更好的保证数据的安全性。
4)AOF包含一个包括所有格式清晰,易于理解的日志文件用于记录所有的修改操作。事实上,我们可以通过这个文件来完成数据的一个重建。
劣势:
1)对于相同数据集的文件,AOF要比 RDB大一些
2)效率相对RDB要低一些
配置:

默认是没有开AOF模式的,默认采用的是RDB方式,如果想要使用AOF方式的话,我们需要将appendonly改为yes,然后她会产生一个文件appendonly.aof

这里提供了同步的策略:
appendfsync always:没修改一次就会同步到磁盘
appendfsync everysecond:每秒钟同步
appendfsync no:不同步
无持久化
这种方式就相当于缓存
注一:
1)如果远程连接报错‘由于目标计算机积极拒绝,无法连接’的错误,可能是以下几个原因导致的:
a)将配置文件中的bind 127.0.0.1 注释掉,这个限制了只允许本机访问
b)关闭redis的保护模式(protected-mode),这里的保护模式是指是否允许其他ip的设备访问redis,如果开启的话,就是只允许本机访问了。
c)给redis设置密码(requirepass)。如果只是Linux本机调试,可以跳过此步,但是如果要开放给外网访问,就必须给redis设置密码。
注意:以上的设置都仅仅只是用于基于学习环境,正式的开发生产环境是一定不能这样子设置的。
上面设置完成后,重启redis服务,再远程连接,应该就没有什么问题了。
python使用redis的更多相关文章
- python之redis和memcache操作
Redis 教程 Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理.Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据 ...
- Python—操作redis
Python操作redis 连接方式:点击 1.String 操作 redis中的String在在内存中按照一个name对应一个value来存储 set() #在Redis中设置值,默认不存在则创建, ...
- python——操作Redis
在使用django的websocket的时候,发现web请求和其他当前的django进程的内存是不共享的,猜测django的机制可能是每来一个web请求,就开启一个进程去与web进行交互,一次来达到利 ...
- 【python】Redis介绍及简单使用
一.redis redis是一个key-value存储系统.和 Memcached类似,它支持存储的value类型相对更多,包括string(字符串). list(链表).set(集合).zset(s ...
- python之 Redis
Redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorte ...
- Python操作Redis、Memcache、RabbitMQ、SQLAlchemy
Python操作 Redis.Memcache.RabbitMQ.SQLAlchemy redis介绍:redis是一个开源的,先进的KEY-VALUE存储,它通常被称为数据结构服务器,因为键可以包含 ...
- python之redis
Redis简单介绍 如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构 ...
- python+php+redis+shell实现几台redis的同步数据
之所以使用python,是因为python多线程非常简单. 之所以使用shell,是因为写了个服务,可以方便的重启python写的那个脚本. 总体思路:利用redis的发布订阅,php作为生产者,py ...
- 使用 python 操作 redis
1.安装pyredis (1)使用 # easy_install redis (2)直接编译安装 #wget https://pypi.python.org/packages/source/r/red ...
- Python连接Redis连接配置
1. 测试连接: Python 2.7.8 (default, Oct 20 2014, 15:05:19) [GCC 4.9.1] on linux2 Type "help", ...
随机推荐
- Go语言系列文章
这个系列写的不是很好,未来重构. Go基础系列 Go基础 Go基础 1.Go简介 2.Go数据结构struct 3.构建Go程序 4.import导包和初始化阶段 5.array 6.Slice详解 ...
- 超级账本fabric原理之gossip详解
Goosip协议 去中心化.容错和最终一致性的算法 信息达到同步的最优时间:log(N). 功能: 节点发现 数据广播 gossip中有三种基本的操作: push - A节点将数据(key,value ...
- shell编程练习(四): 笔试31-68
笔试练习(四): 31.找查较多的SYN连接 netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uni ...
- 第46章 发现端点(Discovery Endpoint) - Identity Server 4 中文文档(v1.0.0)
发现端点可用于检索有关IdentityServer的元数据 - 它返回发布者名称,密钥材料,支持的范围等信息.有关详细信息,请参阅规范. 发现端点可通过/.well-known/openid-conf ...
- 解决MySQL报错The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents .....
1.前言 今天在用SpringBoot2.0+MyBatis+MySQL搭建项目开发环境的时候启动项目发现报了一个很奇怪的错,报错内容如下: java.sql.SQLException: The se ...
- C# 处理Excel公式(一)——创建、读取Excel公式
对于数据量较大的表格,需要计算一些特殊数值时,我们通过运用公式能有效提高我们数据处理的速度和效率,对于后期数据的增删改查等的批量操作也很方便.此外,对于某些数值的信息来源,我们也可以通过读取数据中包含 ...
- C# 绘制PDF图形——基本图形、自定义图形、色彩透明度
引言 在PDF中我们可以通过C#程序代码来添加非常丰富的元素来呈现我们想要表达的内容,如绘制表格.文字,添加图形.图像等等.在本篇文章中,我将介绍如何在PDF中绘制图形,并设置图形属性的操作. 文章中 ...
- nginx系列3:搭建一个静态资源web服务器
搭建静态资源web服务器 1,创建静态页面 在nginx的安装目录(/usr/local/nginx)下创建文件夹webapplications/helloworld,然后创建一个名为index.ht ...
- Pythoy 数据类型序列化——json&pickle 模块
Pythoy 数据类型序列化--json&pickle 模块 TOC 什么是序列化/反序列化 pickle 模块 json 模块 对比json和pickle json.tool 命令行接口 什 ...
- Flexbox弹性布局
Flexbox,一种CSS3的布局模式,也叫做弹性盒子模型,用来为盒装模型提供最大的灵活性.最新版本兼容IE11+.firefox.safari.chrome.opera及移动端,但移动端ios7.1 ...