分享知识-快乐自己:运行(wordcount)案例
运行 wordcount 案例:
-----------------------------------------------------------------
Hadoop集群测试wordcount程序:
1):在bigData目录下创建wordcount文件夹
mkdir wordcount //创建文件夹

2):在wordcount文件夹下创建两个文件并输入内容
//创建 file1.txt
vim file1.txt
//输入内容如下:
hello word
hello java
//创建 file2.txt
vim file2.txt
hello hadoop
hello wordcount
3):在HDFS中创建input文件夹
hadoop fs -mkdir /input // hadoop fs :可以理解为 hadoop系统文件目录
查看创建的文件(是否存在)

4):把刚才创建的两个文件上传到HDFS中input文件夹
//上传所有以 .txt 结尾的文件
hadoop fs -put ./*.txt /input/ //查看上传的文件
hadoop fs -ls /

注意:可能存在的问题:
查看当前正在运行的相关服务:
jps //没有规定要在哪一个目录执行
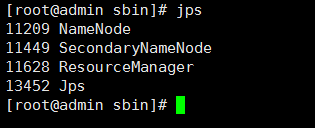
1):上传过程中可能出现以下错误:

解决方案:
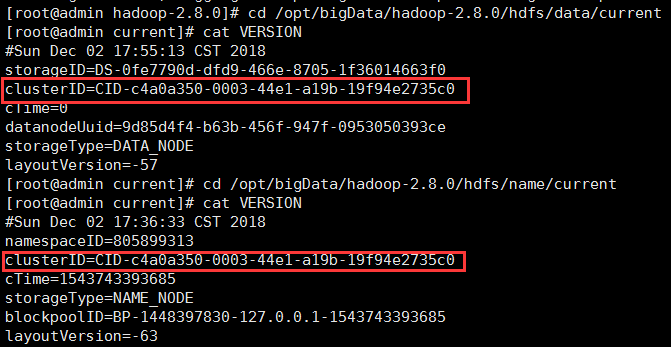
查看 配置 hdfs-site.xml 节点指定的路径【 name 和 data 】目录是否自动生成了(查看主机是否存在 name 和子机器上的 data)。
小编这里是没有生成 data 目录。
有了目录还需要注意:name 和 data 目录中的 id 必须一致:(如果不一致可以修改一下 或者 删除 name data logs tem 生成的目录 重新格式化并启动集群:查看是否有相应信息)
5):运行wordcount程序
Hadoop的 jar 包中已经给我们提供了 mapreduce 程序!都在 /bigData/hadoop-2.8.0/share/hadoop/mapreduce文件夹中!
切换到 share/hadoop/mapreduce 目录下:
cd share/hadoop/mapreduce
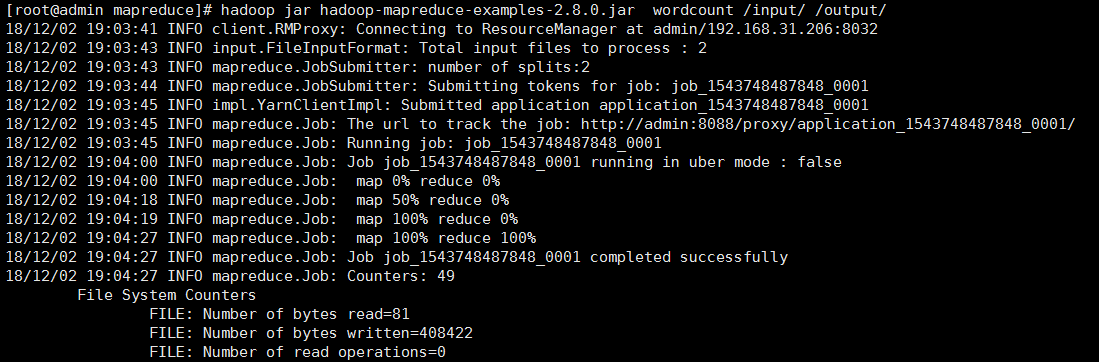
执行以下命令:
hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /input/ /output/
/input/ :是指需要计算文件所在的位置
/output/:是指计算之后的结果文件存放位置
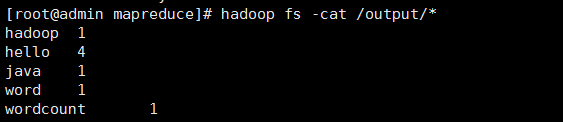
6):查看执行运算后的结果
hadoop fs -cat /output/*
Eclipse集成Hadoop插件:点我下载源码
如果eclipse是装在了真机windows系统中,需要我们在真机上安装hadoop!(同样将 hadoop 压缩包在 windows 上解压一份:【以管理员方式运行解压】)
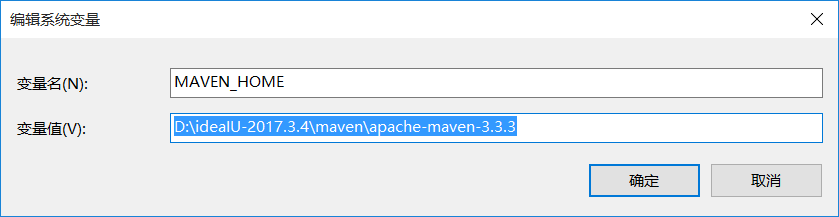
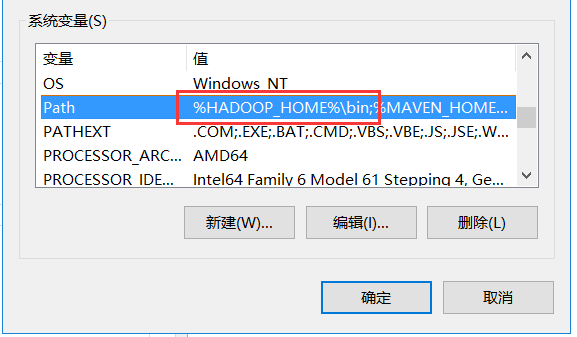
1):配置 windows hadoop环境变量:
2):使用 hadoop version 查看是否配置成功:

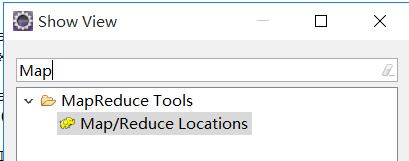
3):下载指定版本的插件:下载地址一 下载地址二
把插件放进 eclipse 安装目录下的 plugins 文件夹下
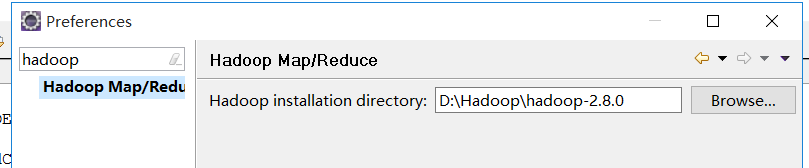
4):启动eclipse配置hadoop的安装目录
4-1):
4-2):
4-3):eclipse中显示插件的页面:

4-):
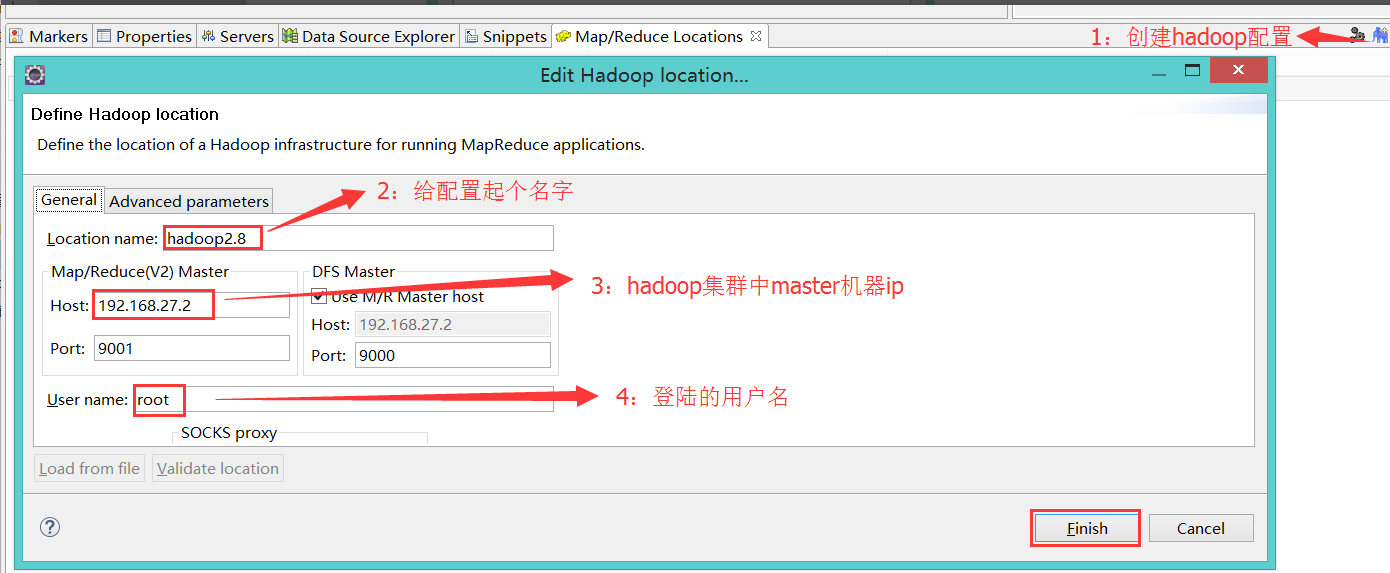
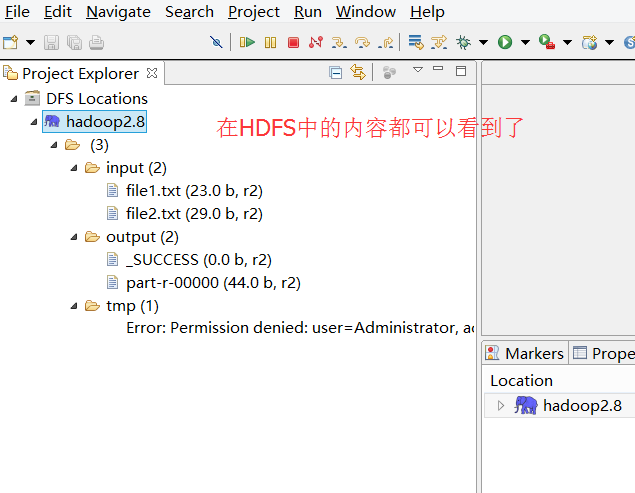
5):使用eclipse创建并运行wordcount程序
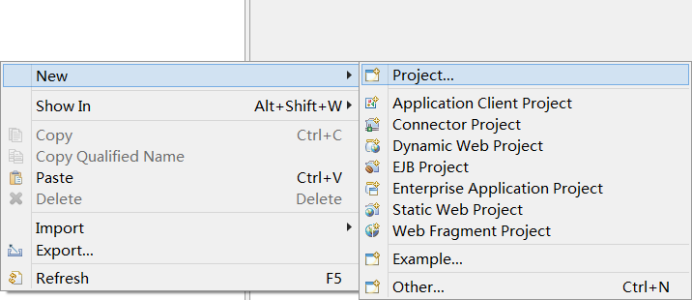
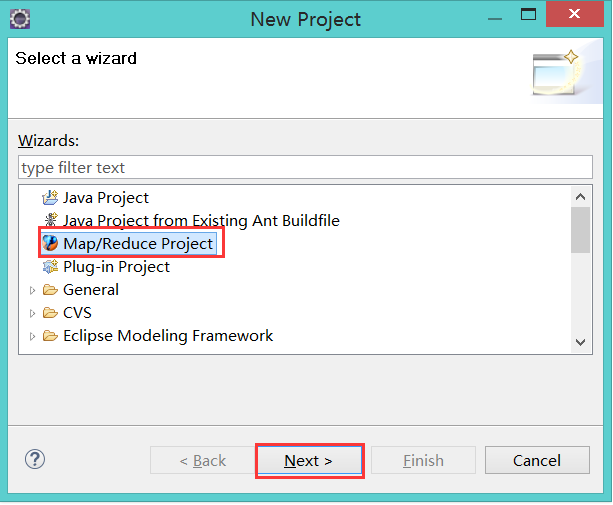

导入计算程序:
1):
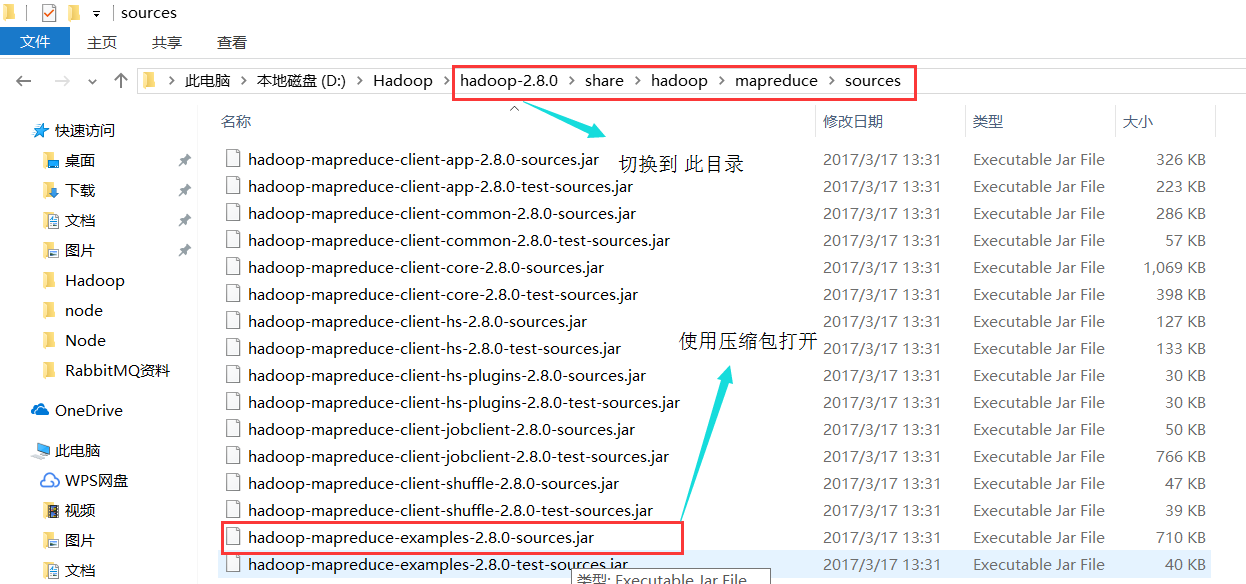
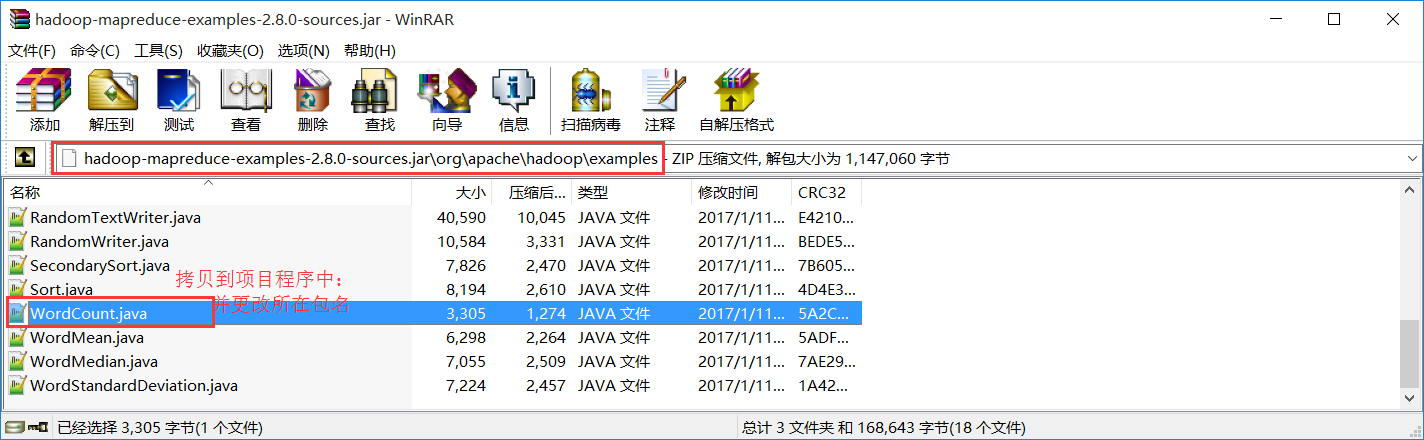
2):

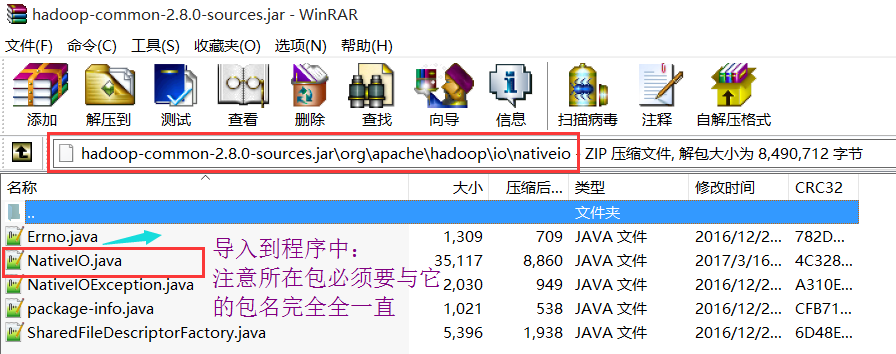
NativeIO:更改以下配置

目录结构:
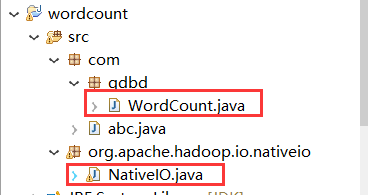
右键点击WordCount====》Run As ===》Run Configuration:
java Application 上 new:
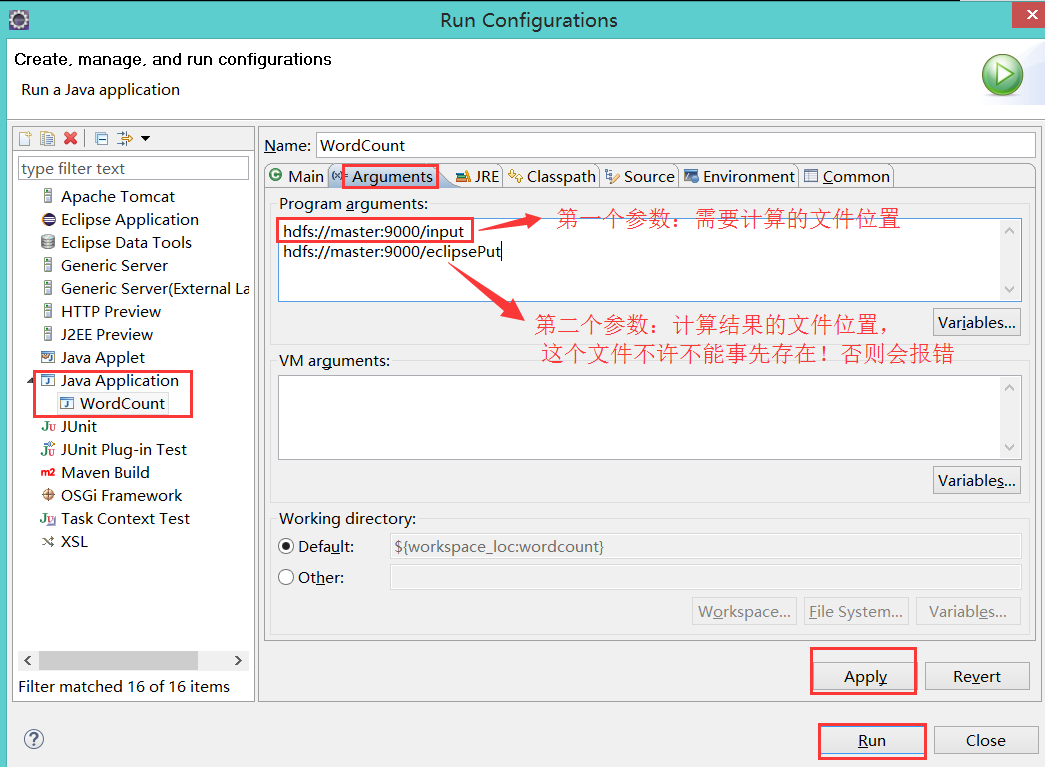
hdfs://admin:9000/input
hdfs://admin:9000/eclipseoutput
得到结果:
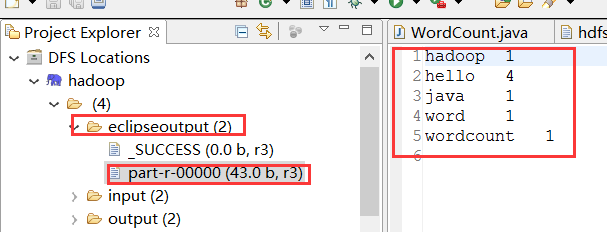
注意:Error 可能出现的错误...
1):有可能是本机的hadoop/bin目录下缺少hadoop.dll和winutils.exe等文件。(建议全部替换 hadoop/bin 下的所有文件。bin包在上述的下载地址中)
2):
org.apache.hadoop.security.AccessControlException: Permissiondenied: user=zhengcy, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x 在集群中运行hadoop fs -chmod -R 777 / 或者 修改三个虚拟机的配置:hdfs-site.xml
添加如下配置:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
3):
Exception in thread "main" java.lang.RuntimeException:
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems 解决方式:在 WordCount类中的main 方法中添加如下配置 System.setProperty("hadoop.home.dir", "hadoop安装目录");
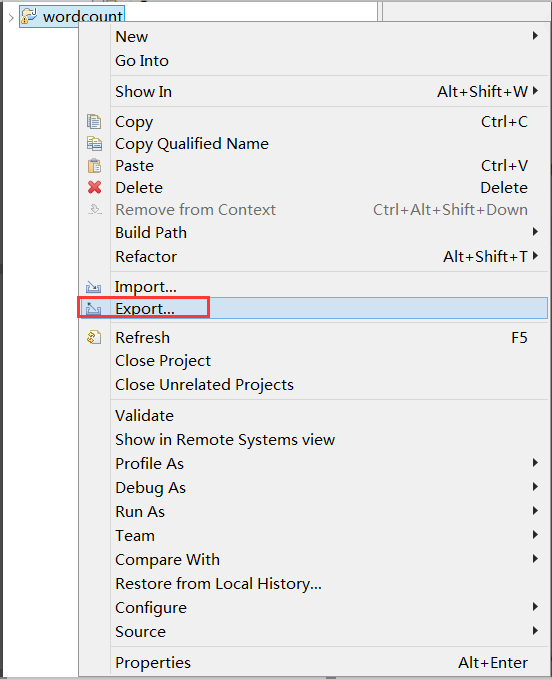
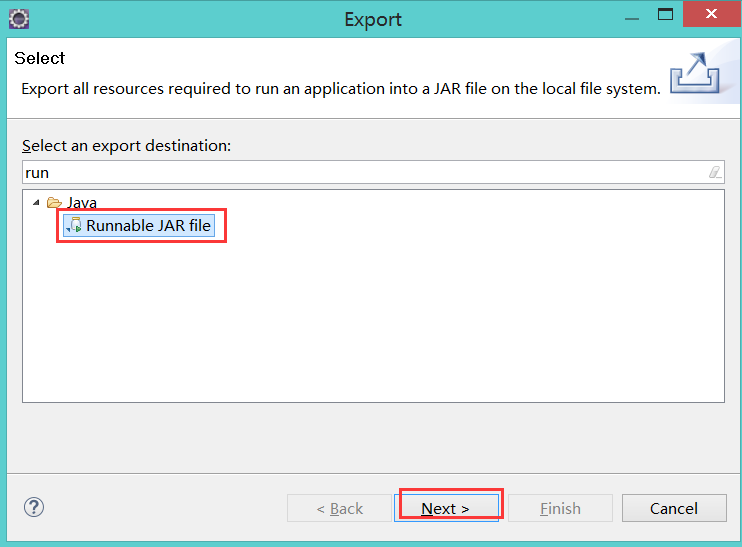
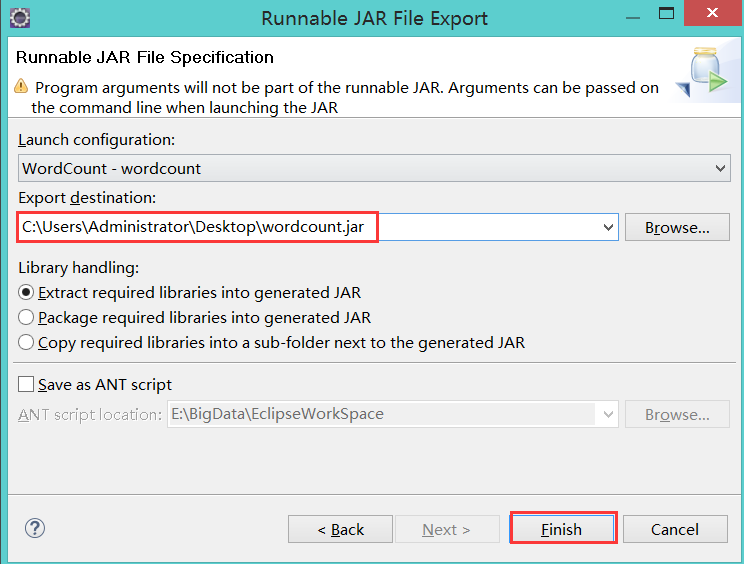
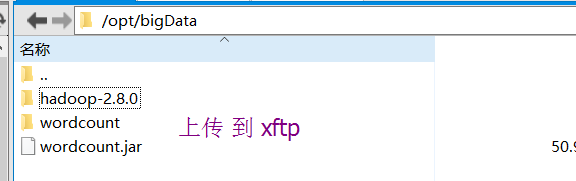
6):使用eclipse打成jar包发布到linux中运行

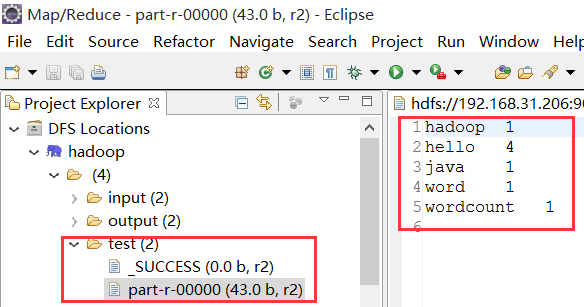
7):运行完毕之后,在eclipse中查看效果图!
分享知识-快乐自己:运行(wordcount)案例的更多相关文章
- 使用MapReduce运行WordCount案例
@ 目录 一.准备数据 二.MR的编程规范 三.编程步骤 四.编写程序 Mapper程序解读 一.准备数据 注意:准备的数据的格式必须是文本,每个单词之间使用制表符分割.编码必须是utf-8无bom ...
- 分享知识-快乐自己:Shrio 案例Demo概述
Shiro 权限认证核心: POM:文件: <!--shiro-all--> <dependency> <groupId>org.apache.shiro</ ...
- 分享知识-快乐自己:HBase编程
HBase编程: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘HBa ...
- 分享知识-快乐自己:揭秘HBase
揭秘HBase: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘HBa ...
- 分享知识-快乐自己:揭秘HDFS
揭秘HDFS: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘HBas ...
- 分享知识-快乐自己:Liunx-大数据(Hadoop)初始化环境搭建
大数据初始化环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘 ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- MapReduce简单执行过程及Wordcount案例
MapReducer运行过程 以单词统计为案例. 假如现在文件中存在如下内容: aa bb aa cc dd aa 当然,这是小文件,如果文件大小较大时会将文件进行 "切片" ,此 ...
- hadoop学习笔记:运行wordcount对文件字符串进行统计案例
文/朱季谦 我最近使用四台Centos虚拟机搭建了一套分布式hadoop环境,简单模拟了线上上的hadoop真实分布式集群,主要用于业余学习大数据相关体系. 其中,一台服务器作为NameNode,一台 ...
随机推荐
- 篇二、理解Android Studio的视图和目录分析,这个是转载
看不清的话可以可以将图片在新窗口中打开,以原图的大小显示. 原文链接:http://blog.csdn.net/siyehuazhilian/article/details/42123563 ...
- 如何在Windows 10 IoT Core中添加其他语言的支持,如中文
目前很多开发者已经开始使用Windows 10 IoT来做物联网领域的开发了,目前Windows 10 IoT Core的版本支持树莓派2(以及新出的树莓派3).Minnowboard Max以及Dr ...
- gen_server2 与gen_server的对比
在erlang杀手级应用rabbitmq中,不难发现,有一个gen_server2.erl模块.而在rabbitmq中,gen_server2.erl是对gen_server.erl模块的重写. Ra ...
- php 如何把中文写入json中 当json文件中还显示的是中文
/*** * 更新版本 */ function showupversionsub(){ #接受post 过来的数据 $app_type=$_POST['aap_type']; if($app_type ...
- 从头认识java-17.5 堵塞队列(以生产者消费者模式为例)
这一章节我们来讨论一下堵塞队列.我们以下将通过生产者消费者模式来介绍堵塞队列. 1.什么是堵塞队列?(摘自于并发编程网对http://tutorials.jenkov.com/java-concurr ...
- windows上mysql安装
1. 下载MySQL Community Server 5.7.14 Index of /MySQL/Downloads/MySQL-Cluster-7.1 2. 解压MySQL压缩包 安装路径:E: ...
- .Net 开发Windows Service
1.首先创建一个Windows Service 2.创建完成后切换到代码视图,代码中默认有OnStart和OnStop方法执行服务开启和服务停止执行的操作,下面代码是详细解释: using Syste ...
- 统计输入的单词中有几个长度大于n的,n是自己指定的,用函数对象实现
#ifndef COUNT_WORD_H #define COUNT_WORD_H #include <string.h> #include <iostream> #inclu ...
- ShareSDK 微博空间分享
本文转载至 http://blog.csdn.net/learnios/article/details/8992346 ShareSDK微博分享空间分享新浪微博腾讯微博 第一步:首先导入ShareSD ...
- iphone传感器
传感器 什么是传感器 传感器是一种感应\检测装置, 目前已经广泛应用于智能手机上 传感器的作用 用于感应\检测设备周边的信息 不同类型的传感器, 检测的信息也不一样 iPhone中的下面现象都是由传感 ...