Hadoop WordCount单词计数原理
计算文件中出现每个单词的频数
输入结果按照字母顺序进行排序

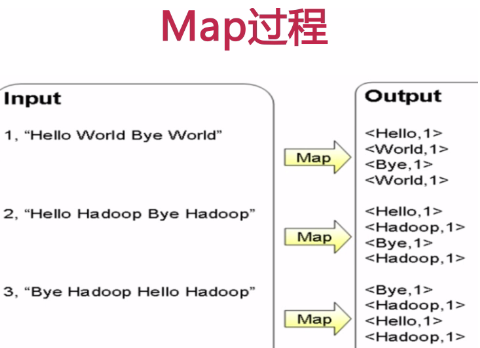
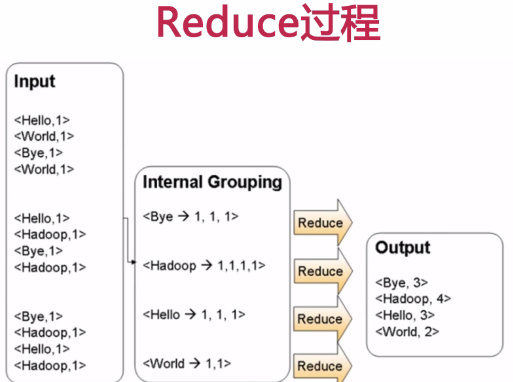
- 编写WordCount.java 包含Mapper类和Reducer类
- 编译WordCount.java javac -classpath
- 打包jar -cvf WordCount.jar classes/*
- 提交作业
- hadoop jar WordCount.jar WordCount input output
Hadoop WordCount单词计数原理的更多相关文章
- hadoop笔记之MapReduce的应用案例(WordCount单词计数)
MapReduce的应用案例(WordCount单词计数) MapReduce的应用案例(WordCount单词计数) 1. WordCount单词计数 作用: 计算文件中出现每个单词的频数 输入结果 ...
- 第一个Hadoop程序-单词计数
上一篇配置了Hadoop,本文将测试一个Hadoop的小案例 hadoop的Wordcount程序是hadoop自带的一个小的案例,是一个简单的单词统计程序,可以在hadoop的解压包里找到,如下: ...
- Spark本地环境实现wordCount单词计数
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6814778610788860424/ 编写类似MapReduce的案例-单词统计WordCount 要统计的文件为 ...
- Hadoop分布环境搭建步骤,及自带MapReduce单词计数程序实现
Hadoop分布环境搭建步骤: 1.软硬件环境 CentOS 7.2 64 位 JDK- 1.8 Hadoo p- 2.7.4 2.安装SSH sudo yum install openssh-cli ...
- Hadoop: 单词计数(Word Count)的MapReduce实现
1.Map与Reduce过程 1.1 Map过程 首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce.Hadoop为每个分片创建一个map任务 ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- Spark: 单词计数(Word Count)的MapReduce实现(Java/Python)
1 导引 我们在博客<Hadoop: 单词计数(Word Count)的MapReduce实现 >中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来 ...
- MapReduce之单词计数
最近在看google那篇经典的MapReduce论文,中文版可以参考孟岩推荐的 mapreduce 中文版 中文翻译 论文中提到,MapReduce的编程模型就是: 计算利用一个输入key/value ...
- 单词计数-MapReduceJob
pom文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3. ...
随机推荐
- ubantu删除文件(夹)
格式:rm -rf 目录名字 -r 就是向下递归,不管有多少级目录,一并删除 -f 就是直接强行删除,不作任何提示的意思 名称 rm - 移除文件或者目录 概述 rm [选项]... 文件列表... ...
- 十五 Django框架,缓存
由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加明显,最简单解决方式是使用:缓存,缓存将一个某个views的返回值保存至内存或者memcache中,5 ...
- Linux_笔记_01_设置静态IP与 SecureCRT连接Linux
步骤一至三,即可设置好静态IP 步骤四至九,使SecureCRT连接Linux 步骤一:编辑ifcfg-eth0 文件 1.打开ifcfg-eth0 文件 使用命令:vi /etc/sysconfig ...
- Javascript-- jQuery 核心
jQuery中each方法的应用 jQuery中有个很重要的核心方法each,大部分jQuery方法在内部都会调用each,其主要的原因的就是jQuery的实例是一个元素合集 如下:找到所有的div, ...
- 如何使 vlc 支持 fdk-aac 编码(windows平台
可能是由于fdk-aac开源协议的原因,VLC默认是不支持fdk-aac编码的,fdk-aac 是非常优秀的AAC编码库,并且支持AAC-LD AAC-ELD, 对于要求低延迟的场景下很有用. 可以通 ...
- elasticsearch监控平台cerebro-0.8.3 相关操作
上面这个平台是cerebro-0.8.3 在github上找就有了 #################### GET /hnscan_source_o_comm_drv_bad_bhv_occur/ ...
- 【LeetCode】048. Rotate Image
题目: You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwis ...
- photonView 空指针异常
1.OBJ上要有PhotonView 脚本 2.PhotonNetwork.Instantiate方法初始化出来OBJ OBJ 预制体要放在Resources文件夹下 PhotonNetwork.In ...
- 51nod 1486 大大走格子——容斥
题目:http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1486 已知起点到某个障碍点左上角的所有点的不经过障碍的方案数,枚举 ...
- mysql5.5主从同步复制配置
在上篇文章<烂泥:学习mysql数据库主从同步复制原理>中,我们介绍了有关mysql主从复制的基本原理.在这篇文章中,我们来实际测试下mysql5.5的主从同步复制功能. 注意mysql5 ...