MySQL索引扩展(Index Extensions)学习总结
MySQL InnoDB的二级索引(Secondary Index)会自动补齐主键,将主键列追加到二级索引列后面。详细一点来说,InnoDB的二级索引(Secondary Index)除了存储索引列key值,还存储着主键的值(而不是指向主键的指针)。为什么这样做呢?因为InnoDB是以聚集索引方式组织数据的存储,即主键值相邻的数据行紧凑的存储在一起(索引组织表)。当数据行移动或者发生页分裂的时候,可以减少大量的二级索引维护工作。InnoDB移动行时,无需更新二级索引。我们以官方文档的例子来测试:
CREATE TABLE t1 (
i1 INT NOT NULL DEFAULT 0,
i2 INT NOT NULL DEFAULT 0,
d DATE DEFAULT NULL,
PRIMARY KEY (i1, i2),
INDEX k_d (d)
) ENGINE = InnoDB;
如上所示,这个t1表包含主键和二级索引k_d,二级索引k_d(d)的元组在InnoDB内部实际被扩展成(d,i1,i2),即包含主键值。因此在设计主键的时候,常见的一条设计原则是要求主键字段尽量简短,以避免二级索引过大(因为二级索引会自动补齐主键字段)。
优化器会考虑扩展二级索引的主键列,确定什么时候使用以及如何使用该索引。 这样可以产生更高效的执行计划和达到更好的性能。有不少博客介绍索引扩展是从MySQL5.6.9开始引入的。不过个人还没有在官方文档看到相关资料。
优化器可以用扩展的二级索引来进行ref,range,index_merge等类型索引访问(index access),松散的索引扫描(index sacns),连接和排序优化,以及min()/max()优化。
我们先来插入测试数据(脚本来自官方文档):
INSERT INTO t1 VALUES
(1, 1, '1998-01-01'), (1, 2, '1999-01-01'),
(1, 3, '2000-01-01'), (1, 4, '2001-01-01'),
(1, 5, '2002-01-01'), (2, 1, '1998-01-01'),
(2, 2, '1999-01-01'), (2, 3, '2000-01-01'),
(2, 4, '2001-01-01'), (2, 5, '2002-01-01'),
(3, 1, '1998-01-01'), (3, 2, '1999-01-01'),
(3, 3, '2000-01-01'), (3, 4, '2001-01-01'),
(3, 5, '2002-01-01'), (4, 1, '1998-01-01'),
(4, 2, '1999-01-01'), (4, 3, '2000-01-01'),
(4, 4, '2001-01-01'), (4, 5, '2002-01-01'),
(5, 1, '1998-01-01'), (5, 2, '1999-01-01'),
(5, 3, '2000-01-01'), (5, 4, '2001-01-01'),
(5, 5, '2002-01-01');
#默认情况下,索引扩展(use_index_extensions)选项是开启的。可以在当前会话通过修改优化器开关optimizer_switch开启、关闭此选项。
mysql> show variables like '%optimizer_switch%';
mysql> SET optimizer_switch = 'use_index_extensions=off';
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN
-> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| 1 | SIMPLE | t1 | ref | PRIMARY,k_d | k_d | 4 | const | 5 | Using where; Using index |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
这种情况下,优化器不会使用主键,因为主键由字段(i1,i2)组成,但是该查询中没有引用t2字段;优化器会选择二级索引 k_d(d) 。
我们将use_index_extensions选项在当前会话开启,那么SQL语句的执行计划会怎样变化呢?
mysql> SET optimizer_switch = 'use_index_extensions=on';
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN
-> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
| 1 | SIMPLE | t1 | ref | PRIMARY,k_d | k_d | 8 | const,const | 1 | Using index |
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
1 row in set (0.00 sec)
mysql>
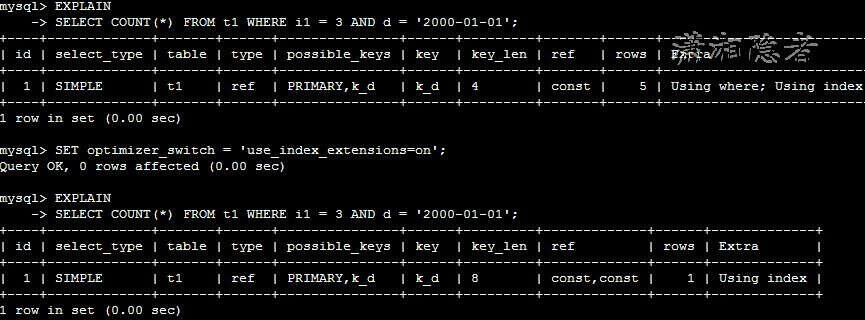
当use_index_extensions=off的时候,仅使用索引k_d中d列的数据,忽略了扩展的主键列的数据。而use_index_extensions=on时,使用了k_d索引中(i1,i2,d)三列的数据。可以从上面两种情况下的explain输出结果中信息得以验证。
key_len:由4变到8,说明不仅仅使用了d列上的索引,而且使用了扩展的主键i1列的数据
ref:由const变为”const,const”, 使用了索引的两部分。
rows:从5变为1,表明InnoDB只需要检查更少的数据行就可以产生结果集。
Extra:”Using index,Using where” 变为”Using index”。通过索引覆盖就完成数据查询,而不需要读取任何的数据行。官方文档的介绍如下:
The Extra value changes from Using where; Using index to Using index. This means that rows can be read using only the index, without consulting columns in the data row.
其实关于这两者的区别,查了很多资料都没有彻底搞清楚”Using index,Using where”与”Using index”的区别。此处不做展开。
另外,从status信息中“Handler_read_%”相关状态值可以观察实际执行过程中索引和数据行的访问统计。
flush table 关闭已打开的数据表,并清除缓存(表缓存和查询缓存)。
flush status 把status计数器清零。
Handler_read_key:The number of requests to read a row based on a key. If this value is high, it is a good indication that your tables are properly indexed for your queries.
Handler_read_next:The number of requests to read the next row in key order. This value is incremented if you are querying an index column with a range constraint or if you are doing an index scan.(此选项表明在进行索引扫描时,按照索引从数据文件里取数据的次数。)
关闭use_index_extensions情况下,status的统计信息
mysql> SET optimizer_switch = 'use_index_extensions=off';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH TABLE t1;
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH STATUS;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
mysql> SHOW STATUS LIKE 'handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 0 |
| Handler_read_key | 1 |
| Handler_read_last | 0 |
| Handler_read_next | 5 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
+-----------------------+-------+
7 rows in set (0.00 sec)
开启use_index_extensions情况下,status的统计信息
mysql> SET optimizer_switch = 'use_index_extensions=on';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH TABLE t1;
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH STATUS;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
mysql> SHOW STATUS LIKE 'handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 0 |
| Handler_read_key | 1 |
| Handler_read_last | 0 |
| Handler_read_next | 1 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
+-----------------------+-------+
7 rows in set (0.00 sec)
mysql>
对比两个执行计划,发现Handler_read_next的值从5变为1,表明索引的访问效率更高了,减少了数据行的读取次数。
本文结合官方文档Use of Index Extensions和自己理解整理。
参考资料:
https://docs.oracle.com/cd/E17952_01/mysql-5.6-en/index-extensions.html
https://dev.mysql.com/doc/refman/5.6/en/index-extensions.html
http://blog.51cto.com/huanghualiang/1557306
http://reckey.iteye.com/blog/2258450
MySQL索引扩展(Index Extensions)学习总结的更多相关文章
- MySQL索引的Index method中btree和hash的优缺点
MySQL索引的Index method中btree和hash的区别 在MySQL中,大多数索引(如 PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)都是在BTREE中存储,但使用 ...
- MySQL索引与Index Condition Pushdown
实际上,这个页面所讲述的是在MariaDB 5.3.3(MySQL是在5.6)开始引入的一种叫做Index Condition Pushdown(以下简称ICP)的查询优化方式.由于本身不是一个层面的 ...
- MySQL索引与Index Condition Pushdown(employees示例)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- MySQL索引与Index Condition Pushdown(二)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- MySQL—索引(Index)
前言: 关于MySql索引数据结构和实现原理的讲解值得阅读一下: 实现原理:https://www.cnblogs.com/songwenjie/p/9415016.htm 索引数据结构:https: ...
- 8.2.1.7 Use of Index Extensions 使用索引扩展
8.2.1.7 Use of Index Extensions 使用索引扩展 InnoDB 自动扩展每个secondary index 通过添加primary key columns to it,考虑 ...
- 重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化
重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化 一:Mysql原理与慢查询 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
- MySQL学习(4)---MySQL索引
ps:没有特殊说明,此随笔中默认采用innoDB存储引擎中的索引,且索引都是指B+树(多路平衡搜索树)结构组织的索引.其中聚集索引.复合索引.前缀索引.唯一索引默认都是使用B+树,统称为索引. 索引概 ...
随机推荐
- C++版 - 剑指offer 面试题16:反转链表(Leetcode 206: Reverse Linked List) 题解
面试题16:反转链表 提交网址: http://www.nowcoder.com/practice/75e878df47f24fdc9dc3e400ec6058ca?tpId=13&tqId= ...
- Android--多线程之图文混排
前言 本周一直在说Android多线程的那些事儿,本篇博客聊一聊Android开发中一个比较经典的案例,网络数据图文混排,本片博客的案例只涉及关于开启多线程访问网络数据,不涉及缓存的内容.众所周知,从 ...
- ADO.NET的整理
ADO.NET的几个对象 Connection:管理数据库的连接 Command:对数据库执行命令 DataReader:数据流读取器,返回的数据都是快速的且只是“向前”的数据流.无法实例化,只能通过 ...
- 禁用feign retryer
为什么要禁用retryer?其实主要是为了Debug,禁用feign retryer有两面性,如果接口做好幂等性,retry不影响,但是总有一些意外发生,比如:有一个实例发生了故障而该情况还没有被服务 ...
- oracle触发器使用
转自: http://www.cnblogs.com/wishyouhappy/p/3665851.html 1.说明 1)触发器是一种特殊的存储过程,触发器一般由事件触发并且不能接受参数,存储器由语 ...
- mysql常用字符串操作函数大全,以及实例
今天在论坛中看到一个关于mysql的问题,问题如下 good_id cat_id12654 665,56912655 601,4722 goods_id是商品i ...
- 3分钟看完Java 8——史上最强Java 8新特性总结之第二篇 Stream API
目录 · 概况 · 切片(Slicing) · 映射(Mapping) · 匹配(Matching) · 查找(Finding) · 归约(Reducing) · 排序(Sorting) · 数值流( ...
- 网络协议抓包分析——ARP地址解析协议
前言 计算机之间可以相互通信的前提是要知道对方的地址,才可以发送信息给其他计算机,就像别人要联系你也得先知道你的电话号码一样.这里的地址因为网络分层的原因就包括IP地址和MAC地址(即网卡地址.硬件地 ...
- UnicodeDecodeError: 'ascii' codec can't decode byte
这个问题遇到过很多次了,但是每次都没记住,用完就忘了,这次记录下. 通过关键词谷歌一下: 解决方案: # encoding=utf8 import sys reload(sys) sys.setdef ...
- 【golang-GUI开发】项目的编译
在上一篇文章里,我们讲到了安装therecipe/qt(https://www.cnblogs.com/apocelipes/p/9296754.html),现在我们来讲讲如何编译使用了thereci ...