基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战
完整代码实现见github:click me
一、实验说明
1.1 任务描述

1.2 数据说明
一共有十个数据集,数据集中的数据属性有全部是离散型的,有全部是连续型的,也有离散与连续混合型的。通过对各个数据集的浏览,总结出各个数据集的一些基本信息如下:
连续型数据集:
1. diabets(4:8d-2c)
2. mozilla4(6:5d-2c)
3. pc1(7:21d-2c)
4. pc5(8:38d-2c)
5. waveform-5000(9:40d-3c)
离散型数据集:
1. breast-w(0:9d-2c-?)
离散-连续混合型数据集:
1. colic(1:22d-2c-?)
2. credit-a(2:15d-2c-?)
3. credit-g(3:20d-2c)
4. hepatitis(少量离散属性)(5:19d-2c-?)
举一个例子说明,colic(1:22d-2c-?)对应colic这个数据集,冒号前面的1表示人工标注的数据集序号(在代码实现时我是用序号来映射数据集的),22d表示数据集中包含22个属性,2c表示数据集共有3种类别,'?'表示该数据集中含有缺失值,在对数据处理前需要注意。
二、数据预处理
由于提供的数据集文件格式是weka的.arff文件,可以直接导入到weka中选择各类算法模型进行分析,非常简便。但是我没有借助weka而是使用sklearn来对数据集进行分析的,这样灵活性更大一点。所以首先需要了解.arff的数据组织形式与结构,然后使用numpy读取到二维数组中。
具体做法是过滤掉.arff中'%'开头的注释,对于'@'开头的标签,只关心'@attribute'后面跟着的属性名与属性类型,如果属性类型是以'{}'围起来的离散型属性,就将这些离散型属性映射到0,1,2......,后面读取到这一列属性的数据时直接用建好的映射将字符串映射到数字。除此之外就是数据内容了,读完一个数据集的内容之后还需要检测该数据集中是否包含缺失值,这个使用numpy的布尔型索引很容易做到。如果包含缺失值,则统计缺失值这一行所属类别中所有非缺失数据在缺失属性上各个值的频次,然后用出现频次最高的值来替换缺失值,这就完成对缺失值的填补。具体实现可以参见preprocess.py模块中fill_miss函数。
三、代码设计与实现
实验环境:
python 3.6.7
configparser 3.7.4
scikit-learn 0.20.2
numpy 1.15.4
matplotlib 3.0.3
各个分类器都要用到的几个模块在这里做一个简要说明。
- 交叉验证: 使用sklearn.model_selection.StratifiedKFold对数据作分层的交叉切分,分类器在多组切分的数据上进行训练和预测
- AUC性能指标: 使用sklearn.metrics.roc_auc_score计算AUC值,AUC计算对多类(二类以上)数据属性还需提前转换成one hot编码,使用了sklearn,preprocessing.label_binarize来实现,对于多分类问题选择micro-average
- 数据标准化: 使用sklearn.preprocessing.StandardScaler来对数据进行归一标准化,实际上就是z分数
3.1 朴素贝叶斯Naive Bayes
由于大部分数据集中都包含连续型属性,所以选择sklearn.naive_bayes.GaussianNB来对各个数据集进行处理
clf = GaussianNB()
skf = StratifiedKFold(n_splits=10)
skf_accuracy1 = []
skf_accuracy2 = []
n_classes = np.arange(np.unique(y).size)
for train, test in skf.split(X, y):
clf.fit(X[train], y[train])
skf_accuracy1.append(clf.score(X[test], y[test]))
if n_classes.size < 3:
skf_accuracy2.append(roc_auc_score(y[test], clf.predict_proba(X[test])[:, 1], average='micro'))
else:
ytest_one_hot = label_binarize(y[test], n_classes)
skf_accuracy2.append(roc_auc_score(ytest_one_hot, clf.predict_proba(X[test]), average='micro'))
accuracy1 = np.mean(skf_accuracy1)
accuracy2 = np.mean(skf_accuracy2)
在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
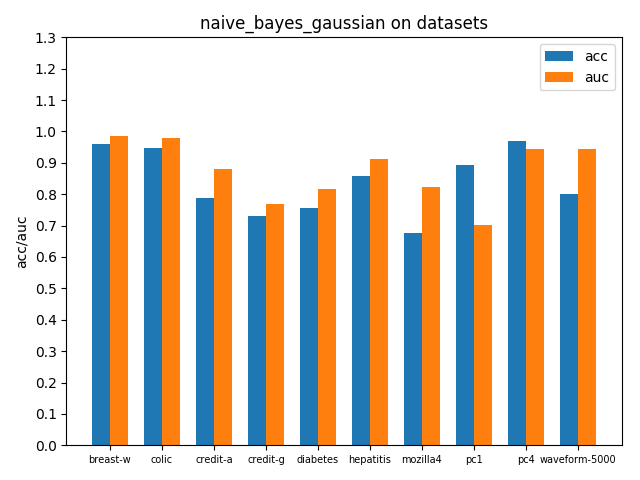
可以看到大部分数据集上的auc指标都比acc高,说明控制好概率阈值(这里默认0.5)acc可能还有提升空间,因为样本分布跟总体分布还有一定的差距,样本数布可能很不平衡,并且权衡一个合适的阈值点还需要结合分类问题的背景和关注重点。由于auc指标考虑到了所有可能阈值划分情况,auc越高能说明模型越理想,总体上能表现得更好。
3.2 决策树decision tree
使用sklearn.tree.DecisionTreeClassifier作决策树分析,并且采用gini系数选择效益最大的属性进行划分,下面给出接口调用方式,交叉验证方式与前面的naive bayes一样
clf = DecisionTreeClassifier(random_state=0, criterion='gini')
在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
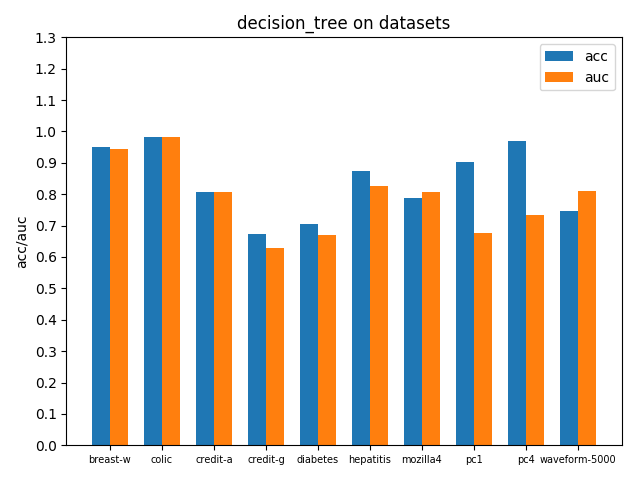
3.3 K近邻KNN
使用sklearn.neighbors.KNeighborsClassifier实现KNN,邻居数设置为3即根据最近的3个邻居来投票抉择样本所属分类,因为数据集最多不超过3类,邻居数选择3~6较为合适,设得更高效果增益不明显并且时间开销大,下面给出接口调用方式
clf = KNeighborsClassifier(n_neighbors=3)
在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
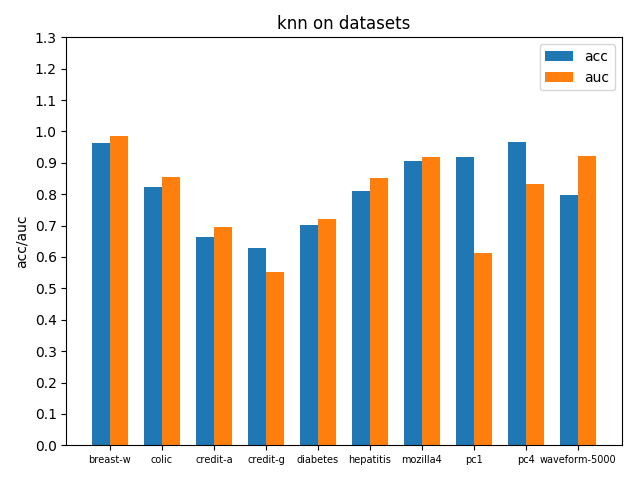
3.4 神经网络之多层感知机MLP
使用sklearn.neural_network.MLPClassifier实现MLP,设置一层隐藏层100个节点,激活函数relu,优化器Adam,学习率1e-3并且自适应降低,l2正则项惩罚系数,下面给出具体的接口调用方式以及参数配置
clf = MLPClassifier(hidden_layer_sizes=(100),
activation='relu',
solver='adam',
batch_size=128,
alpha=1e-4,
learning_rate_init=1e-3,
learning_rate='adaptive',
tol=1e-4,
max_iter=200)
在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
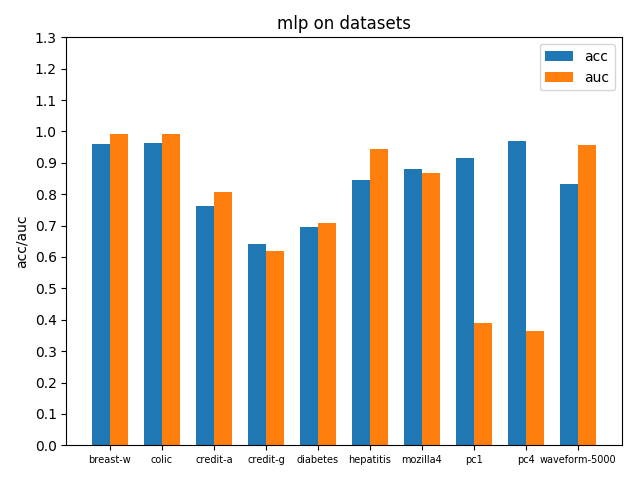
3.5 支持向量机SVM
使用sklean.svm.LinearSVC实现线性SVM分类器,接口调用方式如下
clf = LinearSVC(penalty='l2', random_state=0, tol=1e-4)
在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
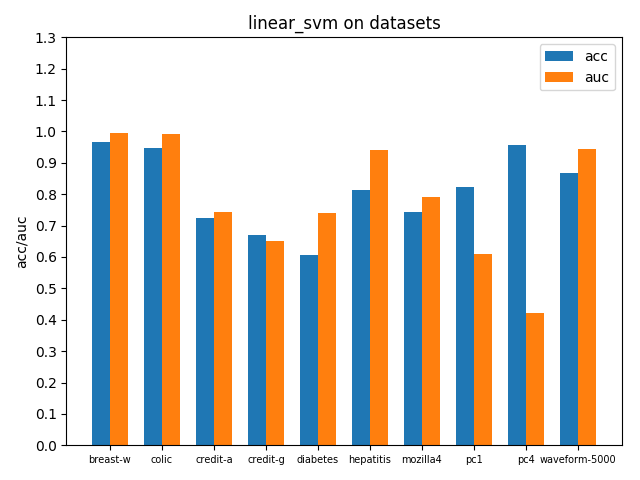
四、实验结果与分析
4.1 不同数据集上的模型对比
4.1.1 breast-w dataset
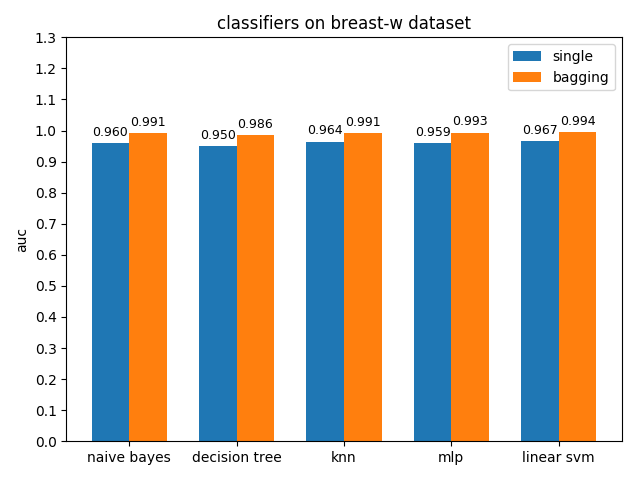
breast-w数据集上,各分类模型的效果都很好,其中linear svm的准确率最高,mlp的auc值最高
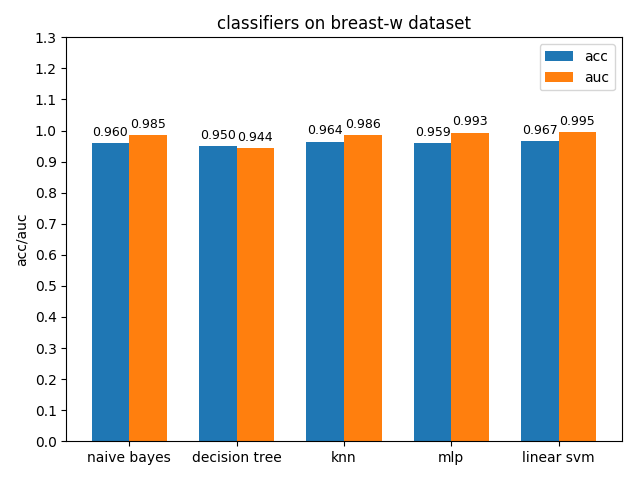
4.1.2 colic dataset
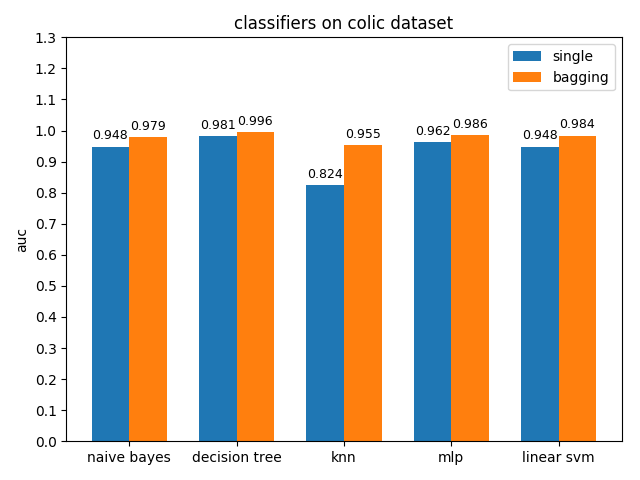
colic数据集上,knn效果不佳,其它分类模型的效果都很好,其中decision tree的准确率最高,mlp的auc值最高
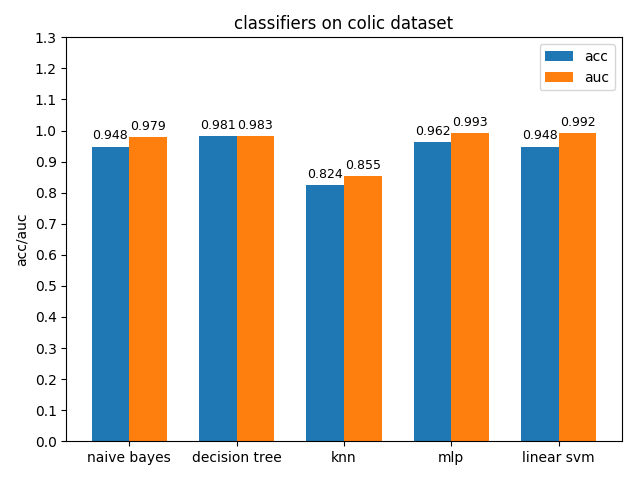
4.1.3 credit-a dataset
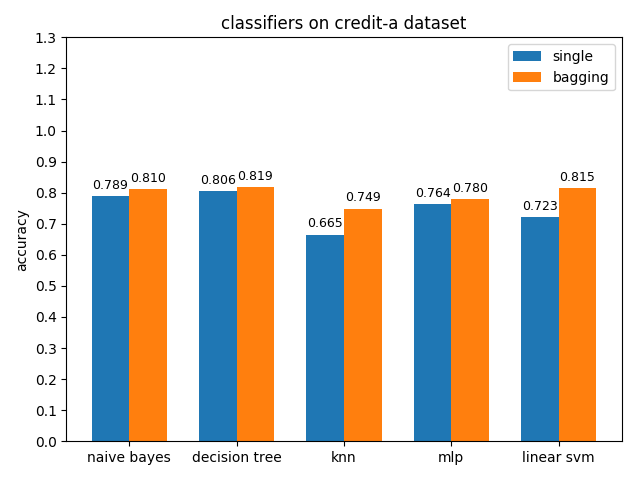
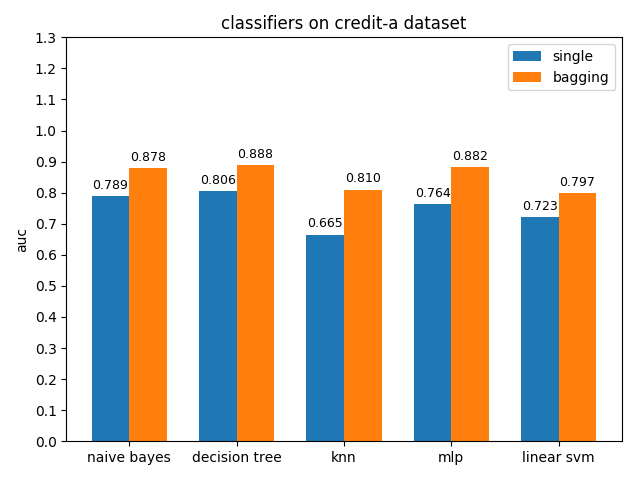
credit-a数据集上,各分类模型的效果都不是很好,其中decision tree的准确率最高,naive bayes的auc值最高
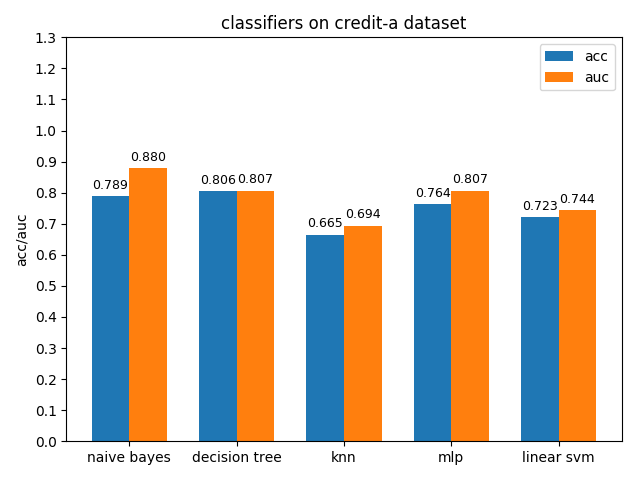
4.1.4 credit-g dataset
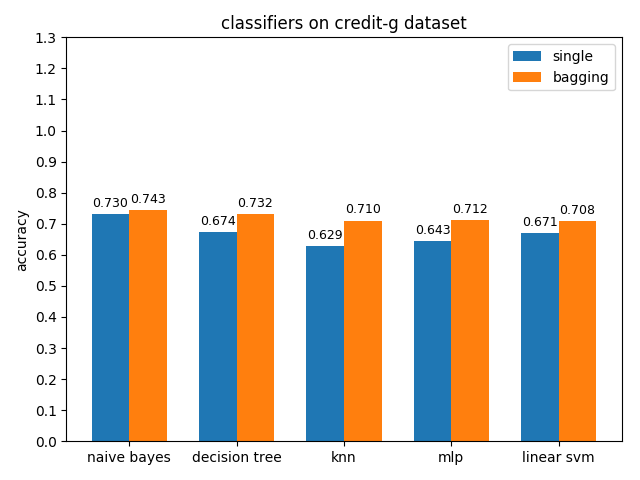
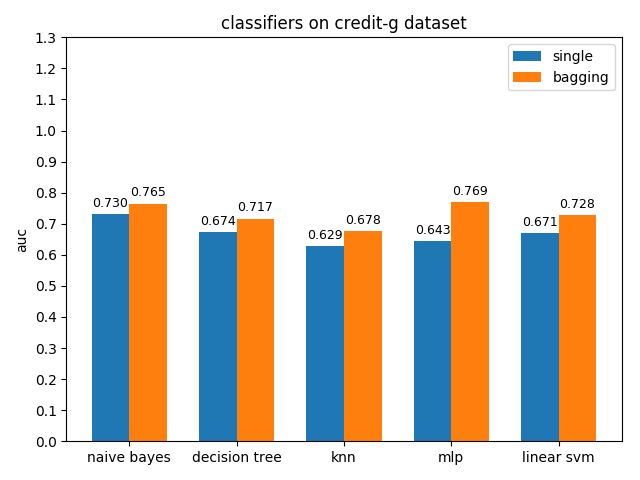
credit-a数据集上,各分类模型的效果都不是很好,其中naive bayes的准确率和auc值都是最高的
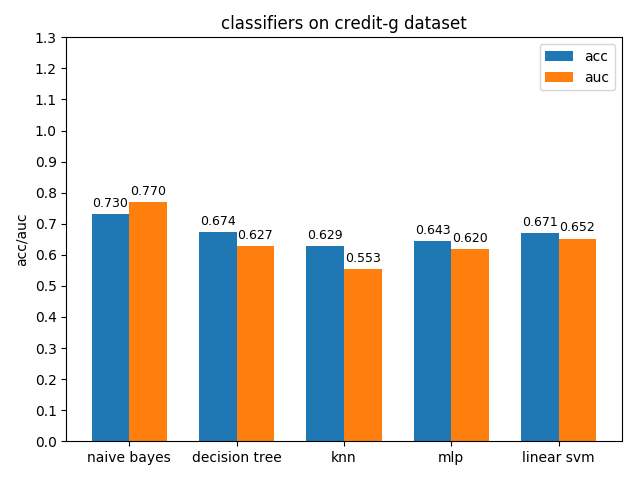
4.1.5 diabetes dataset
diabetes数据集上,各分类模型的效果都不是很好,其中naive bayes的准确率和auc值都是最高的
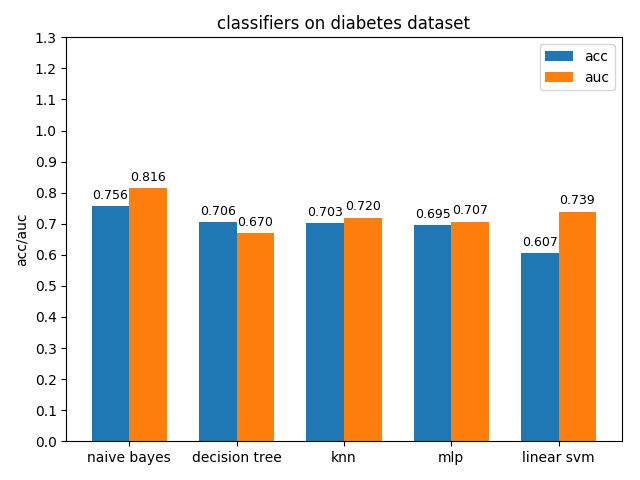
4.1.6 hepatitis dataset
hepatitis数据集上,各分类模型的准确率都没达到90%,decision tree的准确率最高,mlp的auc值最高,但是各分类模型的auc值基本都比acc高除了decision tree,说明hepatitis数据集的数据分布可能不太平衡
通过weka对hepatitis数据集上的正负类进行统计得到下面的直方图
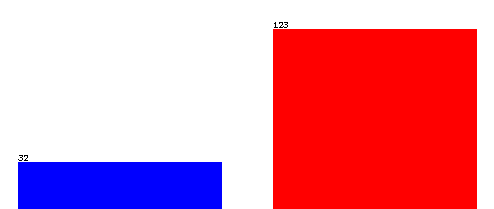
从上面的直方图可以验证之前的猜测是对的,hepatitis数据集正负类1:4,数据分布不平衡,正类远少于负类样本数
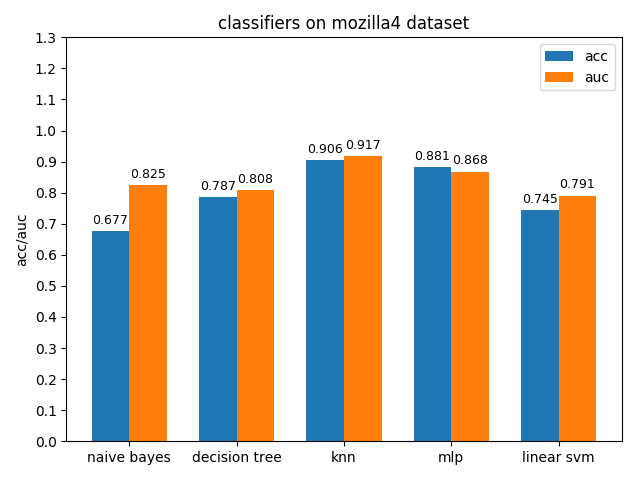
4.1.7 mozilla4 dataset
mozilla4数据集上,各分类模型的表现差异很大,其中knn的acc和auc都是最高的,naivie bayes的acc和auc相差甚大
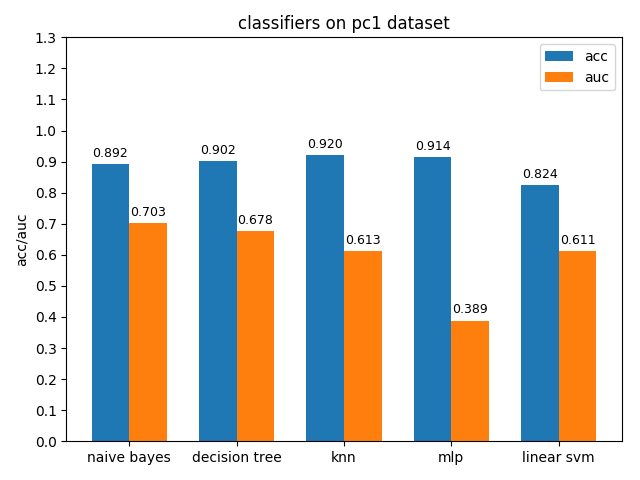
4.1.8 pc1 dataset
pc1数据集上,各分类模型的准确率基本都挺高的,但是auc值普遍都很低,使用weka对数据进行统计分析后发现pc1数据集的正负类比达到13:1,根据auc计算原理可知正类太多可能会导致TPR相比FPR会低很多,从而压低了auc值
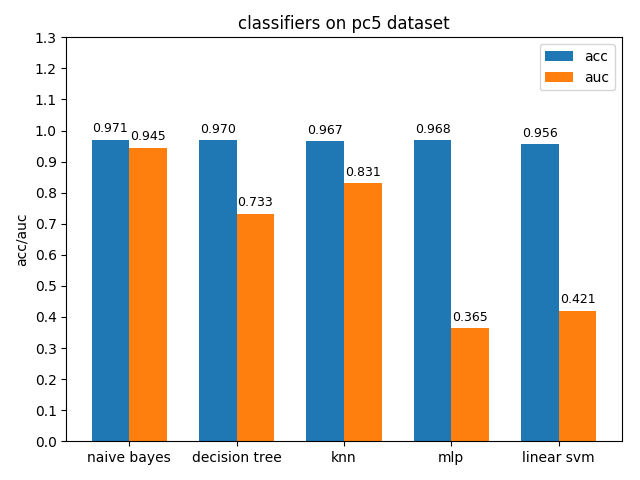
4.1.9 pc5 dataset
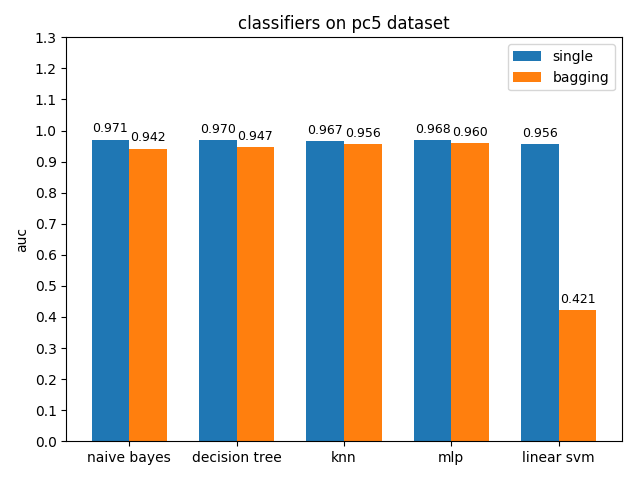
pc5数据集上,各分类模型的准确率都达到了90%以上,但是auc都比acc要低,其中mlp和linear svm的acc与auc相差甚大,原因估计和pc1差不多,正类样本太多拉低了AUC,使用weka分析后发现pc5正负类样本比值达到了32:1,并且数据中夹杂着些许异常的噪声点
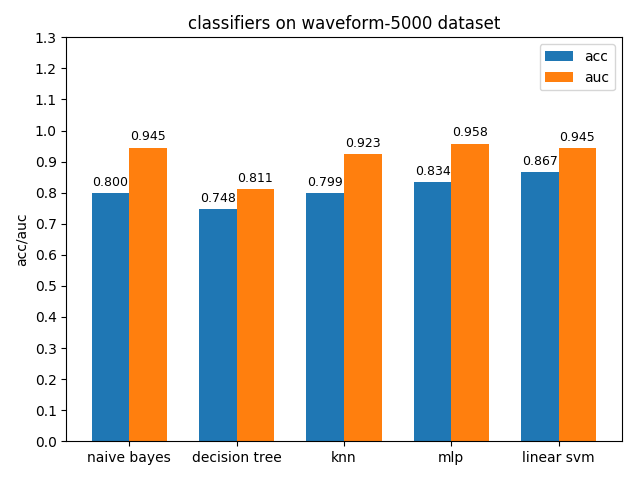
4.1.10 waveform-5000 dataset
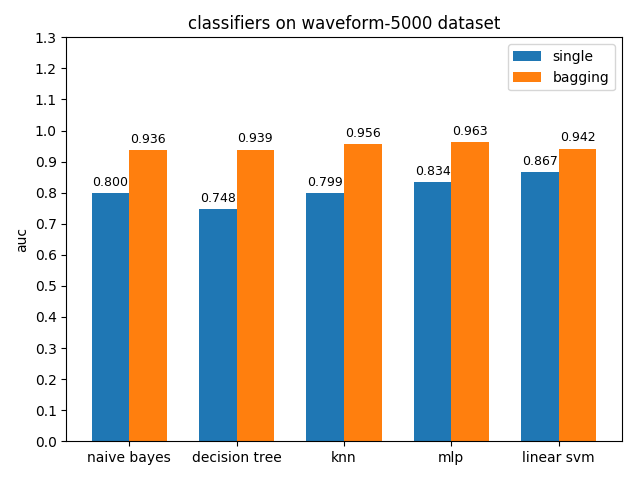
waveform-5000数据集上,各分类模型的准确率基本都是在80%左右,各分类模型的auc基本都有90%除了decision tree以外。waveform-5000是一个三类别的数据集,相比前面的2分类数据集预测难度也会更大,概率阈值的选择尤为关键,一个好的阈值划分会带来更高的准确率。
4.2 模型的bagging和single性能对比
4.2.1 breast-w dataset
准确率对比
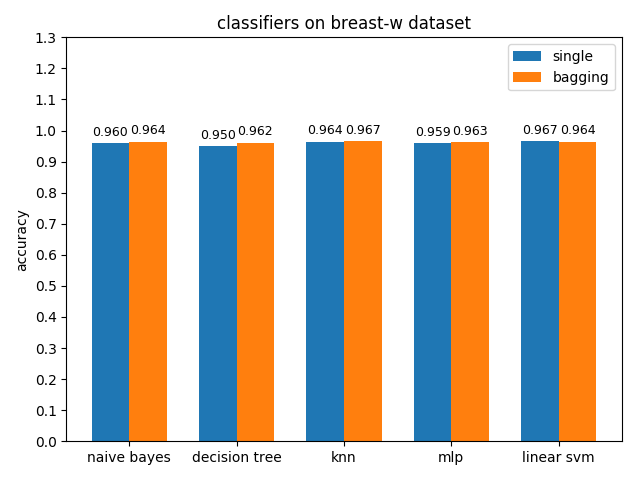
AUC对比
4.2.1 colic dataset
准确率对比
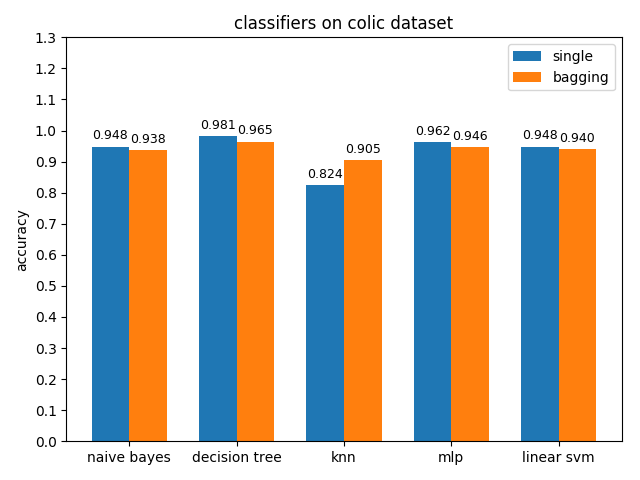
AUC对比
4.2.3 credit-a dataset
准确率对比
AUC对比
4.2.4 credit-g dataset
准确率对比
AUC对比
4.2.5 diabetes dataset
准确率对比
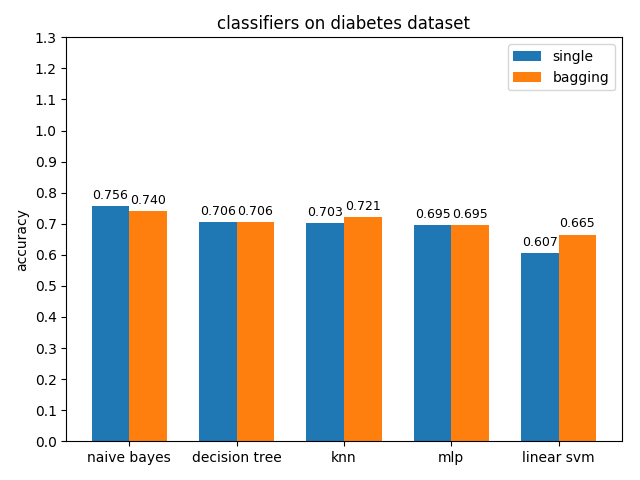
AUC对比
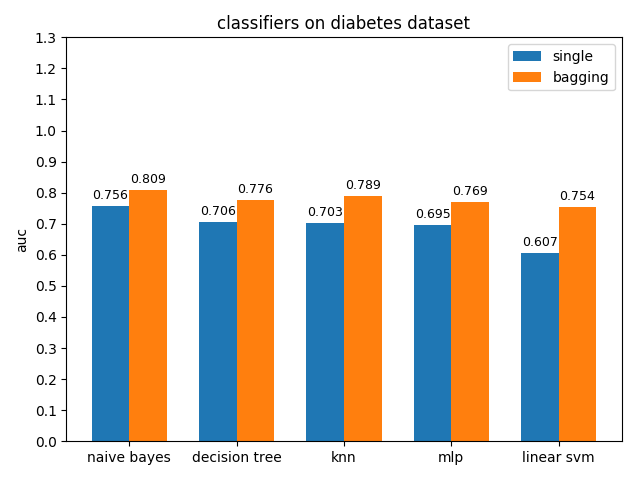
4.2.6 hepatitis dataset
准确率对比
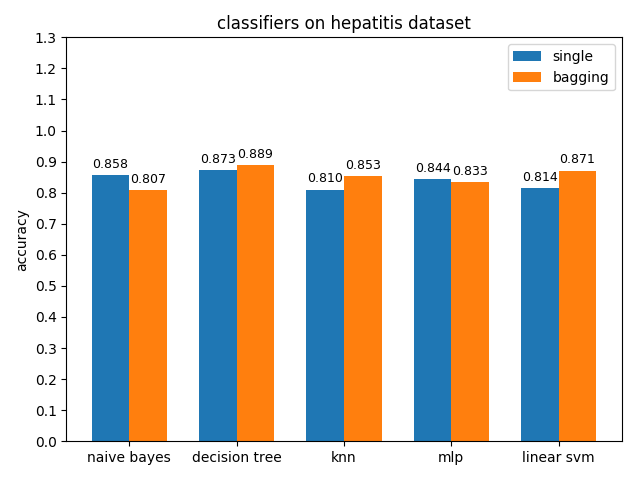
AUC对比
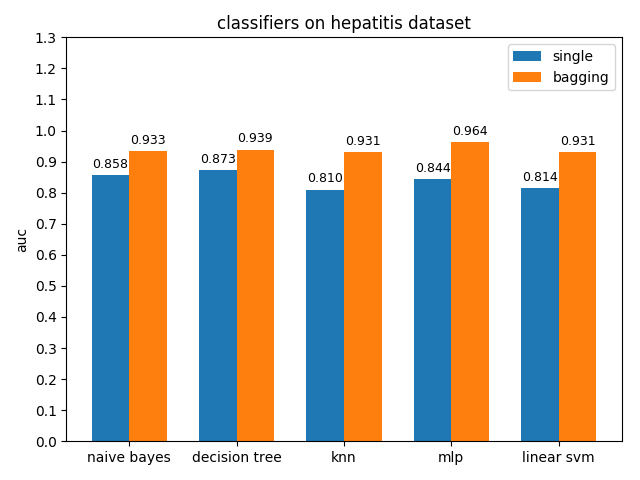
4.2.7 mozilla4 dataset
准确率对比
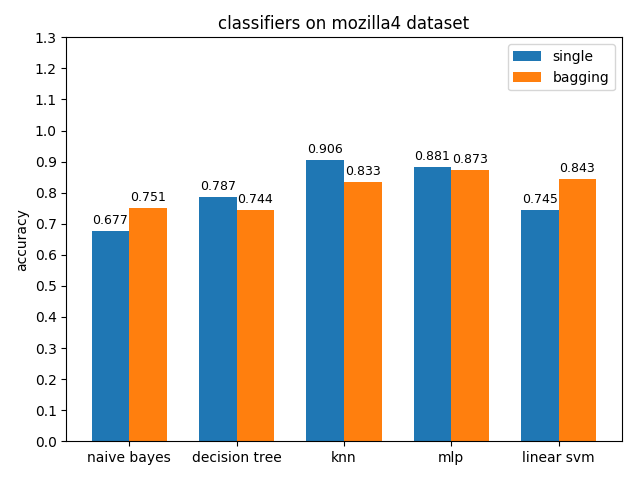
AUC对比
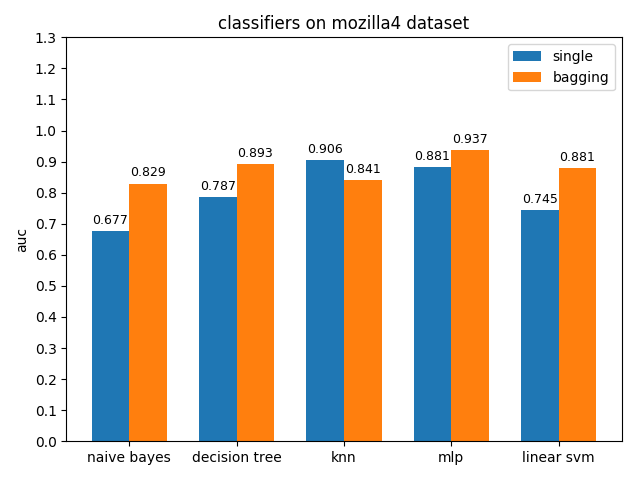
4.2.8 pc1 dataset
准确率对比
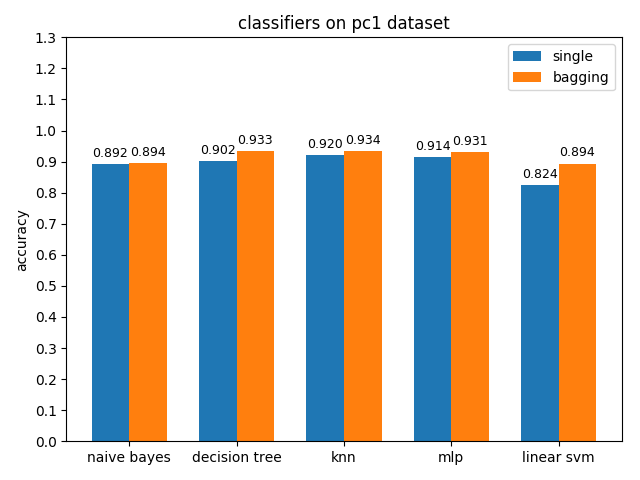
AUC对比
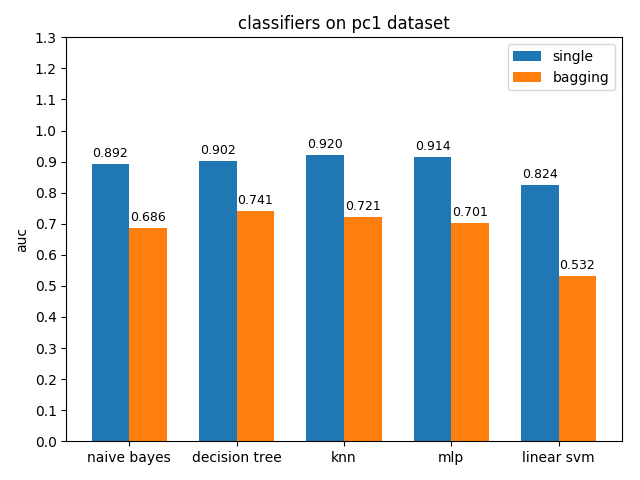
4.2.9 pc5 dataset
准确率对比
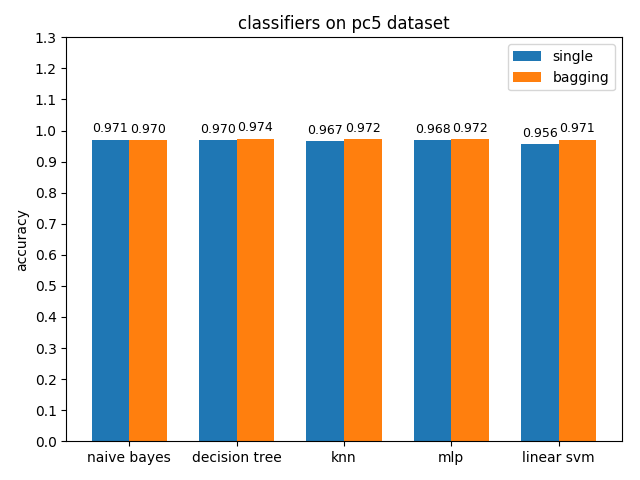
AUC对比
4.2.10 waveform-5000 dataset
准确率对比
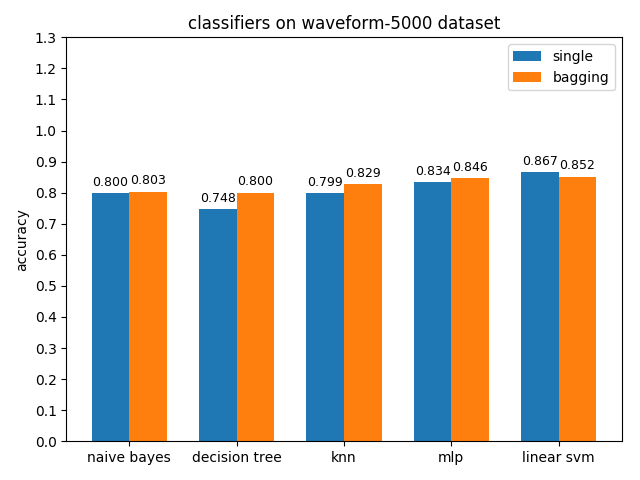
AUC对比
五、优化
5.1 降维
pc1,pc5,waveform-5000,colic,credit-g这几个数据集的属性维度都在20维及以上,而对分辨样本类别有关键作用的就只有几个属性,所以想到通过降维来摈除干扰属性以使分类模型更好得学习到数据的特征。用主成分分析(PCA)降维之后的数据分类效果不佳,考虑到都是带标签的数据,就尝试使用线性判别分析(LDA)利用数据类别信息来降维。但是LDA最多降维到类别数-1,对于二类数据集效果不好。waveform-5000包含三种类别,于是就尝试用LDA对waveform-5000降维之后再使用各分类模型对其进行学习。
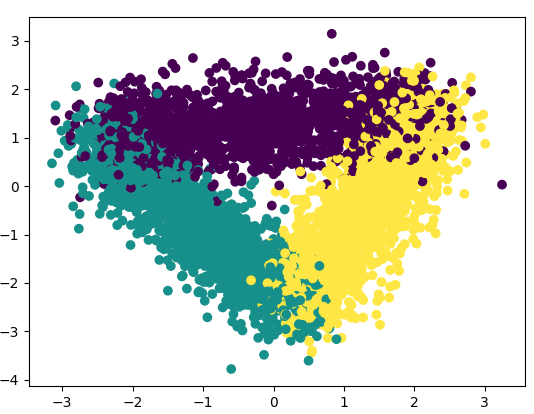
使用sklearn.discriminant_analysis.LinearDiscriminantAnalysis对waveform-5000降维之后的数据样本分布散点图如下,可以明显看到数据被聚为三类,降维之后的数据特征信息更为明显,干扰信息更少,对分类更有利
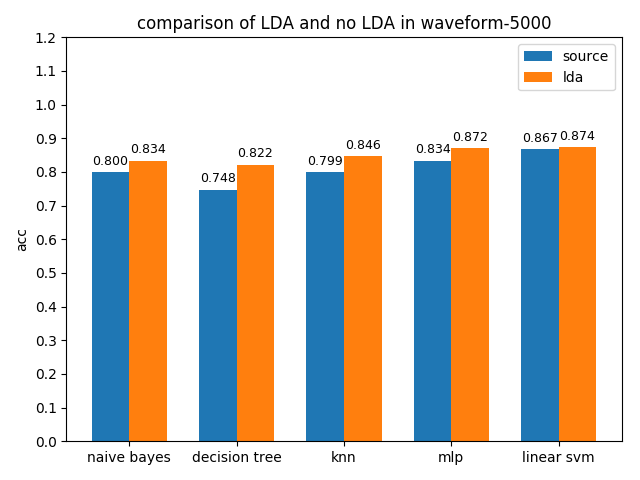
各分类模型在原数据集和LDA降维数据集上准确率对比如下图
各分类模型在原数据集和LDA降维数据集上AUC值对比如下图
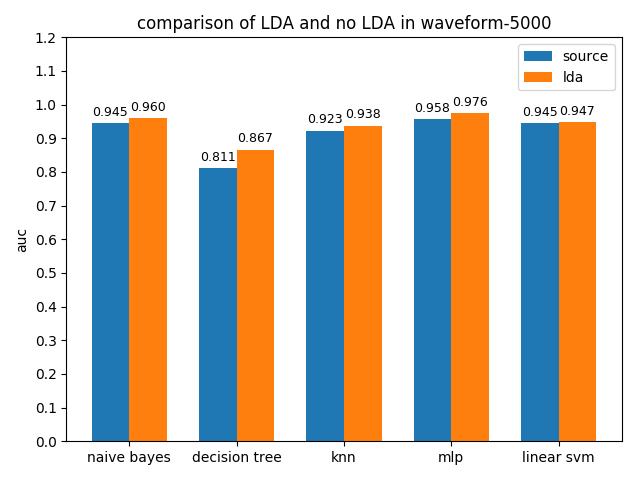
可以看到降维之后的分类效果很理想,无论是acc还是auc,各个分类模型都得到了不同程度的性能提升
5.2 标准化提升bagging with KNN性能
由于KNN是基于样本空间的欧氏距离来计算的,而多属性样本的各属性通常有不同的量纲和量纲单位,这无疑会给计算样本之间的真实距离带来干扰,影响KNN分类效果。为了消除各属性之间的量纲差异,需要进行数据标准化处理,计算属性的z分数来替换原属性值。在具体的程序设计时使用sklearn.preprocessing.StandardScaler来对数据进行标准化。
bagging with KNN在原数据集和标准化数据集上准确率对比如下图
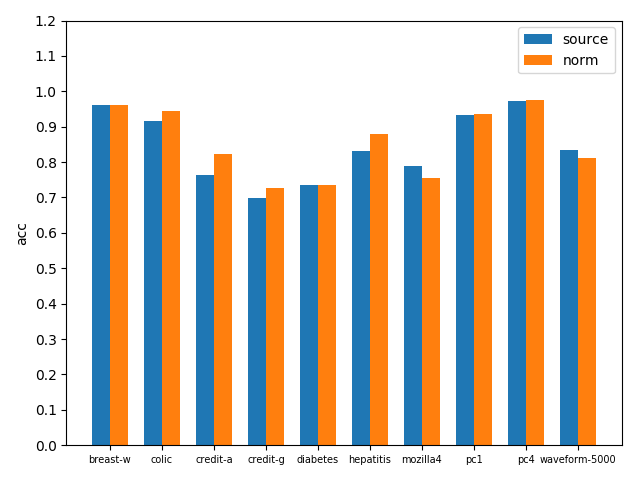
bagging with KNN在原数据集和标准化数据集上AUC对比如下图
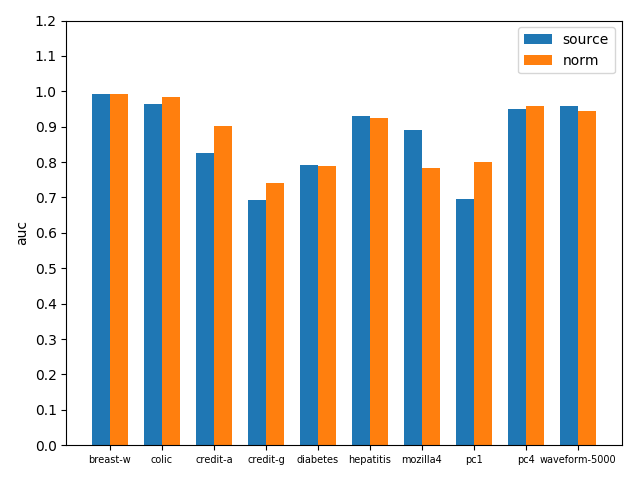
可以看到标准化之后效果还是不错的,无论是acc还是auc,基本在各数据集上都得到了性能提升
六、实验总结
此次实验让我对各个分类器的具体用法有了初步的了解,不同的数据集上应用不同分类模型的效果截然不同。数据挖掘任务70%时间消耗在数据清洗上,无论什么分类模型,其在高质量数据上的表现肯定是要优于其在低质量数据上的表现。所以拿到一个数据集后不能贸然往上面套分类模型,而是应该先对数据集进行观察分析,然后利用工具对数据进行清洗、约简、集成以及转换,提升数据质量,让分类更好得学习到数据的特征,从而有更好的分类效果。本次实验我也对各数据集进行了预处理,包括数据缺失值填补、数据类型转换、数据降维、数据标准化等等,这些工作都在各分类模型的分类效果上得到了一定的反馈。实验过程中也遇到了一些问题,比如使用sklearn.metrics.roc_auc_score计算多类别数据的AUC时需要提前将数据标签转换为one hot编码,LDA最多只能将数据维度降维到类别数-1等等,这些都为我以后进行数据挖掘工作积累了宝贵经验。
基于sklearn的分类器实战的更多相关文章
- adaboost 基于错误提升分类器
引自(机器学习实战) 简单概念 Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们需要简单介绍几个概念. 1:弱学习器:在二分情况下弱分类器的错误率会低于 ...
- 基于redis排行榜的实战总结
前言: 之前写过排行榜的设计和实现, 不同需求其背后的架构和设计模型也不一样. 平台差异, 有的立足于游戏平台, 为多个应用提供服务, 有的仅限于单个游戏.排名范围差异, 有的面向全局排名, 有的只做 ...
- 机器学习--PCA算法代码实现(基于Sklearn的PCA代码实现)
一.基于Sklearn的PCA代码实现 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets ...
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- 通俗地说逻辑回归【Logistic regression】算法(二)sklearn逻辑回归实战
前情提要: 通俗地说逻辑回归[Logistic regression]算法(一) 逻辑回归模型原理介绍 上一篇主要介绍了逻辑回归中,相对理论化的知识,这次主要是对上篇做一点点补充,以及介绍sklear ...
- sklearn 组合分类器
组合分类器: 组合分类器有4种方法: (1)通过处理训练数据集.如baging boosting (2)通过处理输入特征.如 Random forest (3)通过处理类标号.error_corre ...
- sklearn-woe/iv-乳腺癌分类器实战
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- 基于Python的机器学习实战:AadBoost
目录: 1. Boosting方法的简介 2. AdaBoost算法 3.基于单层决策树构建弱分类器 4.完整的AdaBoost的算法实现 5.总结 1. Boosting方法的简介 返回目录 Boo ...
- 基于Python的机器学习实战:KNN
1.KNN原理: 存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应 ...
随机推荐
- PHP 日常开发过程中的bug集合(持续更新中。。。)
PHP 日常开发过程中的bug集合(持续更新中...) 在日常php开发过程中,会遇到一些意想不到的bug,所以想着把这些bug记录下来,以免再犯! 1.字符串 '0.00'.'0.0'.'0' 是 ...
- Erasing and Winning UVA - 11491 贪心
题目:题目链接 思路:不难发现,要使整体尽量大,应先满足高位尽量大,按这个思路优先满足高位即可 AC代码: #include <iostream> #include <cstdio& ...
- python socket相关
套接字的工作流程(基于TCP和 UDP两个协议) TCP和UDP对比 TCP(Transmission Control Protocol)可靠的.面向连接的协议(eg:打电话).传输效率低全双工通信( ...
- 03009_HttpServletResponse
1.HttpServletResponse概述 (1)我们在创建Servlet时会覆盖service()方法,或doGet()/doPost(),这些方法都有两个参数,一个为代表请求的request和 ...
- HashMap的C++实现
#include <iostream> #include <cstring> #include <string> typedef unsigned int SIZE ...
- jQuery效果show()方法
$("button").click(function(){ $("p").show(); }); Syntax $(selector).show(speed,e ...
- Leetcode 459.重复的子字符串
重复的子字符串 给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成.给定的字符串只含有小写英文字母,并且长度不超过10000. 示例 1: 输入: "abab" 输出: ...
- Balanced Lineup(ST)
描述 For the daily milking, Farmer John's N cows (1 ≤ N ≤ 50,000) always line up in the same order. On ...
- “玲珑杯”线上赛 Round #17 河南专场
闲来无事呆在寝室打打题,没有想到还有中奖这种操作,超开心的 玲珑杯”线上赛 Round #17 河南专场 Start Time:2017-06-24 12:00:00 End Time:2017-06 ...
- Welcome-to-Swift-20扩展(Extensions)
扩展就是向一个已有的类.结构体或枚举类型添加新功能(functionality).这包括在没有权限获取原始源代码的情况下扩展类型的能力(即逆向建模).扩展和 Objective-C 中的分类(cate ...