10,Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
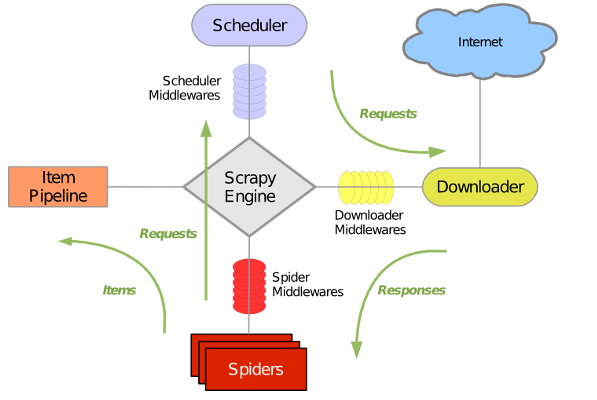
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
Linux:
pip3 install scrapy
Windows:
1、安装wheel
pip install wheel
、安装Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
pip install Twisted-18.9.0-cp36-cp36m-win_amd64.whl
、安装pywin32
https://sourceforge.net/projects/pywin32/files/
、安装scrapy
pip install scrapy
注:windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,https://sourceforge.net/projects/pywin32/
二、爬虫举例
入门篇:美剧天堂前100最新(http://www.meijutt.com/new100.html)
1、创建工程
scrapy startproject movie
2、创建爬虫程序
cd movie
scrapy genspider meiju meijutt.com
3、自动创建目录及文件
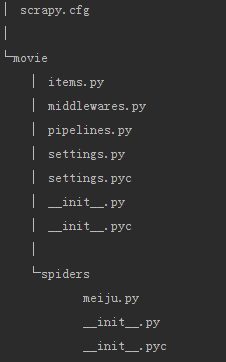
4、文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
items.py
import scrapy class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
6、编写爬虫
meiju.py
# -*- coding: utf-8 -*-
import scrapy
from movie.items import MovieItem class MeijuSpider(scrapy.Spider):
name = "meiju"
allowed_domains = ["meijutt.com"]
start_urls = ['http://www.meijutt.com/new100.html'] def parse(self, response):
movies = response.xpath('//ul[@class="top-list fn-clear"]/li')
for each_movie in movies:
item = MovieItem()
item['name'] = each_movie.xpath('./h5/a/@title').extract()[0]
yield item
7、设置配置文件
settings.py增加如下内容
ITEM_PIPELINES = {'movie.pipelines.MoviePipeline':100}
8、编写数据处理脚本
pipelines.py
class MoviePipeline(object):
def process_item(self, item, spider):
with open("my_meiju.txt",'a') as fp:
fp.write(item['name'].encode("utf8") + '\n')
9、执行爬虫
cd movie
scrapy crawl meiju --nolog
10、结果

进阶篇:爬取校花网(http://www.xiaohuar.com/list-1-1.html)
1、创建一个工程
scrapy startproject pic
2、创建爬虫程序
cd pic
scrapy genspider xh xiaohuar.com
3、自动创建目录及文件

4、文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
import scrapy class PicItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
addr = scrapy.Field()
name = scrapy.Field()
6、编写爬虫
# -*- coding: utf-8 -*-
import scrapy
import os
# 导入item中结构化数据模板
from pic.items import PicItem class XhSpider(scrapy.Spider):
# 爬虫名称,唯一
name = "xh"
# 允许访问的域
allowed_domains = ["xiaohuar.com"]
# 初始URL
start_urls = ['http://www.xiaohuar.com/list-1-1.html'] def parse(self, response):
# 获取所有图片的a标签
allPics = response.xpath('//div[@class="img"]/a')
for pic in allPics:
# 分别处理每个图片,取出名称及地址
item = PicItem()
name = pic.xpath('./img/@alt').extract()[0]
addr = pic.xpath('./img/@src').extract()[0]
addr = 'http://www.xiaohuar.com'+addr
item['name'] = name
item['addr'] = addr
# 返回爬取到的数据
yield item
7、设置配置文件
# 设置处理返回数据的类及执行优先级
ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100}
8、编写数据处理脚本
import urllib2
import os class PicPipeline(object):
def process_item(self, item, spider):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'}
req = urllib2.Request(url=item['addr'],headers=headers)
res = urllib2.urlopen(req)
file_name = os.path.join(r'D:\my\down_pic',item['name']+'.jpg')
with open(file_name,'wb') as fp:
fp.write(res.read())
9、执行爬虫
cd pic
scrapy crawl xh --nolog
结果:
终极篇:我想要所有校花图
注明:基于进阶篇再修改为终极篇
# xh.py
# -*- coding: utf-8 -*-
import scrapy
import os
from scrapy.http import Request # 导入item中结构化数据模板
from pic.items import PicItem class XhSpider(scrapy.Spider):
# 爬虫名称,唯一
name = "xh"
# 允许访问的域
allowed_domains = ["xiaohuar.com"]
# 初始URL
start_urls = ['http://www.xiaohuar.com/hua/']
# 设置一个空集合
url_set = set() def parse(self, response):
# 如果图片地址以http://www.xiaohuar.com/list-开头,我才取其名字及地址信息
if response.url.startswith("http://www.xiaohuar.com/list-"):
allPics = response.xpath('//div[@class="img"]/a')
for pic in allPics:
# 分别处理每个图片,取出名称及地址
item = PicItem()
name = pic.xpath('./img/@alt').extract()[0]
addr = pic.xpath('./img/@src').extract()[0]
addr = 'http://www.xiaohuar.com'+addr
item['name'] = name
item['addr'] = addr
# 返回爬取到的信息
yield item
# 获取所有的地址链接
urls = response.xpath("//a/@href").extract()
for url in urls:
# 如果地址以http://www.xiaohuar.com/list-开头且不在集合中,则获取其信息
if url.startswith("http://www.xiaohuar.com/list-"):
if url in XhSpider.url_set:
pass
else:
XhSpider.url_set.add(url)
# 回调函数默认为parse,也可以通过from scrapy.http import Request来指定回调函数
# from scrapy.http import Request
# Request(url,callback=self.parse)
yield self.make_requests_from_url(url)
else:
pass
10,Scrapy简单入门及实例讲解的更多相关文章
- [转]Scrapy简单入门及实例讲解
Scrapy简单入门及实例讲解 中文文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用 ...
- Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- Scrapy简单入门及实例讲解-转载
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 【智能算法】粒子群算法(Particle Swarm Optimization)超详细解析+入门代码实例讲解
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 01 算法起源 粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由E ...
- TCP入门与实例讲解
内容简介 TCP是TCP/IP协议栈的核心组成之一,对开发者来说,学习.掌握TCP非常重要. 本文主要内容包括:什么是TCP,为什么要学习TCP,TCP协议格式,通过实例讲解TCP的生命周期(建立连接 ...
- Nodejs进阶:核心模块net入门与实例讲解
模块概览 net模块是同样是nodejs的核心模块.在http模块概览里提到,http.Server继承了net.Server,此外,http客户端与http服务端的通信均依赖于socket(net. ...
- PHP中“简单工厂模式”实例讲解
原创文章,转载请注明出处:http://www.cnblogs.com/hongfei/archive/2012/07/07/2580776.html 简单工厂模式:①抽象基类:类中定义抽象一些方法, ...
- scrapy简单入门及选择器(xpath\css)
简介 scrapy被认为是比较简单的爬虫框架,资料比较齐全,网上也有很多教程.官网上介绍了它的四种安装方法,PyPI.Conda.APT.Source,我们只介绍最简单的安装方法. 安装 Window ...
- wxPython中文教程 简单入门加实例
wx.Window 是一个基类,许多构件从它继承.包括 wx.Frame 构件.技术上这意味着,我们可以在所有的 子类中使用 wx.Window 的方法.我们这里介绍它的几种方法: * SetTitl ...
随机推荐
- 用代码学习TreeView控件
private void Form1_Load(object sender,EventArgs e){ //游离对象 TreeNode tn=new TreeNode("我很好") ...
- Int与String之间相互转换
1 如何将字串 String 转换成整数 int? A. 有两个方法: 1). int i = Integer.parseInt([String]); 或 i = Integer.parseInt([ ...
- php 03
php03 一.判断类型 is_bool() 判断是否是布尔型 is_int(),is_integer() 和is_long() 判断是否是整型 is_float(),is_double()和i ...
- C#之razor
学习的文章在这里:http://www.cnblogs.com/yang_sy/archive/2013/08/26/ASPNET_MVC_RAZOR_ENGINE.html 1.视图开始文件_Vie ...
- LeetCode Length of Last Word 最后一个字的长度
class Solution { public: int lengthOfLastWord(const char *s) { ; string snew=s; ,len=strlen(s); ]; ) ...
- 网络编程——基于UDP的网络化CPU性能检测
网络化计算机性能检测软件的开发,可对指定目标主机的CPU利用率进行远程检测,并自动对远程主机执行性能指标进行周期性检测,最终实现图形化显示检测结果. 网络通信模块:(客户端类似,因为udp是对等通信) ...
- 基于PowerShell的Lync Server管理 使用C#
这里所说的Lync Server管理,指通过C#管理Lync账号的启用,禁用,开启账户的语音功能. Lync服务器安装后,会自动创建一个用于远程管理的应用程序,通过IIS查看,其应用程序名为: Lyn ...
- hihocoder 1080 线段树(区间更新)
题目链接:http://hihocoder.com/problemset/problem/1080 , 两种操作的线段树(区间更新). 这道题前一段时间一直卡着我,当时也是基础不扎实做不出来,今天又想 ...
- JS中的Global对象
Global对象可以说是ECMAScript中最特别的一个对象了.因为不管你从什么角度上看,这个对象都是不存在的.ECMAScript中的Global对象在某种意义上是作为一个终极的“兜底儿对象”来定 ...
- IOS 获取文本焦点 主动召唤出键盘(becomeFirstResponder) and 失去焦点(退下键盘)
主动召唤出键盘 - (void)viewDidAppear:(BOOL)animated { // 3.主动召唤出键盘 [self.nameField becomeFirstResponder]; / ...