zipline-benchmarks.py文件改写
改写原因:在这个模块中的 get_benchmark_returns() 方法回去谷歌财经下载对应SPY(类似于上证指数)的数据,但是Google上下载的数据在最后写入Io操作的时候会报一个恶心的编码的错误,很烦人,时好时坏的那种,就是图下这种报错。
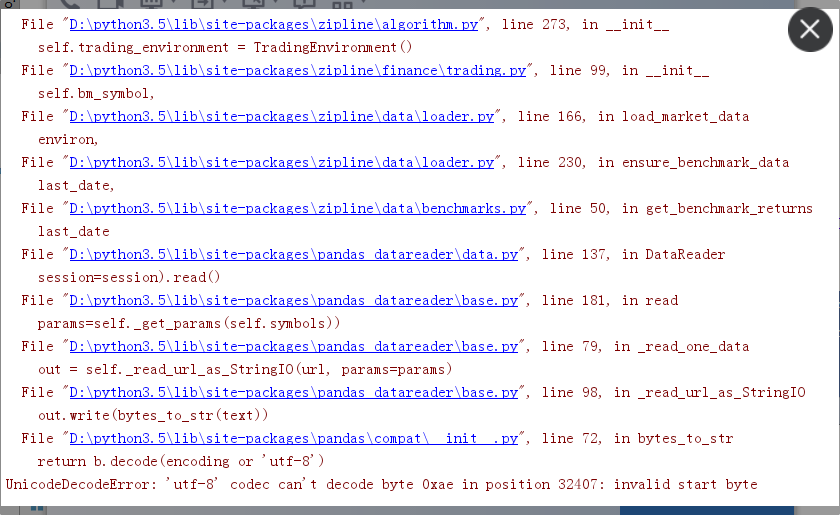
改写方式:
1.首先去雅虎财经下载SPY.csv文件,然后把这个文件放到你对应的目录下
2.具体代码如下
#
# Copyright 2013 Quantopian, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import pandas as pd
import pytz
from datetime import datetime import pandas_datareader.data as pd_reader def get_benchmark_returns(symbol, first_date, last_date):
"""
Get a Series of benchmark returns from Google associated with `symbol`.
Default is `SPY`. Parameters
----------
symbol : str
Benchmark symbol for which we're getting the returns.
first_date : pd.Timestamp
First date for which we want to get data.
last_date : pd.Timestamp
Last date for which we want to get data. The furthest date that Google goes back to is 1993-02-01. It has missing
data for 2008-12-15, 2009-08-11, and 2012-02-02, so we add data for the
dates for which Google is missing data. We're also limited to 4000 days worth of data per request. If we make a
request for data that extends past 4000 trading days, we'll still only
receive 4000 days of data. first_date is **not** included because we need the close from day N - 1 to
compute the returns for day N.
"""
# 源码
# data = pd_reader.DataReader(
# symbol,
# 'google',
# first_date,
# last_date
# )
#
# data = data['Close']
#
# data[pd.Timestamp('2008-12-15')] = np.nan
# data[pd.Timestamp('2009-08-11')] = np.nan
# data[pd.Timestamp('2012-02-02')] = np.nan
#
# data = data.fillna(method='ffill')
# return data.sort_index().tz_localize('UTC').pct_change(1).iloc[1:] # 自己写的代码
# parse = lambda x: pytz.utc.localize(datetime.strptime(x, '%Y-%m-%d'))
# data = pd.read_csv("SPY.csv", parse_dates=['Date'], index_col=0, date_parser=parse)
# data = data['Close']
# data = data.fillna(method='ffill')
# return data.sort_index().pct_change(1).iloc[0:]
总结:
1.这次报错后,我习惯性的找到最底层也就是最后两行错误,但是只能知道是编码的错误,但是解决不了。所以以后碰到类似的第三方包的错误,不要急着从最底层开始改,应该适当的想想,我在最开始出错的地方可不可以成功的避免掉,这也是一种思路。
2.Google财经的SPY数据不全,所以他在这个方法中定义了三列是因为这三天的数据他没有。
zipline-benchmarks.py文件改写的更多相关文章
- Python导入其他文件中的.py文件 即模块
import sys sys.path.append("路径") import .py文件
- 将做好的py文件打包成模块,供别人安装调用
现在要将写完的3个py文件,打包. 步骤: 1.新建一个文件夹setup(名字随便取),在setup文件夹下,再新建一个文件夹financeapi. 2.将上面4个py文件拷贝至financeapi文 ...
- RobotFramework中加载自定义python包中的library(一个py文件中有多个类)
结构如下: appsdk\ appsdk.py(这里面有多个类,包括appsdk,appsdksync等类) __init__.py ... ① 有个appsdk的文件夹(符合python包的定义) ...
- 【python】如何在某.py文件中调用其他.py内的函数
假设名为A.py的文件需要调用B.py文件内的C(x,y)函数 假如在同一目录下,则只需 import B if __name__ == "__main__": B.C(x,y) ...
- 向IPython Notebook中导入.py文件
IPython Notebook使用起来简洁方便,但是有时候如果需要导入一个现有的.py文件,则需要注意选择导入的方法以达到不同的效果.目前遇到3种方法. (1) 将文件保存为.ipynb格式,直接拖 ...
- Python实现插件机制——自动import一个目录下的所有.py文件
假设有这样一个目录结构: /src main.py /plugins __init__.py a.py ...
- 如何使用setup.py文件
setup.py文件的使用:% python setup.py build #编译% python setup.py install #安装% python setup.py sdist ...
- 新建childTest文件夹,里面依然放进我们需要的.py文件即可
一.模块 我们编写文件:a.py,放在C:\Python34\Lib\sit-packages下,里面写上一句代码为: print('this is a') 之后我们就可以在我们的代码里面引用a.py ...
- 【linux】终端直接执行py文件,不需要python命令
先将终端所在路径切换到python脚本文件的目录下然后给脚本文件运行权限,一般755就OK,如果完全是自己的私人电脑,也不做服务器什么的,给777的权限问题也不大(具体权限含义参考chmod指令的介绍 ...
随机推荐
- Java中调用文件中所有bat脚本
//调用外部脚本String fileips=null;//所有的路径String[] files=null;String fileip=null;//单个路径try { InputStream is ...
- JVM学习一:JVM之类加载器概况
18年转眼就3月份都快结束了,也就是说一个季度就结束了:而我也因为年前笔记本坏了,今天刚修好了,那么也应该继续学习和博客之旅了.今年的博客之旅,从JVM开始学起,下面我们就言归正传,进入正题. 一.J ...
- 【原创】Linux服务器集群通过SSH无密码登录
SSH 无密码授权访问slave集群机器 1. 安装SSH,所有集群机器,都要安装SSH环境介绍: Master : CNT06BIG01 192.168.3.61 SLAVE 1: CNT06BI ...
- 笔记:Spring Boot 项目构建与解析
构建 Maven 项目 通过官方的 Spring Initializr 工具来产生基础项目,访问 http://start.spring.io/ ,如下图所示,该页面提供了以Maven构建Spring ...
- 用js编解码base64
以下是编码和解码的方法 function Base64() { // private property _keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdef ...
- Docker 网络管理及容器跨主机通信
1.网络模式 docker支持四种网络模式,使用--net选项指定: host,--net=host,如果指定此模式,容器将不会获得一个独立的network namespace,而是和宿主机共用一个. ...
- 【数据库】MySQL中的共享锁与排他锁
转载:http://www.hollischuang.com/archives/923 在MySQL中的行级锁,表级锁,页级锁中介绍过,行级锁是Mysql中锁定粒度最细的一种锁,行级锁能大大减少数据库 ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- Ajax教程(转载)
第 1 页 Ajax 简介Ajax 由 HTML.JavaScript™ 技术.DHTML 和 DOM 组成,这一杰出的方法可以将笨拙的 Web 界面转化成交互性的 Ajax 应用程序.本文的作者是一 ...
- Vim配置及使用技巧
要说Linux下比较好用的文本编辑器,我推荐vim(当然很多人都用emacs,可我没用过),用vim也有一年左右,有些心得体会想与诸位分享.在我的学习过程中,借鉴了不少优秀的博客,其中有csdn大神n ...