Day4 《机器学习》第四章学习笔记
决策树
前几天学习了《机器学习》的前三章,前三章介绍机器学习的基础知识,接下来,第四章到第十章介绍一些经典而常用的机器学习方法,这部分算是具体的应用篇,第四章介绍了一类机器学习方法——决策树。
3.1 基本流程
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类嘛?”这个问题的“决策”或“判定”过程。顾名思义,决策树,就是基于树结构来进行决策的。例如我们对一个好西瓜的判定过程,如下图:
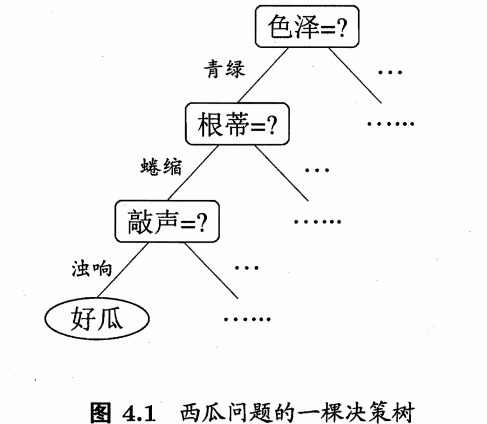
显然,决策的最终结论是我们的判断结果:“是”或者“不是”好瓜。一般的,1、一颗决策树包含一个根结点、若干个内部结点和若干个叶结点;2、叶结点对应决策结果,其他每个结点则对应一个属性测试;3、每个结点包含的样本集合根据属性测试的结果被划分到子结点中;4、根结点包含样本全集。 从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习,目的是产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之(divide-and-conquer)”策略,算法如下:

显然,决策树的生成是一个递归过程。决策树算法中,有三种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,无需划分;(2)当前属性集为空,或者所有样本在所有属性上取值相同,无法划分;(3)当前结点包含样本集合为空,不能划分。(在第(2)中情形下,把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;在第(3)中情形下,同样把当前结点标记为叶结点,但将其类别设定为父结点所含样本最多的类别。这两种情形处理的实质是不同的,(2)是在利用当前结点的后验分布,而(3)则把父结点的样本分布作为当前结点的先验分布。)
4.2 划分选择
有算法流程看出,决策树学习关键在第8行,即如何选择最优划分属性,一般而言,随着划分过程进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度(purity)”越来越高。
4.2.1 信息增益
“信息熵(information entropy)”是度量样本集合纯度最常用的一种指标。我们假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为:
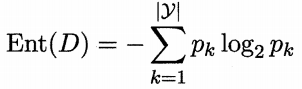
Ent(D)的值越小,D的纯度越高(理想情况就是Ent(D)的值小到0,相当于pk=1,这样的话D中样本就全属于同一类)
假定离散属性a有V个可能的取值{a1, a2, …, aV},若使用a来样本集D进行划分,则产生V个分支结点,其中v个分支结点包含D中所有在属性a上取值为aV的样本。根据信息熵定义式计算出Dv的信息熵,在考虑到不同的分支结点的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所取得的“信息增益(information gain)”:
所以,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大,因此,我们可用信息增益来进行决策树的划分属性选择,即在算法流程4.2图中第8行选择属性 。著名的ID3(Iterative Dichotomiser迭代二分器)决策树学习算法[Quinlan, 1986]就是以信息增益为准则来选择划分属性的。
。著名的ID3(Iterative Dichotomiser迭代二分器)决策树学习算法[Quinlan, 1986]就是以信息增益为准则来选择划分属性的。
以表4.1中的西瓜数据集2.0为例:

该数据集包含17个训练样例,用以学习一棵能够预测没剥开的是不是好瓜的决策树。显然,|y| = 2。在决策树学习开始时,根结点包含D中的所有样例,其中正例占p1 = 8/17 ,反例占p2 = 9/17。于是,根据信息熵定义式计算出根结点的信息熵为:
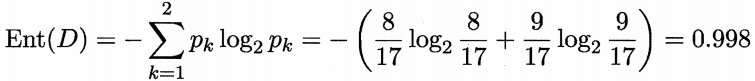
然后我们计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。以属性“色泽”为例,他有三个可能的取值:{青绿,乌黑,浅白}。若使用该属性对D进行划分,这可以划分为三个子集,分别记为:D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。子集D1包含编号{1,4,6,10,13,17}的样例,其中正例占p1 = 3/6 ,反例占p2 = 3/6,同理写出D2、D3的样例编号,计算出对应正例,反例比例,就可以根据信息熵定义式算出用“色泽”划分之后所得到的3个分支结点的信息熵:

根据信息增益计算式算出各属性信息增益:
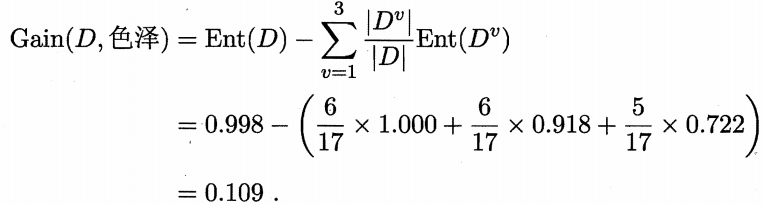
类似的我们可以计算出其他属性的信息增益:

显然,属性“纹理”的信息熵最大,于是它被选为划分属性。基于“纹理”对根结点进行划分,进而继续算出其他各属性信息增益:

可看出,“根蒂”、“脐部”、“触感”3个属性均取得了最大的信息增益,可任意选其中一个最为下一步划分属性,类似的,对每个分子结点进行上述操作,最终得到决策树如图4.4所示: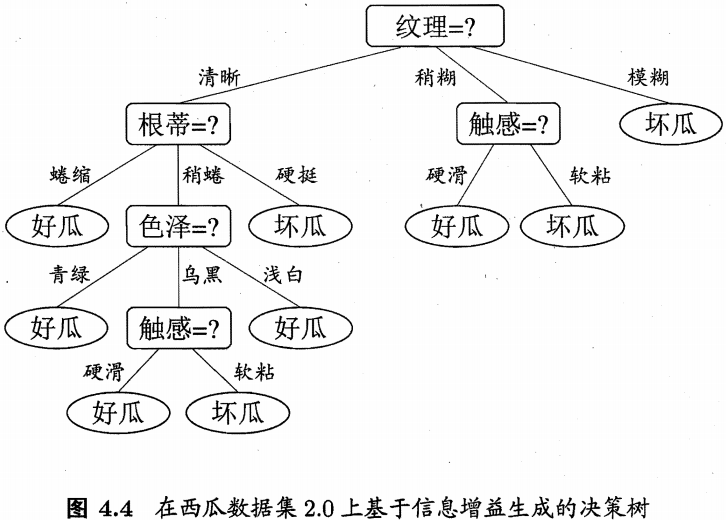
4.2.2 增益率
在上面的划分中吗,我们没有将“编号”这一栏作为划分属性,如果以编号作为属性划分样本,将产生17个分支,每个分支结点仅含一个样本,分支结点的纯度最大。然而,这样决策树显然不具有泛化能力,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法[Quinlan, 1993]不直接使用信息增益,而是使用“增益率(gain ratio)”来选择最优划分属性,增益率定义为:
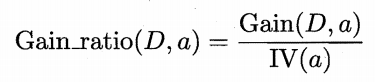
其中
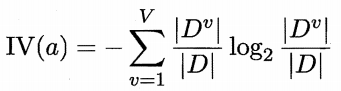
称为属性a的“固有值(intrinsic value)”[Quinlan, 1993].属性a的可能取值数目越多(即V越大),则IV(a)的值越大。
需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式[Quinlan, 1993]:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
4.2.3 基尼指数
CART(Classification and Rgression Tree)决策树[Breiman et al. , 1984]使用“基尼指数(Gini index)”来选择划分属性,与4.1采用相同的符号,数据集D的纯度可用基尼值来度量: Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集D的纯度越高。属性a的基尼指数定义为:
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,则数据集D的纯度越高。属性a的基尼指数定义为:
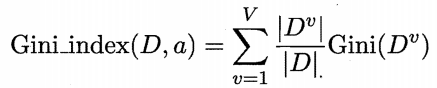
于是,我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即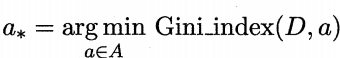
4.3 剪枝处理
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因为训练样本学得“太好了”,以至于把训练样本集自身的一些特点当作所有数据都具有的一般性质而导致过拟合,因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有“预剪枝(prepruning)”和“后剪枝(post-pruning)”[Quinlan, 1993]
4.3.1 预剪枝
4.3.2 后剪枝
4.4 连续与缺失值
4.4.1 连续值处理
4.4.2 缺失值处理
4.5 多变量决策树
(未完待续)
Day4 《机器学习》第四章学习笔记的更多相关文章
- 《Linux内核设计与实现》第四章学习笔记
<Linux内核设计与实现>第四章学习笔记 ——进程调度 姓名:王玮怡 学号:20135116 一.多任务 1.多任务操作系统的含义 多任务操作系统就是能同时并发地交 ...
- 《Linux内核设计与实现》第四章学习笔记——进程调度
<Linux内核设计与实现>第四章学习笔记——进程调 ...
- Spring实战第四章学习笔记————面向切面的Spring
Spring实战第四章学习笔记----面向切面的Spring 什么是面向切面的编程 我们把影响应用多处的功能描述为横切关注点.比如安全就是一个横切关注点,应用中许多方法都会涉及安全规则.而切面可以帮我 ...
- 《Linux命令行与shell脚本编程大全》 第十四章 学习笔记
第十四章:呈现数据 理解输入与输出 标准文件描述符 文件描述符 缩写 描述 0 STDIN 标准输入 1 STDOUT 标准输出 2 STDERR 标准错误 1.STDIN 代表标准输入.对于终端界面 ...
- Day2 《机器学习》第二章学习笔记
这一章应该算是比价了理论的一章,我有些概率论基础,不过起初有些地方还是没看多大懂.其中有些公式的定义和模型误差的推导应该还是很眼熟的,就是之前在概率论课上提过的,不过有些模糊了,当时课上学得比较浅. ...
- Day1 《机器学习》第一章学习笔记
<机器学习>这本书算是很好的一本了解机器学习知识的一本入门书籍吧,是南京大学周志华老师所著的鸿篇大作,很早就听闻周老师大名了,算是国内机器学习领域少数的大牛了吧,刚好研究生做这个方向相关的 ...
- Mudo C++网络库第四章学习笔记
C++多线程系统编程精要 学习多线程编程面临的最大思维方式的转变有两点: 当前线程可能被切换出去, 或者说被抢占(preempt)了; 多线程程序中事件的发生顺序不再有全局统一的先后关系; 当线程被切 ...
- Scala第四章学习笔记(面向对象编程)
延迟构造 DelayedInit特质是为编译器提供的标记性的特质.整个构造器被包装成一个函数并传递给delayedInit方法. trait DelayedInit { def deayedInit( ...
- 4类Storage方案(AS开发实战第四章学习笔记)
4.1 共享参数SharedPreferences SharedPreferences按照key-value对的方式把数据保存在配置文件中,该配置文件符合XML规范,文件路径是/data/data/应 ...
随机推荐
- Android中使用SVG矢量图(一)
SVG矢量图介绍 首先要解释下什么是矢量图像,什么是位图图像? 1.矢量图像:SVG (Scalable Vector Graphics, 可伸缩矢量图形) 是W3C 推出的一种开放标准的文本式矢量图 ...
- 解决javac和java命令在Mac OSX终端里的乱码问题
转自:https://www.surfchen.org/archives/710 java和javac在简体中文的Mac OSX的终端(Terminal.app)环境下,默认是以GBK编码的中文输出各 ...
- saiku应用的调试
ubuntu下解压saiku包后使用: 运行.sh命令(.bat是windows命令).运行时注意权限.可以先chmod a+x *.sh 提示,catali?.sh出错. 这是tomcat的一个文件 ...
- Android群英传笔记——摘要,概述,新的出发点,温故而知新,可以为师矣!
Android群英传笔记--摘要,概述,新的出发点,温故而知新,可以为师矣! 当工作的越久,就越感到力不从心了,基础和理解才是最重要的,所以买了两本书,医生的<Android群英传>和主席 ...
- 销售行业ERP数据统计分析都有哪些维度?
场景描述 当前的企业信息化建设主要包括ERP系统.OA系统等.企业希望实现信息系统数据的整合,对企业资源进行分析汇总,方便对企业相关数据的掌控从而便于对业务流程进行及时调整监控. 但是由于系统间数据的 ...
- 如何设置静态IP
首先在CMD命令行ipconfig查看临时分配的IP地址: 然后打开我的"网络"--->"本地连接"--->IPv4--->属性 电信DNS劫 ...
- coco2dx添加类报错
最近刚开始学习2dx,用的vs编辑器,现在说说我使用时碰到的一点小问题: 我使用的类添加向导,但是添加的类在win32目录下,而且编译的时候总是提示找不到 .h 文件 其实,这样添加类不是很好,可以在 ...
- java中split(regex)使用中要注意的问题:正则表达式
比如我在项目中遇到的(,),.,|,*等等类的符号: String area="(30.13206313822174, 120.4156494140625)(29.8763738070713 ...
- Qt与FFmpeg联合开发指南(三)——编码(1):代码流程演示
前两讲演示了基本的解码流程和简单功能封装,今天我们开始学习编码.编码就是封装音视频流的过程,在整个编码教程中,我会首先在一个函数中演示完成的编码流程,再解释其中存在的问题.下一讲我们会将编码功能进行封 ...
- C++内存分区
C++的内存划分为栈区.堆区.全局区/静态区.字符串常量和代码区. 这里去掉自由存储区,增加了代码区,理由会在下面讲到. 栈区:由系统进行内存的管理. 说明:主要存放函数的参数以及局部变量.栈区由系统 ...