一、scrapy的下载安装---Windows(安装软件太让我伤心了)
写博客就和笔记一样真的很有用,你可以随时的翻阅。爬虫的爬虫原理与数据抓取、非结构化与结构化数据提取、动态HTML处理和简单的图像识别已经学完,就差整理博客了
开始学习scrapy了,所以重新建了个分类。
scrapy的下载到安装,再到能够成功运行就耗费了我三个小时的时间,为了防止以后忘记,记录一下。
我用的是Python3.6. Windows 需要四步
1、pip3 install wheel
2、安装Twisted
a. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted, 下载:Twisted-17.9.0-cp36-cp36m-win_amd64.whl
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3、pip3 install scrapy
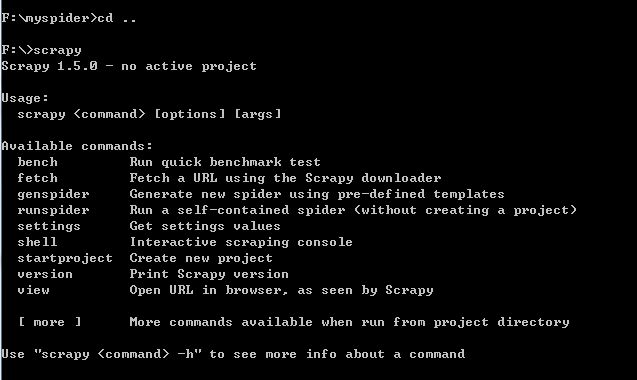
然后我打开cmd,输入了scrapy, 出现:
scrapy startproject myspider -----------创建scrapy项目
cd myspider -----------进入myspider目录
scrapy genspider baidu baidu.com ------------创建爬虫文件
scrapy crawl baidu -------------运行文件
之后,就报错了,说缺少一个模块win32, 上网查说 windows上scrapy依赖pywin32,下载网址: https://sourceforge.net/projects/pywin32/files/
我下载了,在安装的时候出现了:
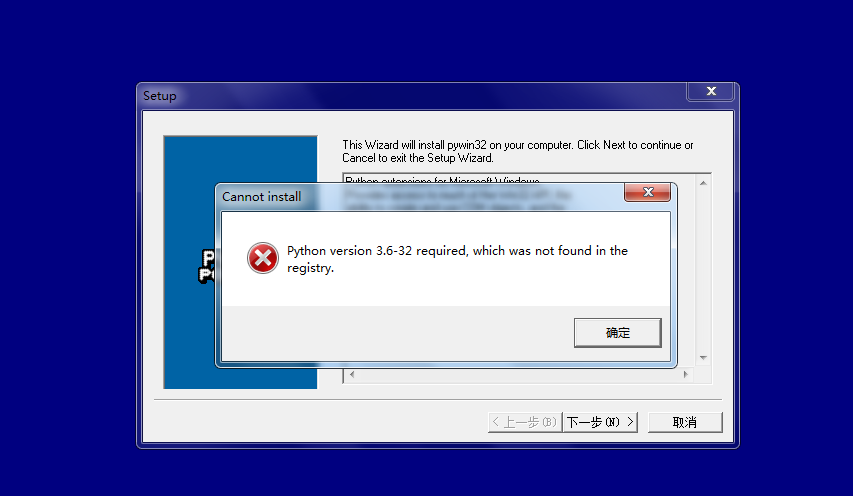
上面说是没注册什么的,上网搜了一下解决方案,唉,自己没看懂。痛心疾首,对我自己的智商感到捉急
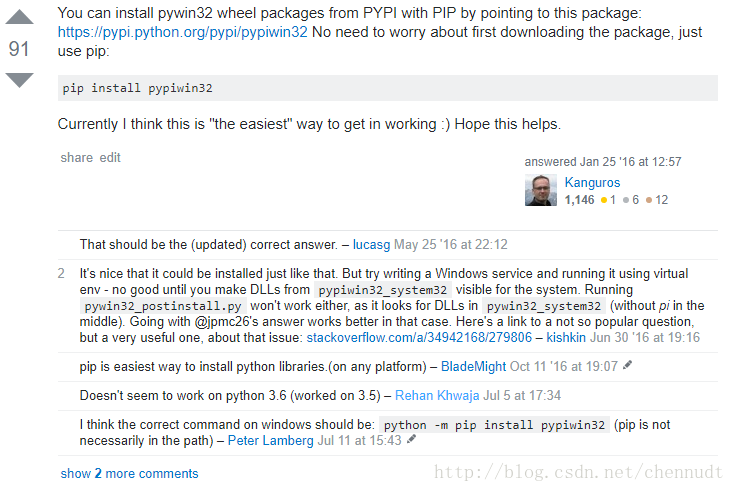
4、在cmd中使用python -m pip install pypiwin32
这是我成功的方法,上网查之后,在https://stackoverflow.com/questions/4863056/how-to-install-pywin32-module-in-windows-7有这样一段话:
每天一个小实例:爬视频(其实找到了视频的url链接,用urllib.request.urlretrieve(视频url,存储的路径)就可以了。
我做的这个例子太简单;用scrapy框架显得复杂,,我只是下载了一页,多页的话循环url,主要是走一遍使用Scrapy的流程:
#第一
打开mySpider目录下的items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy '''Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。'''
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
mp4_url = scrapy.Field() #第二,打开你创建的爬虫文件,我的是baisi.py # -*- coding: utf-8 -*-
import scrapy
from myspider.items import MyspiderItem class BaisiSpider(scrapy.Spider):
name = 'baisi'
allowed_domains = ['http://www.budejie.com']
start_urls = ['http://www.budejie.com/video/'] def parse(self, response):
# 将我们得到的数据封装到一个 `MyspiderItem` 对象
item = MyspiderItem() #提取数据
mp4_links = response.xpath('//li[@class="j-r-list-tool-l-down f-tar j-down-video j-down-hide ipad-hide"]')
for mp4_link in mp4_links:
name = mp4_link.xpath('./@data-text')[0].extract()
video = mp4_link.xpath('./a/@href')[0].extract()
#判断是否有MP4——url链接,有的保存
if video:
item['name'] = name
item['mp4_url'] = video
# 将获取的数据交给pipelines
yield item #第三 打开pipelines.py文件 # -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import urllib.request
import os
class MyspiderPipeline(object):
def process_item(self, item, spider):
#文件名
file_name = "%s.mp4" % item['name']
#文件保存路径
file_path = os.path.join("F:\\myspider\\myspider\\video", file_name)
urllib.request.urlretrieve(item['mp4_url'],file_path)
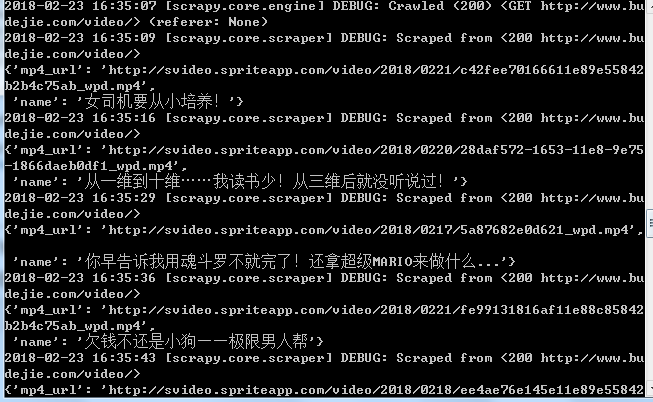
return item 第四,执行scrapy crawl baisi
执行结果:
Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。 Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy架构图(绿线是数据流向):
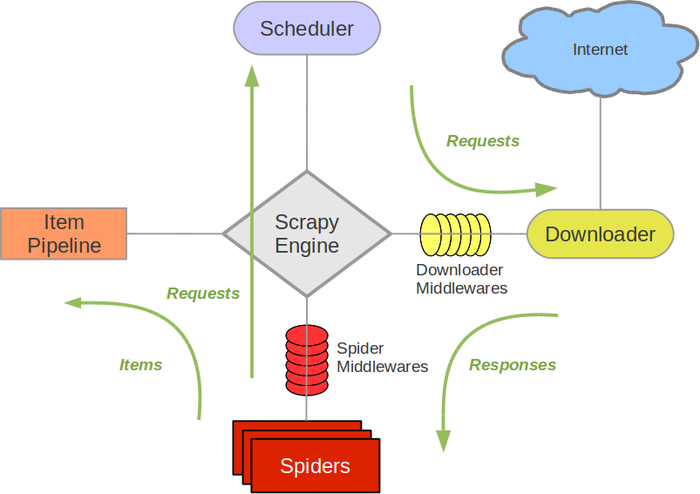
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
scrapy运行的流程大概是:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取。
- 引擎把URL封装成一个请求(request)传给下载器。
- 下载器把资源下载下来,并封装成应答包(response)
- 爬虫解析response
- 解析出实体(item),则交给实体管道进行进一步处理
- 解析出的是衔接(URL),则把URL交给调度器等待抓取
基本使用:
1.在命令行中输入: scrapy startproject myspider -----------创建scrapy项目
自动创建目录:

打开:myspider
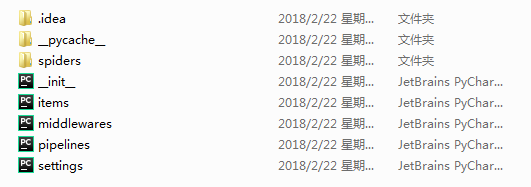
文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
2.
cd myspider -----------进入myspider目录
scrapy genspider baidu baidu.com ------------创建爬虫文件
注意:一般创建爬虫文件时,以网站域名命名,文件会在spiders中,
3. 然后你就可以编写代码了
4. scrapy crawl baidu -------------运行文件
总的来说:
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
一、scrapy的下载安装---Windows(安装软件太让我伤心了)的更多相关文章
- MySQL安装-windows安装
windows下安装MySQL 在windows下面安装MySQL 本文以5.7.17为示例 MySQL下载 官网:https://dev.mysql.com/downloads/mysql/ 本次安 ...
- 无法访问windows安装服务。发生这种情况的可能是您在安全模式下运行windows,或是没有正确安装windows安装,。请与技术支持人员联系以获得帮助。
解决办法: 1.命令提示符下输入:msiexec/regserver 2.在“管理工具”→“服务”中启动windows Installer 程序员的基础教程:菜鸟程序员
- windows安装Anaconda3
目录 windows安装Anaconda3 环境 安装 windows安装Anaconda3 by 铁乐与猫 环境 windows7 64位 Anaconda3 5.2.0版本 windows64位 ...
- Windows安装使用git
下载安装Windows安装文档Git-2.16.2-64-bit双击安装(安装过程不详述) 打开git客户端 新建代码命令 mkdir /c/code 进入该目录(对应windows的c盘下面的目录) ...
- Windows安装Jenkins详细教程(图文教程)
一.安装前准备 1.提前安装好jdk,可参考以下链接进行安装 Windows安装JDK详细教程(图文教程) 2.Jenkins官网下载安装包(因为本人jdk安装的是1.8,所以会和最新版jenkins ...
- 品牌电脑硬盘损坏后,使用MediaCreationTool从微软官方下载正版Windows到USB做安装盘
最近我的一台台式机电脑的硬盘损坏了.一开始是速度逐渐变慢,后来慢得难以忍受,有时半天无响应.查看 Windows event ,发现有 id 为 7 的磁盘报错.使用 Windows 8.1 家庭版自 ...
- CrossOver for Mac v18.5 中文破解版下载-可以安装Windows软件
CrossOver for Mac v18.5 中文破解版: http://h5ip.cn/kADD Crossover Mac 破解版是Mac 和 Windows 系统之间的兼容工具.使 Mac 操 ...
- scrapy系列(一)——Python 爬虫框架 Scrapy1.2 Windows 安装教程
scrapy作为一个成熟的爬虫框架,网上有大量的相关教程供大家选择,尤其是关于其的安装步骤更是丰富的很.在这里我想记录下自己的相关经验,希望能给大家带来点帮助. 在scrapy0.24版之前,安装sc ...
- 06 windows安装Python+Pycharm+Scrapy环境
windows安装Python+Pycharm+Scrapy环境 使用微信扫码关注微信公众号,并回复:"Python工具包",免费获取下载链接! 一.卸载python环境 卸载以下 ...
随机推荐
- PHP中的GetType和SetType
大部分的可变函数都是用来测试一个函数的类型的.PHP中有两个最常见的函数,分别是gettype()和settype().这两个函数具有如下所示的函数原型,通过他们可以获得要传递的参数和返回的结果. s ...
- vue ajax获取数据的时候,如何保证传递参数的安全或者说如何保护api的安全
https://segmentfault.com/q/1010000005618139 vue ajax获取数据的时候,如何保证传递参数的安全或者说如何保护api的安全 点击提交,发送请求.但是api ...
- java中的左右移
package scanner; public class LeftMove { public static void main(String[] args) { int i = 1; System. ...
- myeclipse编码
window --->perferences
- Angular19 自定义表单控件
1 需求 当开发者需要一个特定的表单控件时就需要自己开发一个和默认提供的表单控件用法相似的控件来作为表单控件:自定义的表单控件必须考虑模型和视图之间的数据怎么进行交互 2 官方文档 -> 点击前 ...
- Django_中国化
需求: 要求Django显示中文,并使用北京时间 问题原因: Django具有相当的国际化,已经内置了多种语言,汉语当然也不落下,Django默认的时间是utc时间,也就是说相隔八个时区的中国,显示北 ...
- python_如何读写csv数据
案例: 通过股票网站,我们获取了中国股市数据集,它以csv数据格式存储 Data,Open,High,Low,Close,Volume,Adj Close 2016-06-28,8.63,8.47,8 ...
- java8大基本数据类型
基本类型 字节数 位数 最大值 最小值 byte 1byte 8bit 2^7 - 1 -2^7 short 2byte 16bit 2^15 - 1 -2^15 int 4byte 32bit 2^ ...
- Composer - windows下安装方法
在windows下安装的方法 方法一:使用安装程序 这是将 Composer 安装在你机器上的最简单的方法. 下载并且运行 Composer-Setup.exe,它将安装最新版本的 Composer ...
- Nagios状态长时间处于Pending的解决方法
1 nagios 守护进程引起的一系列问题 1 影响nagios web页面收集监控信息 致使页面出现时而收集不到服务信息 2 影响pnp查看图形化,出图缓慢 3 影响查看服务状态信息,致使有时候查看 ...