卷积神经网络的一些经典网络(Lenet,AlexNet,VGG16,ResNet)
LeNet – 5网络
网络结构为:
输入图像是:32x32x1的灰度图像
卷积核:5x5,stride=1
得到Conv1:28x28x6
池化层:2x2,stride=2
(池化之后再经过激活函数sigmoid)
得到Pool1:14x14x6
卷积核:5x5,stride=1
得到Conv2:10x10x16
池化层Pool2:2x2,stride=2
(池化之后再经过激活函数sigmoid)
得到Pool2:5x5x16
然后将Pool2展开,得到长度为400的向量
经过第一个全连接层,得到FC1,长度120
经过第二个全连接层,得到FC2,长度84
最后送入softmax回归,得到每个类的对应的概率值。
网络结构图如下:

LeNet大约有6万个参数
可以看出,随着网络的加深,图像的宽度和高度在缩小,与此同时,图像的通道却在不断的变大。
注:LeNet论文中的一些细节与现在的网络处理方式有些不同。阅读原始论文时,建议精读Section2,泛读Section3。不同点有以下几点:
1)论文中使用Sigmoid函数作为激活函数,而现在我们一般使用ReLU等作为激活函数;
2)现在我们使用的每个卷积核的通道数都与其上一层的通道数相同,但是LeNet受限于当时的计算机的运算速度,为了减少计算量和参数,LeNet使用了比较复杂的计算方式;
3)LeNet网络在池化层之后再进行非线性处理(即激活函数),现在的操作是经过卷积之后就经过非线性处理(激活函数),然后再进行池化操作;
AlexNet
输入图像:227x227x3的RGB图像(实际上原文中使用的图像是224x224x3,推导的时候使用227x227x3会好一点)
Filter1:11x11,stride=4
得到Conv1:55x55x96
Max-POOL1:3x3,stride=2
得到Conv2:27x27x96
Filter2: 5x5,padding=same
得到Conv3: 27x27x256
Max-Pool2: 3x3,stride=2
得到Conv4: 13x13x256
Filter3: 3x3,padding=same
得到Conv5: 13x13x384
Filter4: 3x3,padding=same
得到Conv6: 13x13x384
Filter5: 3x3,padding=same
得到Conv6: 13x13x256
Max-Pool3: 3x3,stride=2
得到Conv7: 6x6x256
然后将Conv7展开,得到一个长度为6x6x256=9216的向量
经过第一个全连接层
得到FC1: 4096
经过第二个全连接层
得到FC2: 4096
最后使用softmax函数输出识别的结果
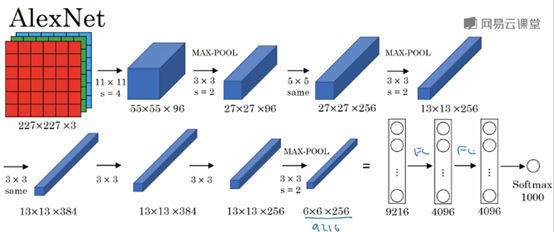
AlexNet包含大约6000万个参数。
AlexNet使用了ReLU激活函数;
AlexNet也使用了LRN层(Local Response Normalization,局部响应归一化层),但是由于LRN可能作用并不大,应用的比较少,在此不再详述。
VGG-16
VGG16网络包含了16个卷积层和全连接层。
VGG网络的一大优点是:简化了神经网络结构。
VGG网络使用的统一的卷积核大小:3x3,stride=1,padding=same,统一的Max-Pool: 2x2,stride=2。
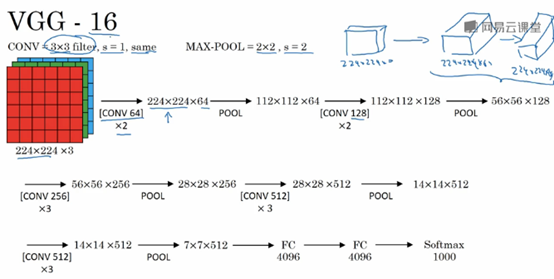
VGG16是一个很大的网络,总共包含1.38亿个参数。因此其主要缺点就是需要训练的特征数量非常巨大。
另外也有VGG19网络,由于VGG16表现几乎和VGG16不分高下,所以很多人还是会使用VGG16。
残差网络(Residual Networks,ResNet)
因为存在梯度消失和梯度爆炸(vanishing and exploding gradients),非常深的网络是很难训练的。
ResNet由残差块(Residual block)组成,
信息流从a[l]到a[l+2],普通的网络需要经过以下几个步骤,称为主路径。
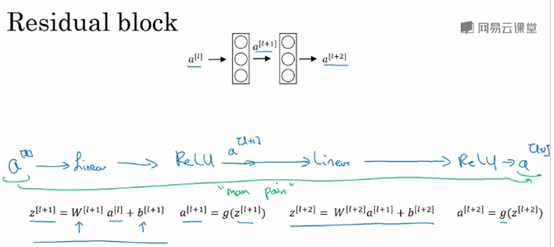
Shortcut/skip connection指a[l]跳过一层或者好几层,从而将信息传递到神经网络的更深层。
Shortcut/skip connection在进行ReLU非线性激活之前加上,如下图所示:
如果我们使用标准的优化算法训练一个普通网络,凭经验,你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练的越来越好才对,但是实际上,如果没有残差网络,对于一个普通的网络来说,深度越深意味着用优化算法越难训练。但是有了ResNet就不一样了,即使网络再深,训练的表现却不错,比如说错误会减少,就算训练深度达到100层的网络也不例外。 这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。
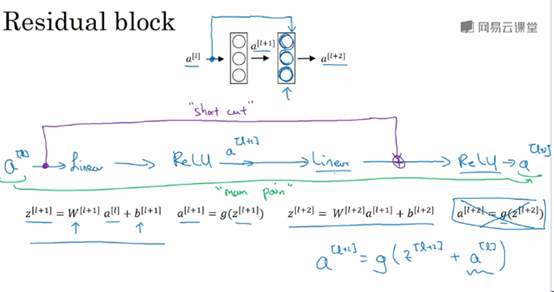
注:上图中,Plain network指的是没有加上蓝色单箭头线的网络;ResNet指的是画上蓝色箭头线的网络。
为什么ResNet能有如此好的表现?
上面讲到,一个网络越深,它在训练集上训练网络的效率会有所减弱,这也是有时候我们不希望加深网络的原因,但是ResNet却能克服这个问题。
假设有一个大型的神经网络,其输入为X,输出激活值a[l],如果你想增加这个神经网络的深度,比如下图,在原网络后面再加上两层全连接层,得到新的激活函数a[l+2]。
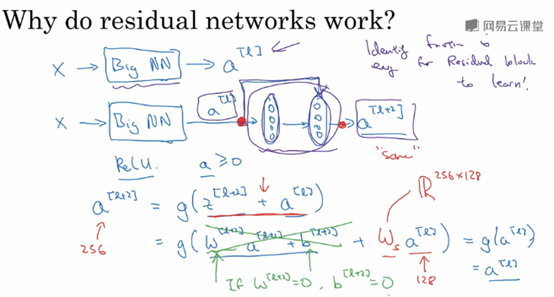
Shortcut使得我们很容易得出a[l+2]=a[l],这意味着即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络。因为只要使得新添加的两层的权重和偏置为0,那么新网络就跟原始网络效果是一样的。但是如果新添加的这些隐层单元学到一些有用信息,那么它可能比学习恒等函数表现更好。
具体可以看这篇文章:http://www.cnblogs.com/hejunlin1992/p/7751516.html
假设z[l+2]与a[l]具有相同维度,所以ResNet使用了许多相同卷积
如果输入与输出有不同的维度,比如说输入的维度是128,a[l]的维度是256,再增加一个矩阵Ws,Ws是一个256x128维度的矩阵,所以Ws乘以a[l]的维度是256,你不需要对Ws做任何操作,它是通过学习得到的矩阵或参数,它是一个固定的矩阵,padding的值为0
内容主要来自与:
Andrew Ng的卷积神经网络课程
卷积神经网络的一些经典网络(Lenet,AlexNet,VGG16,ResNet)的更多相关文章
- [DeeplearningAI笔记]卷积神经网络2.2经典网络
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 [LeNet]--Lécun Y, Bottou L, Bengio Y, et al. Gradient-bas ...
- 卷积神经网络的一些经典网络2(Inception)
在架构内容设计方面,其中一个比较有帮助的想法是使用1x1卷积.1x1卷积能做什么? 对于6x6x1的通道的图片来说,1x1卷积效果不佳,如果是一张6x6x32的图片,那么使用1x1卷积核进行卷积效果更 ...
- 经典卷积神经网络的学习(一)—— AlexNet
AlexNet 为卷积神经网络和深度学习正名,以绝对优势拿下 ILSVRC 2012 年冠军,引起了学术界的极大关注,掀起了深度学习研究的热潮. AlexNet 在 ILSVRC 数据集上达到 16. ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 卷积神经网络之LeNet
开局一张图,内容全靠编. 上图引用自 [卷积神经网络-进化史]从LeNet到AlexNet. 目前常用的卷积神经网络 深度学习现在是百花齐放,各种网络结构层出不穷,计划梳理下各个常用的卷积神经网络结构 ...
- 经典卷积神经网络算法(1):LeNet-5
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 经典卷积神经网络的学习(二)—— VGGNet
1. 简介 VGGNet 是牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发的深度卷积神经网络,其主要探索了卷积神经网络的深度 ...
- 使用mxnet实现卷积神经网络LeNet
1.LeNet模型 LeNet是一个早期用来识别手写数字的卷积神经网络,这个名字来源于LeNet论文的第一作者Yann LeCun.LeNet展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当 ...
- 深入学习卷积神经网络(CNN)的原理知识
网上关于卷积神经网络的相关知识以及数不胜数,所以本文在学习了前人的博客和知乎,在别人博客的基础上整理的知识点,便于自己理解,以后复习也可以常看看,但是如果侵犯到哪位大神的权利,请联系小编,谢谢.好了下 ...
随机推荐
- 掌握这些知识,你的python水平能更上一层楼(续)
笔者的上一篇python文章阅读量不错,看来python爱好者很多,所以再写一篇,以飨读者. 先接着上一篇讲一个问题,下面这段code有没有问题? def countcalls(func): coun ...
- RxJS速成 (下)
上一部分: http://www.cnblogs.com/cgzl/p/8641738.html Subject Subject比较特殊, 它即是Observable又是Observer. 作为Obs ...
- ELK学习笔记(一)安装Elasticsearch、Kibana、Logstash和X-Pack
最近在学习ELK的时候踩了不少的坑,特此写个笔记记录下学习过程. 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因 ...
- 【网络】 数据链路层&物理层笔记
数据链路层 简称链路层,功能在于将数据包封装成帧,控制帧对介质的访问.链路层连接了物理介质和其之上抽象层,可以使上层不用关心用什么方法在什么介质中传输信息. 在帧被传输时经过的每一跳,每个中间设备(通 ...
- 配置SecureCRT以SSH公钥方式登录服务器
为了更方便管理服务器,CRT一个功能非常方便.那就是可以使用私钥认证通过后直接连接,而且对于密码保护比较安全一点. 首先配置ssh Port 32812Protocol 2UseDNS noPubke ...
- java 单向链表实现
1 class Node{//Node类 2 private String data; 3 private Node next; 4 public Node(String data){ 5 this. ...
- ansible之一:安装与配置
ansible特点: 1.不需要安装客户端,通过sshd去通信 2.基于模块工作,模块可以由任何语言开发 3.不仅支持命令行试用模块,也支持yaml格式得playbook 4.支持sudo 5.有提供 ...
- java 对象和封装
软件出现的目的 面向对象设计和开发程序的好处用计算机语言描述现实世界 交流更加流畅用计算机解决现实世界的问题 提高设计和开发效率 面向对象的思想 描述→ 面向对象的世界 ...
- LeetCode算法一题型一以及解答。
题目: 给定一个整数数列,找出其中和为特定值的那两个数. 你可以假设每个输入都只会有一种答案,同样的元素不能被重用. 分析: 普遍方法是直接遍历两遍数组,第一遍用target-nums[i],第二遍找 ...
- Leaflet客户端学习笔记
Leaflet介绍 Leaflet 是一个为建设交互性好适用于移动设备地图,而开发的现代的.开源的 JavaScript 库.代码仅有 33 KB,但它具有开发在线地图的大部分功能.支持插件扩展, L ...