Python + PyQt5 实现美剧爬虫可视工具(二)
美剧《权力的游戏》终于开播最后一季了,在上周写了个简单的可视化美剧的爬虫软件来爬取美剧,链接:https://www.cnblogs.com/weijiutao/p/10614694.html,没想到真有小伙伴用了,并且提出一个小建议,爬取的链接是一个下载链接,需要下载后才能观看,希望能做一个可在线观看的。然后就有了本篇。
话不多说,先看运行结果:
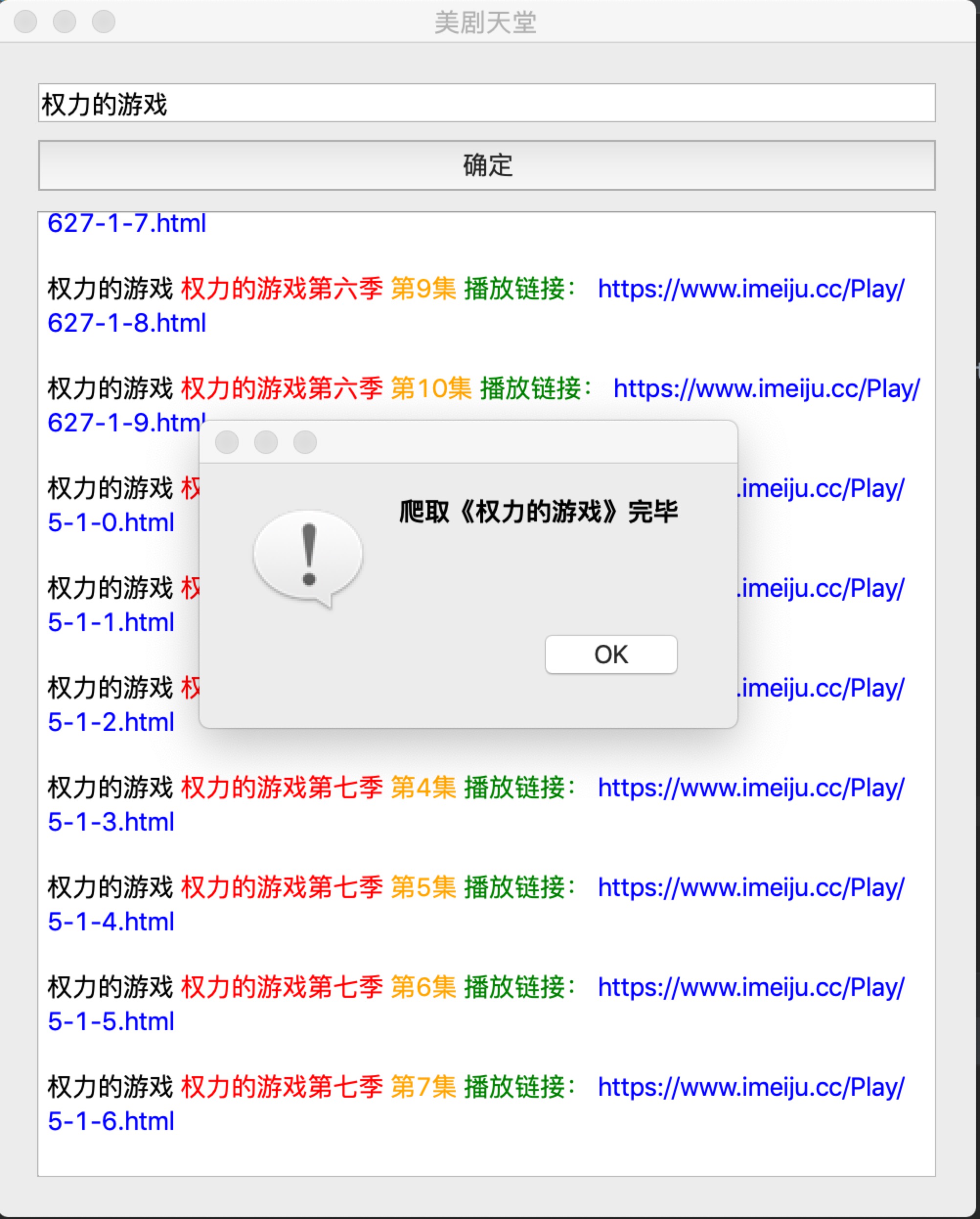
跟之前的其实没多大区别,有变化的是这次爬取的网站链接和内部需要重新做的爬取内容。
注:由于本篇和上篇爬取流程大致相同,所以本篇只是做简单的内容讲解,想看详解流程的可移步上面的链接。
全部代码如下:
import urllib.request
from urllib import parse
from lxml import etree
import math
import ssl
from PyQt5.QtWidgets import QApplication, QWidget, QLineEdit, QTextEdit, QVBoxLayout, QPushButton, QMessageBox
import sys # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context class TextEditMeiJu(QWidget):
def __init__(self, parent=None):
super(TextEditMeiJu, self).__init__(parent)
# 定义窗口头部信息
self.setWindowTitle('爱美剧')
# 定义窗口的初始大小
self.resize(500, 600)
# 创建单行文本框
self.textLineEdit = QLineEdit()
# 创建一个按钮
self.btnButton = QPushButton('确定')
# 创建多行文本框
self.textEdit = QTextEdit()
# 实例化垂直布局
layout = QVBoxLayout()
# 相关控件添加到垂直布局中
layout.addWidget(self.textLineEdit)
layout.addWidget(self.btnButton)
layout.addWidget(self.textEdit)
# 设置布局
self.setLayout(layout)
# 将按钮的点击信号与相关的槽函数进行绑定,点击即触发
self.btnButton.clicked.connect(self.buttonClick) # 点击确认按钮
def buttonClick(self):
# 爬取开始前提示一下
start = QMessageBox.information(
self, '提示', '是否开始爬取《' + self.textLineEdit.text() + "》",
QMessageBox.Ok | QMessageBox.No, QMessageBox.Ok
)
# 确定爬取
if start == QMessageBox.Ok:
self.page = 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
# 取消爬取
else:
pass # 加载输入美剧名称后的页面
def loadSearchPage(self, name, page):
# 将文本转为 gb2312 编码格式
name = parse.quote(name.encode('utf-8'))
# 请求发送的 url 地址
url = "https://www.imeiju.cc/search.php?page=" + str(page) + "&searchword=" + name + "&searchtype="
# 请求报头
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
# 发送请求
request = urllib.request.Request(url, headers=headers)
# 获取请求的 html 文档
html = urllib.request.urlopen(request).read()
# 对 html 文档进行解析
text = etree.HTML(html)
# xpath 获取想要的信息
numberTotal = text.xpath('//span[@class="text-color"][2]/text()')
# 去掉总条数左右的引号
numberTotal = numberTotal[0][1:][:-1]
# 根据显示知道每页 10 条,所以整除 10 并向上取整为总页数
pageTotal = math.ceil(int(numberTotal) / 10)
# 判断搜索内容是否有结果
if pageTotal != 0:
self.loadDetailPage(pageTotal, text, headers)
# 搜索内容无结果
else:
self.infoSearchNull() # 加载点击搜索页面点击的本季页面
def loadDetailPage(self, pageTotal, text, headers):
# 获取每一季的内容(剧名和链接)
node_list = text.xpath('//div[@class="hy-video-details active clearfix"]//div[@class="head"]//a')
items = {}
items['name'] = self.textLineEdit.text()
# 循环获取每一季的内容
for node in node_list:
# 获取信息
title = node.xpath('text()')[0]
link = node.xpath('@href')[0]
items["title"] = title
# 通过获取的单季链接跳转到本季的详情页面
requestDetail = urllib.request.Request("https://www.imeiju.cc" + link, headers=headers)
htmlDetail = urllib.request.urlopen(requestDetail).read()
textDetail = etree.HTML(htmlDetail)
node_listDetail = textDetail.xpath('//div[@class="panel clearfix"][1]//ul/li/a/@href')
self.writeDetailPage(items, node_listDetail)
# 爬取完毕提示
if self.page == int(pageTotal):
self.infoSearchDone()
else:
self.infoSearchContinue(pageTotal) # 将数据显示到图形界面
def writeDetailPage(self, items, node_listDetail):
for index, nodeLink in enumerate(node_listDetail):
items["link"] = nodeLink
# 写入图形界面
self.textEdit.append(
"<div>"
"<font color='black' size='3'>" + items['name'] + "</font>" + "\n"
"<font color='red' size='3'>" + items['title'] + "</font>" + "\n"
"<font color='orange' size='3'>第" + str(index + 1) + "集</font>" + "\n"
"<font color='green' size='3'>播放链接:</font>" + "\n"
"<font color='blue' size='3'>https://www.imeiju.cc" +items['link'] + "</font>"
"<p></p>"
"</div>"
) # 搜索不到结果的提示信息
def infoSearchNull(self):
QMessageBox.information(
self, '提示', '搜索结果不存在,请重新输入搜索内容',
QMessageBox.Ok, QMessageBox.Ok
) # 爬取数据完毕的提示信息
def infoSearchDone(self):
QMessageBox.information(
self, '提示', '爬取《' + self.textLineEdit.text() + '》完毕',
QMessageBox.Ok, QMessageBox.Ok
) # 多页情况下是否继续爬取的提示信息
def infoSearchContinue(self, pageTotal):
end = QMessageBox.information(
self, '提示', '爬取第' + str(self.page) + '页《' + self.textLineEdit.text() + '》完毕,还有' + str(
int(pageTotal) - self.page) + '页,是否继续爬取',
QMessageBox.Ok | QMessageBox.No, QMessageBox.No
)
if end == QMessageBox.Ok:
self.page += 1
self.loadSearchPage(self.textLineEdit.text(), self.page)
else:
pass if __name__ == '__main__':
app = QApplication(sys.argv)
win = TextEditMeiJu()
win.show()
sys.exit(app.exec_())
能在本地运行 Python 的小伙伴直接复制粘贴上面的代码即可运行程序,当然前提是 pip 所依赖的包。
本次我们要爬取的网站是 爱美剧 https://www.imeiju.cc/,具体的操作流程和上一篇差不多是一样的,这里我们就简单的说一下流程:
我们在官网右上角搜索我们想要看的美剧:

然后就能进入我们想要看的美剧列表了:
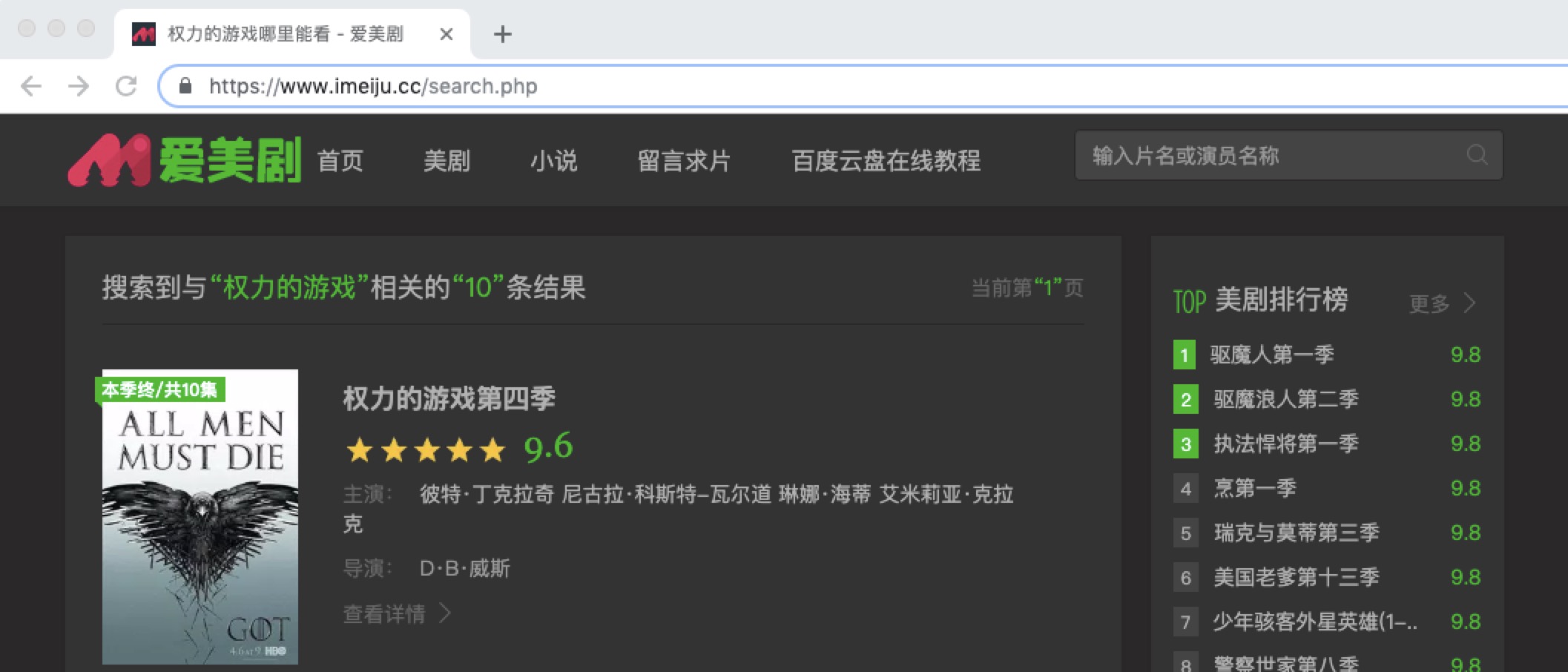
和美剧天堂一样,浏览器的 url 地址仍然不是我们想要的,我们依旧可以点击页面下方的页面跳转来获取真正的 url 链接:
这样我们就可以根据上面的 url 链接里的请求参数 page 和 searchword 来开始爬去我们的数据了,然后就是根据 xpath 对页面进行元素查找,获取要跳转的链接,再进入跳转的链接里就可以获取我们想要看的美剧链接了。
需要注意的是当我们跳转到我们想看的链接,比如上面的 《权力的游戏第四季》
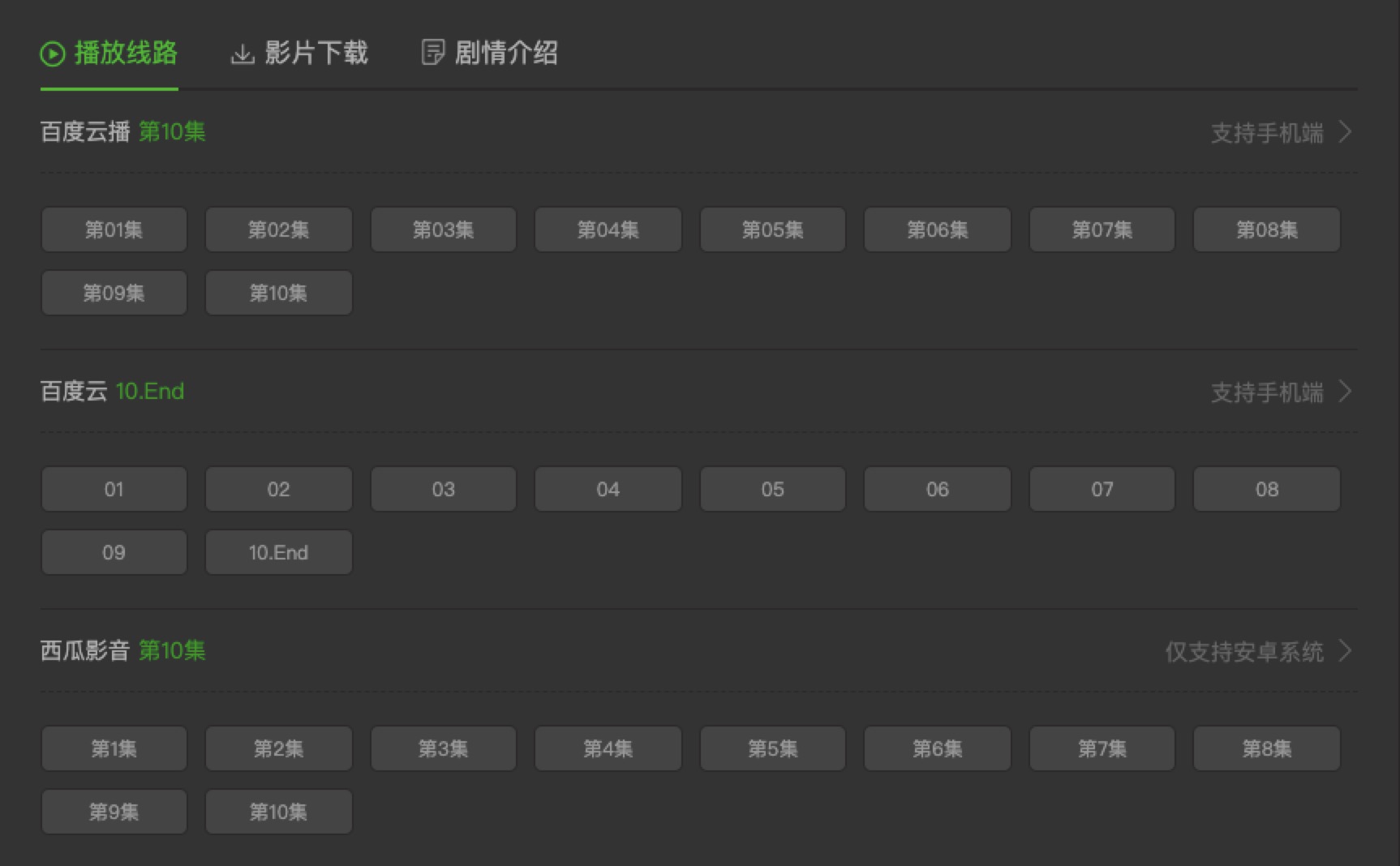
我们发现上面不仅有在线播放,还有影片下载,但是这次我们选择在线播放,但是在线播放又有好几种播放器,这里本人只取了第一种播放第一种播放源,也就是百度云播,完全是没问题的,如果大家觉得都想获取的请自行复制上面的代码修改吧,代码做了很详细的注释,大家应该能看懂。
由于本人不是专门做 Python 的,只是了解那么一点点,上面的代码如有问题,请各位大佬批评指正,在此谢过!
好记性不如烂笔头,特此记录,与君共勉!
最后预祝 《权力的游戏》完美收官!
Python + PyQt5 实现美剧爬虫可视工具(二)的更多相关文章
- Python + PyQt5 实现美剧爬虫可视工具
美剧<权力的游戏>终于要开播最后一季了,作为马丁老爷子的忠实粉丝,为了能够看得懂第八季复杂庞大的剧情架构,本人想着将前几季再稳固一下,所以就上美剧天堂下载来看,可是每次都上去下载太麻烦了, ...
- Python 爬虫批量下载美剧 from 人人影视 HR-HDTV
本人比較喜欢看美剧.尤其喜欢人人影视上HR-HDTV 的 1024 分辨率的高清双字美剧,这里写了一个脚本来批量获得指定美剧的全部 HR-HDTV 的 ed2k下载链接.并依照先后顺序写入到文本文件, ...
- Python爬虫爬取美剧网站
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间.之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了.但是,作为一个宅diao ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- Python 爬虫的工具列表 附Github代码下载链接
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python 爬虫的工具列表大全
Python 爬虫的工具列表大全 这个列表包含与网页抓取和数据处理的Python库.网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pyc ...
- Node.js 爬虫批量下载美剧 from 人人影视 HR-HDTV
这两天发现了一个叫看知乎的站点.是知乎的苏莉安做的,当中爬虫使用的 Node.js.这里就针对上一篇博客中的美剧小爬虫,改用 nodejs 进行实现一下.体验一下强大的 Node.js. 假设之前没实 ...
- Python 爬虫的工具列表
Python 爬虫的工具列表 这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycur ...
- python 爬取豆瓣的美剧
pc版大概有500条记录,mobile大概是50部,只有热门的,所以少一点 url构造很简单,主要参数就是page_limit与page_start,每翻一页,start+=20即可,tag是&quo ...
随机推荐
- Javascript 设计模式 单例
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/30490955 一直很喜欢Js,,,今天写一个Js的单例模式实现以及用法. 1.单 ...
- MFC中打开选择文件夹对话框,并将选中的文件夹地址显示在编辑框中
一般用于选择你要将文件保存到那个目录下,此程序还包含新建文件夹功能 BROWSEINFO bi; ZeroMemory(&bi, sizeof(BROWSEINFO)); //指定存放文件的 ...
- 【状态表示】Bzoj1096 [SCOI2008] 着色方案
Description 有n个木块排成一行,从左到右依次编号为1~n.你有k种颜色的油漆,其中第i种颜色的油漆足够涂ci个木块.所有油漆刚好足够涂满所有木块,即c1+c2+...+ck=n.相邻两个木 ...
- 钉钉机器人zabbix报警
首先在钉钉群聊里添加一个自定义的机器人 并复制webhook的内容 https://oapi.dingtalk.com/robot/send?access_token=37e23308d1b84eb4 ...
- 作为一个零基础的新手,如何系统的自学Java和JavaEE开发技术?
其实这个问题很简单,我用最简单的语言给大家描述一下,学习一样东西就要了解这样东西学完了要干什么事情,有什么作用.然后就是应该学习哪些必要的内容,该如何运用得当的方法进行有效率的学习不至于自己摸不着头脑 ...
- Oracle执行计划学习笔记
目录 一.获取执行计划的方法 (1) explain plan for (2) set autotrace on (3) statistics_level=all (4) dbms_xplan.dis ...
- 一个比喻讲明Docker是什么
之前一直听运维的同事讲Docker,说弄个Docker镜像,打包些应用什么的,还有时不时地在一些帖子里见到过关于Docker的三言两语,然后自己也自我感觉良好的把它总结归纳了一下认为:"往D ...
- 流程控制之if判断
目录 语法(掌握) if if...else if...elif...else 练习(掌握) 练习1:成绩评判 练习2:模拟登录注册 if的嵌套(掌握) 语法(掌握) if判断是干什么的呢?if判断其 ...
- Boosting(提升方法)之XGBoost
XGBoost是一个机器学习味道非常浓厚的模型,在数学上非常规范,运用正则化.L2范数.二阶梯度.泰勒公式和分布式计算方法,对GBDT等提升树模型进行优化,不仅能处理更大规模的数据,而且运行效率特别高 ...
- Android 网络优化,使用 HTTPDNS 优化 DNS,从原理到 OkHttp 集成
一.前言 谈到优化,首先第一步,肯定是把一个大功能,拆分成一个个细小的环节,再单个拎出来找到可以优化的点,App 的网络优化也是如此. 在 App 访问网络的时候,DNS 解析是网络请求的第一步,默认 ...