ElasticSearch权威指南学习(分布式文档存储)
路由文档到分片
- 当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢?
进程不能是随机的,因为我们将来要检索文档。事实上,它根据一个简单的算法决定:
shard = hash(routing) % number_of_primary_shards
- routing值是一个任意字符串,它默认是_id但也可以自定义。
- 这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
主分片和复制分片如何交互
- 我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。
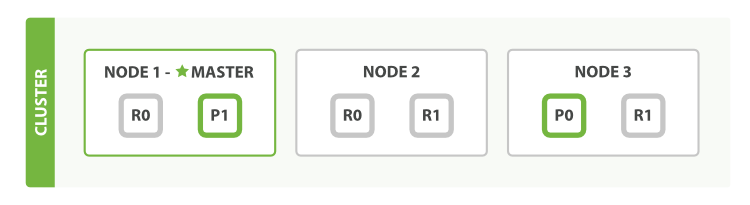
新建、索引和删除文档
- 新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
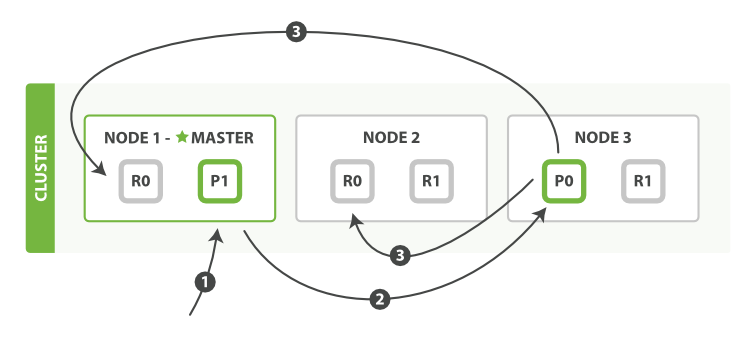
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:- 客户端给Node 1发送新建、索引或删除请求。
- 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
- Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
- 客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
- 有很多可选的请求参数允许你更改这一过程。你可能想牺牲一些安全来提高性能。这一选项很少使用因为Elasticsearch已经足够快
- replication
- 复制默认的值是sync。这将导致主分片得到复制分片的成功响应后才返回。
- 如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
- 上面的这个选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
- consistency
默认主分片在尝试写入时需要规定数量(quorum)或过半的分片(可以是主节点或复制节点)可用。这是防止数据被写入到错的网络分区。规定的数量计算公式如下:
int( (primary + number_of_replicas) / 2 ) + 1
- consistency允许的值为one(只有一个主分片),all(所有主分片和复制分片)或者默认的quorum或过半分片。
注意number_of_replicas是在索引中的的设置,用来定义复制分片的数量,而不是现在活动的复制节点的数量。如果你定义了索引有3个复制节点,那规定数量是:
int( (primary + 3 replicas) / 2 ) + 1 = 3
但如果你只有2个节点,那你的活动分片不够规定数量,也就不能索引或删除任何文档。
- timeout
- 当分片副本不足时会怎样?Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置timeout参数让它终止的更早:100表示100毫秒,30s表示30秒。
- ps:新索引默认有1个复制分片,这意味着为了满足quorum的要求需要两个活动的分片。当然,这个默认设置将阻止我们在单一节点集群中进行操作。为了避开这个问题,规定数量只有在number_of_replicas大于一时才生效。
检索文档
- 对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
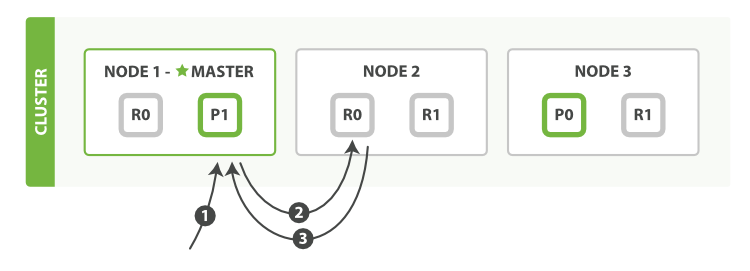
- 客户端给Node 1发送get请求。
- 节点使用文档的_id确定文档属于分片0。分片0对应的复制分片在三个节点上都有。此时,它转发请求到Node 2。
- Node 2返回文档(document)给Node 1然后返回给客户端。
局部更新文档
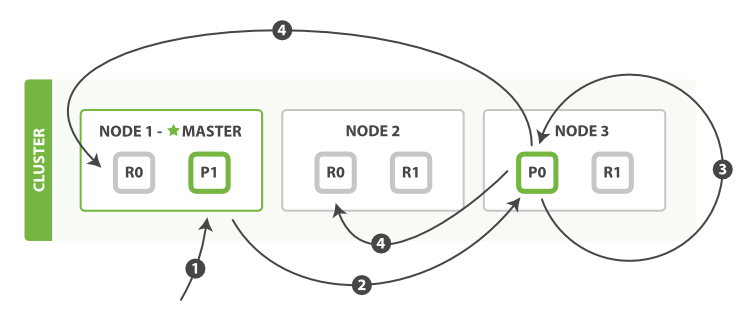
- 客户端给Node 1发送更新请求。
- 它转发请求到主分片所在节点Node 3。
- Node 3从主分片检索出文档,修改_source字段的JSON,然后在主分片上重建索引。如果有其他进程修改了文档,它以retry_on_conflict设置的次数重复步骤3,都未成功则放弃。
- 如果Node 3成功更新文档,它同时转发文档的新版本到Node 1和Node 2上的复制节点以重建索引。当所有复制节点报告成功,Node 3返回成功给请求节点,然后返回给客户端。
- ps: 当主分片转发更改给复制分片时,并不是转发更新请求,而是转发整个文档的新版本。记住这些修改转发到复制节点是异步的,它们并不能保证到达的顺序与发送相同。
多文档模式
- mget和bulk API与单独的文档类似。差别是请求节点知道每个文档所在的分片。它把多文档请求拆成每个分片的对文档请求,然后转发每个参与的节点。
- 一旦接收到每个节点的应答,然后整理这些响应组合为一个单独的响应,最后返回给客户端。
- 一个mget请求检索多个文档的顺序步骤
- 客户端向Node 1发送mget请求。
- Node 1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接收,Node 1构建响应并返回给客户端。
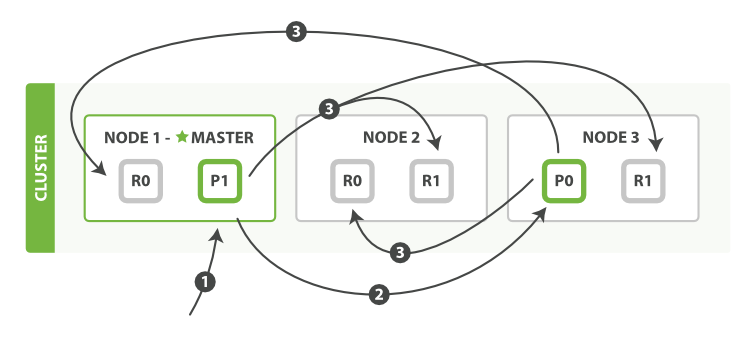
- 一个bulk执行多个create、index、delete和update请求的顺序步骤
- 客户端向Node 1发送bulk请求。
- Node 1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。
- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。一旦所有复制节点报告所有操作已成功完成,节点就报告success给请求节点,后者(请求节点)整理响应并返回给客户端。
- ps: bulk API还可以在最上层使用replication(同步异步)和consistency(一致性,满足多少复制分片收到请求结果才返回最终结果)参数
批量格式问题
- 为什么是奇怪的格式?
- 如果每个单独的请求被包装到JSON数组中,那意味着我们需要:
- 解析JSON为数组(包括文档数据,可能非常大)
- 检查每个请求决定应该到哪个分片上
- 为每个分片创建一个请求的数组
- 序列化这些数组为内部传输格式
- 发送请求到每个分片
这可行,但需要大量的RAM来承载本质上相同的数据,还要创建更多的数据结构使得JVM花更多的时间执行垃圾回收。
- 取而代之的,Elasticsearch则是从网络缓冲区中一行一行的直接读取数据。它使用换行符识别和解析action/metadata行,以决定哪些分片来处理这个请求。
- 这些行请求直接转发到对应的分片上。这些没有冗余复制,没有多余的数据结构。整个请求过程使用最小的内存在进行。
ElasticSearch权威指南学习(分布式文档存储)的更多相关文章
- ElasticSearch权威指南学习(文档)
什么是文档 在Elasticsearch中,文档(document)这个术语有着特殊含义.它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasti ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
- ElasticSearch文档及分布式文档存储
1.什么是文档? 文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的 ...
- ElasticSearch权威指南学习(分布式集群)
空集群 只有一个空节点的集群 一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数 ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- Elasticsearch 分布式文档存储
shard = hash(routing) % number_of_primary_shards决定文档在哪个分片上,routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值. ...
- ElasticSearch权威指南学习(映射和分析)
概念 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等).+ 分析(analysis)机制用于进行全文 ...
- 分布式文档存储数据库 MongoDB
MongoDB 详细介绍 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bjson格式,因此可以 ...
随机推荐
- Java遍历树(深度优先+广度优先)
在编程生活中,我们总会遇见树性结构,这几天刚好需要对树形结构操作,就记录下自己的操作方式以及过程.现在假设有一颗这样树,(是不是二叉树都没关系,原理都是一样的) 1.深度优先 英文缩写为DFS即Dep ...
- LeetCode OJ 129. Sum Root to Leaf Numbers
题目 Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a num ...
- .do的消除
其实就是在web.xml中去掉.do即可 那里有拦截器作用,什么样的文件可以进入前端控制器1
- pyton 模块之 pysmb 文件上传和下载(linux)
首先安装pysmb模块 下载文件 from smb.SMBConnection import SMBConnection conn = SMBConnection('anonymous', '', ' ...
- 二维凸包 Graham扫描算法
题目链接: http://poj.org/problem?id=1113 求下列点的凸包 求得凸包如下: Graham扫描算法: 找出最左下的点,设为一号点,将其它点对一号点连线,按照与x轴的夹角大小 ...
- Windows驱动开发VS2012 DDK/WDK的环境配置
[开发Windows驱动的配置是很必要的,下文将详细介绍VS2012如何配置驱动开发环境] [转载] 以下部分内容是转载博客:http://blog.csdn.net/huangxy10/articl ...
- layui模板和jfinal混合使用注意
<!-- 列表信息展示 --> <div class="layui-row"> <table class="layui-table" ...
- 使用requests抓取https报SSL错误
安装requests的方法:sudo pip install requests 当碰到requests链接https的时候报SSL错误的时候使用如下解决: 1:将python的pip 版本升级到9.0 ...
- [leetcode]3. Longest Substring Without Repeating Characters无重复字母的最长子串
Given a string, find the length of the longest substring without repeating characters. Examples: Giv ...
- 【bug小记】应用跳转白屏
tv端项目 测试那边反馈我们的应用跳转到别的应用,再跳转回来会出现白屏的情况. 其实这个原因很简单,就是系统内存不足了把我们的app进程销毁了 所以再回到我们的应用的时候需要重新绘制,而这个" ...