Scrapy: 初识Scrapy
1.初识Scrapy
Scrapy是为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或者存储历史数据等一系列的程序中。
2.选择一个网站
当需要从某个网站获取信息时,但该网站未提供API或者能通过程序获取信息的机制时,Scapy可以助你一臂之力。
3.定义想抓去的数据
在Scrapy中,通过Scrapy Items来完成的
import scrapy
class Torrent(scrapy.Item):
url=scrapy.Field()
name=scrapy.Field()
description=scrapy.Field()
size=scrapy.Field()
4.编写提取数据的Spider
编写一个spider来定义初始URL,针对后续链接的规则以及从页面中提取数据的规则
使用XPath来从页面的HTML源码中选择需要提取的数据
结合自己的内容给出spider代码,eg:
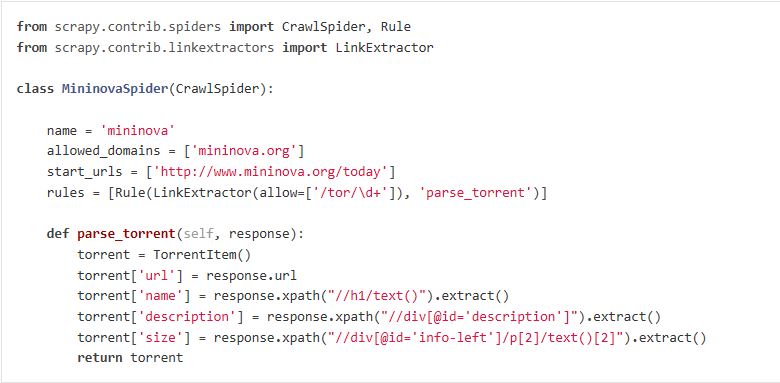
5.执行spider,获取数据
运行spider来获取网站的数据,并以JSON格式存入到文件中:
scrapy crawl mininova -o scraped_data.json
命令中使用了feed导出 来导出JSON文件,可以修改到处格式或者存储后端,同时也可以编写管道将item存储到数据库中。
6.查看提取到数据
执行结束后,查看scraped_data.json,将看到提取到的item
7.还有什么?
- Scrapy提供了很多强大的特性来使得爬取更为简单高效,例如:
- HTML,XML源数据选择及提取的内置支持
- 提供了一系列的spider之间共享的可复用的过滤器,对智能处理爬取数据提供了内置支持
- 通过feed导出提供了多格式(JSON,CSV,XML),多存储后端(FTP,S3,本地文件系统)的内置支持
- 提供了media pipeline,可以自动下载爬取到的数据中的图片(或者其他资源)
- 高扩展性,可以通过使用signals,设计好的API(中间件,exetensions,pipelines)来定制实现您的功能。
- 内置的中间件及扩展为下列功能提供了支持:
- cookies and session处理
- HTTP压缩
- HTTP认证
- HTTP缓存
- user-agent模拟
- robots.txt
- 爬取深度限制
- 其他
- 针对非英语系统中不标准或者错误的编码声明,提供了自动检测及健壮的编码支持
- 支持根据模板生成爬虫。在加速爬虫创建的同时,保持在大型项目中的代码更为一致
- 针对多爬虫性能评估,失败检测,提供了可扩展的状态收集工具
- 提供交互式shell终端,为测试XPath表达式,编写和调试爬虫提供了极大的方便
- 提供System service,简化在生产环境的部署及运行
- 内置Telnet终端,通过在Scrapy进程中钩入Python终端,可以查看并调试爬虫
- Logging在爬虫过程中捕捉错误提供了方便
- 支持Sitemaps爬取
- 具有缓存的DNS解析器
Scrapy: 初识Scrapy的更多相关文章
- python自动化开发-[第二十四天]-高性能相关与初识scrapy
今日内容概要 1.高性能相关 2.scrapy初识 上节回顾: 1. Http协议 Http协议:GET / http1.1/r/n...../r/r/r/na=1 TCP协议:sendall(&qu ...
- python爬虫框架scrapy初识(一)
Scrapy介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.所谓网络爬虫,就是一个在网上到处或定向抓取数据的 ...
- scrapy框架系列 (1) 初识scrapy
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- 初识Scrapy之再续火影情缘
前言Scrapy框架之初窥门径1 Scrapy简介2 Scrapy安装3 Scrapy基础31 创建项目32 Shell分析4 Scrapy程序编写41 Spiders程序测试42 Items编写43 ...
- 爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例
1. Scrapy框架 Scrapy功能非常强大,爬取效率高,相关扩展组件多,可配置和可扩展程度非常高,它几乎可以应对所有反爬网站,是目前Python中使用最广泛的爬虫框架. 1.1 Scrapy介绍 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- Scrapy之Scrapy shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
随机推荐
- 【CF884D】Boxes And Balls 哈夫曼树
[CF884D]Boxes And Balls 题意:有n个箱子和若干个球,球的颜色也是1-n,有ai个球颜色为i,一开始所有的球都在1号箱子里,你每次可以进行如下操作: 选择1个箱子,将里面所有的球 ...
- vue之计算属性和侦听器
一.计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div> {{ message.split('').rev ...
- PKCS 发布的15 个标准与X509
PKCS 发布的15 个标准,转自:http://falchion.iteye.com/blog/1472453 PKCS 全称是 Public-Key Cryptography Standards ...
- linux下pip安装pygame
在学习python的过程中要用到pygame,在安装过程中遇到一些问题,经百度解决.因为使用的版本为python3,故以下教程针对python3版本.安装教程如下: 一.首先你要确保你已经安装了pip ...
- HDU 3507 - Print Article - [斜率DP]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3507 Zero has an old printer that doesn't work well s ...
- Docker命令详解(build篇)
命令格式:docker build [OPTIONS] <PATH | URL | -> Usage: Build an image from a Dockerfile. 中文意思即:使用 ...
- easyui-layout个人实例
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- Python的浅拷贝与深拷贝
定义: =号浅拷贝:在Python中对象的赋值其实就是对象的引用.copy了之后两个仍然是同一个东西.那么他们内部的元素自然也是一样的,对其中一个进行修改,另一个也会跟着变> copy()浅拷贝 ...
- js-之NaN和isNaN
NaN (not is number) 不是一个数字的意思,在js中整型和浮点数都是Number类型. 除此之外,Number还有一个特殊的值,NaN. 一.可能会产生NaN值的情况 1.表达式计算, ...
- A Simple Problem with Integers---poj3468线段树
http://poj.org/problem?id=3468 题意:有一个比较长的区间可能是100000.长度, 每个点都有一个值(值还比较大), 现在有一些操作: C a b c, 把区间a-- ...