说说xgboost算法
xgboost算法最近真是越来越火,趁着这个浪头,我们在最近一次的精准营销活动中,也使用了xgboost算法对某产品签约行为进行预测和营销,取得了不错的效果。说到xgboost,不得不说它的两大优势,一是准确率高,这次营销模型的AUC达到了94%;二是训练速度快,在几十万样本集,几十个特征的情况下,1分钟就可以训练完毕。到底是什么原因使得这门武功又快又准?下面就来简单分析一下。
Xgboost的全称是Extreme Gradient Boosting,它是由华盛顿大学的陈天奇于2014年所创,由于它的高精度和高效率,在近几年的算法比赛中被广泛应用并取得了很好的成绩,大放异彩。xgboost可以看作在决策树和GBDT的基础上进化而来的,这个过程简略表示如下:

1、决策树(Decision Tree)
决策树的优点是解释性强、简单、速度快,缺点是模型不稳定、对特征纯度依赖高,是最简单的模型。
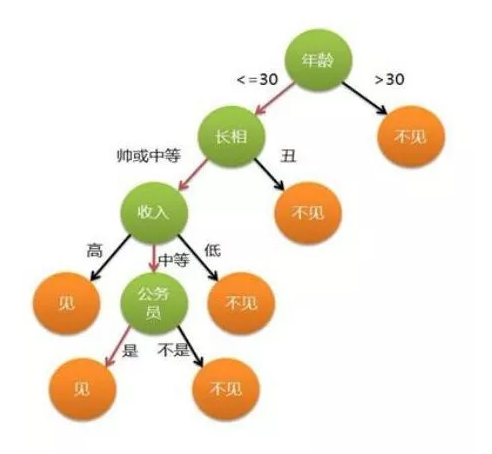
2、GBDT(Gradient Boosting Decision Tree)
因为单个决策树的表达能力、范化能力和精度有限,所以GBDT引入了复合树和增量学习的概念。与随机森林相似,GBDT也是由多个CART树组合形成一个最终分类器。在GBDT生成树的时候,每棵树沿着前一棵树误差减小的梯度方向进行训练。举例来说,一个手机的价格100元,用GBDT进行建模,第一棵树拟合结果是90元,第二棵树是8元,第三棵树是2元,每一棵新生成的树都使得模型的偏差越来越小,三棵树级联起来形成最终的模型。xgboost的g也体现在这个地方。
举个原论文中的栗子,判断一个人是否使用电脑?
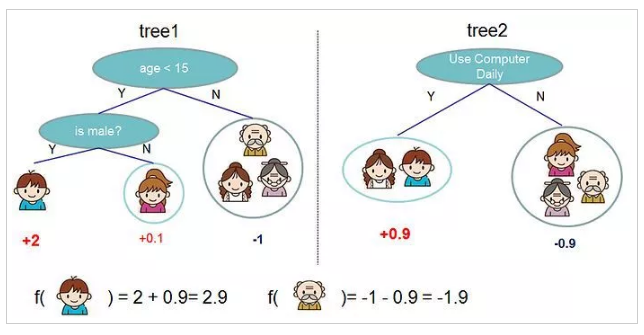
如图很好地解释了复合树和增量学习的概念,通过这两点,GBDT的范化能力和精度比决策树有了大幅提高。
3、Xgboost
Xgboost在GBDT的基础上又进行了大幅改进,算法的综合性能有飞跃式的提高,与GBDT相比,Xgboost的优点主要体现精度高、速度快、可扩展性高、防止过拟合这几点,下面逐条分析。
(1)精度高
Xgboost的损失函数用到了二阶导数信息,而GBDT只用到一阶;
在大多数情况,数据集都无法避免出现null值的情况,从而导致梯度稀疏,在这种情况下,xgboost为损失函数指定了默认的梯度方向,间接提升了模型精度和速度。
(2)速度快
Xgboost在生成树的最佳分割点时,放弃了贪心算法,而是采用了一种从若干备选点中选择出最优分割点的近似算法,而且可以多线程搜索最佳分割点。Xgboost还以块为单位优化了特征在内存中的存取,解决了Cache-miss问题,间接提高了训练效率。根据论文所说,通过这些方法优化之后,xgboost的训练速度比scikit-learn快40倍。
(3)可扩展性高
GBDT的基分类器是CART,而xgboost的基分类器支持CART,Linear,LR;
Xgboost的目标函数支持linear、logistic、softmax等,可以处理回归、二分类,多分类问题。另外,Xgboost还可以自定义损失函数。
(4)防止过拟合
xgboost在损失函数里加入了正则项,降低模型的方差,使模型更简单,防止过拟合,还能自动处理one-hot特征,但是one-hot会增加内存消耗,增加训练时间,陈天奇建议one-hot类别数量在[0, 100]范围内使用;
xgboost在每一轮迭代时为每棵树增加一个权重,以此来缩减个别树的影响力;
xgboost还支持特征的下采样,类似于随机森林,也可以防止过拟合,并且提高速度,不过这个功能在当前版本没有实现。
Xgboost的优缺点:
每门武功都有自己的优缺点,xgboost也不例外,这里我用随机森林作为对比,从正反两个角度来解释一下这两种算法的区别。xgboost适用于高偏差,低方差的训练集。而随机森林适用于高方差,低偏差的训练集,二者是决策树进化的两个方向。

Xgboost的思想是增量学习,通过树的级联不断修正偏差,方差较大的数据和异常值会对模型造成一定的影响。而随机森林的思想是bagging,树与树之间互相独立,通过多次有放回的采样,然后所有树共同投票,以此降低模型的方差,二者有所区别。从正面来说,对于偏差大的训练集,随机森林必须训练到20层树的深度才能达到的准确率,xgboost只需几层树就能达到,因为随机森林依赖的树的深度降低偏差,xgboost通过几个树的级联就把偏差轻松修正了。从反面来说,对于方差大的训练集,随机森林可以轻松拟合,xgboost就不容易拟合好,同理不再赘述。
说说xgboost算法的更多相关文章
- XGBoost算法--学习笔记
学习背景 最近想要学习和实现一下XGBoost算法,原因是最近对项目有些想法,准备做个回归预测.作为当下比较火的回归预测算法,准备直接套用试试效果. 一.基础知识 (1)泰勒公式 泰勒公式是一个用函数 ...
- 机器学习总结(一) Adaboost,GBDT和XGboost算法
一: 提升方法概述 提升方法是一种常用的统计学习方法,其实就是将多个弱学习器提升(boost)为一个强学习器的算法.其工作机制是通过一个弱学习算法,从初始训练集中训练出一个弱学习器,再根据弱学习器的表 ...
- Python机器学习笔记:XgBoost算法
前言 1,Xgboost简介 Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器.因为Xgboost是一种提升树模型,所以它是将许多 ...
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- 转载:XGBOOST算法梳理
学习内容: CART树 算法原理 损失函数 分裂结点算法 正则化 对缺失值处理 优缺点 应用场景 sklearn参数 转自:https://zhuanlan.zhihu.com/p/58221959 ...
- xgboost算法教程(两种使用方法)
标签: xgboost 作者:炼己者 ------ 欢迎大家访问我的简书以及我的博客 本博客所有内容以学习.研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢! ------ ...
- XGBoost算法
一.基础知识 (1)泰勒公式 泰勒公式是一个用函数在某点的信息描述其附近取值的公式.具有局部有效性. 基本形式如下: 由以上的基本形式可知泰勒公式的迭代形式为: 以上这个迭代形式是针对二阶泰勒展开,你 ...
- XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析.虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲 ...
- 04-09 XgBoost算法
目录 XgBoost算法 一.XgBoost算法学习目标 二.XgBoost算法详解 2.1 XgBoost算法参数 2.2 XgBoost算法目标函数 2.3 XgBoost算法正则化项 2.4 X ...
随机推荐
- python 字典中 重复值去除
tuple_r_dict = lambda _dict: dict(val[::-1] for val in _dict.items()) # Python3.x tuple_r_dict(tuple ...
- Apache Struts2高危漏洞(S2-057CVE-2018-11776)
花了两天时间,特此记录 一:背景: 2018年8月22日,Apache Strust2发布最新安全公告,Apache Struts2存在远程代码执行的高危漏洞. 二:漏洞产生原理: 1.需要知道对应跳 ...
- SQL With (递归CTE查询)
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE).该表达式源自简单查询,并且在单条 SELECT.INSERT.UPDATE 或 DELETE 语句的执行范围内定义.该子句也可用在 CRE ...
- YAML基本语法
正如YAML所表示的YAML Ain’t Markup Language,YAML /ˈjæməl/ 是一种简洁的非标记语言.YAML以数据为中心,使用空白,缩进,分行组织数据,从而使得表示更加简洁易 ...
- Android Studio--按钮跳转新页
MainActivity.xml: <Button android:id="@+id/btnGo" android:layout_width="wrap_conte ...
- js 冒泡事件 点击任意地方隐藏元素
$(function () { $("#but").click(function (e) {// $();//显示速度 /*阻止冒泡事件*/ e = window.event || ...
- 3. Go语言基本类型
Go语言基本类型如下: bool string 数值类型 (int8, int16, int32, int64, int, uint8, uint16, uint32, uint64, uint, f ...
- 【Django】 TemplateDoesNotExist at /HTMLeditor/HTMLeditorHandler/
TemplateDoesNotExist at /HTMLeditor/HTMLeditorHandler/search/indexes/htmleditor/htmleditor_text.txt ...
- 第一个只出现一次的字符字符(python)
题目描述 在一个字符串(0<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写). # -*- codin ...
- CSS文本超出指定行数省略显示
单行: overflow: hidden; text-overflow: ellipsis; white-space: nowrap; 2行: font-size: 17px;overflow: hi ...