利用Python攻破12306的最后一道防线
各位同学大家好,我是强子,好久没跟大家带来最新的技术文章了,最近有好几个同学问我12306自动抢票能否实现,我就趁这两天有时间用Python做了个12306自动抢票的项目,在这里我来带着大家一起来看看到底如何一步一步攻克万恶的12306。文末有福利!!!
我们要做12306抢票而官方又没有提供相应的接口(也不可能提供),那么我们就只能通过自己寻找12306的数据包和买票流程来模拟浏览器行为实现自动化操作了,说直白一点就是爬虫,接下来进入正题,前方高能,请系好安全带~~

首先在买票前我们需要先确认是否有票,那么进行正常的查票,打开12306查票网站https://kyfw.12306.cn/otn/leftTicket/init 输入出发地和目的地进行搜索。
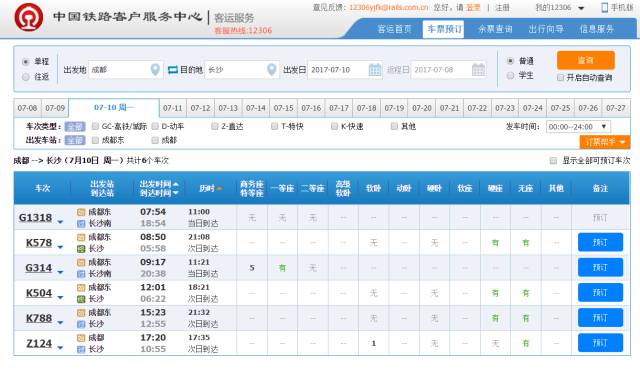
那么一般在看到这个页面的时候我们能想到的获取车次及相关信息的方式是什么呢?对于零基础的同学而言第一时间就会想到在源代码里面找,但这里事实上源代码里面根本没有相关内容,因为该请求是采用的js中ajax异步请求的方式动态加载的,并不包含在源代码里面,所以我们只能够通过抓包的方式来查看浏览器与服务器的数据交互情况,我用的是谷歌浏览器所以打开开发者工具的快捷键是F12。
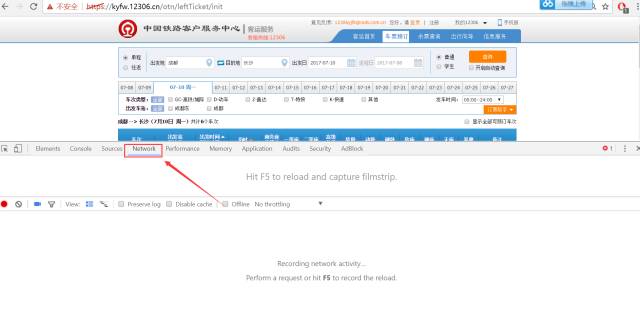
注意选中红线框出来的那一个选项,此时只要是浏览器和服务器发生数据交互都会在下面列表框显示出来,我们再次点击查询按钮。
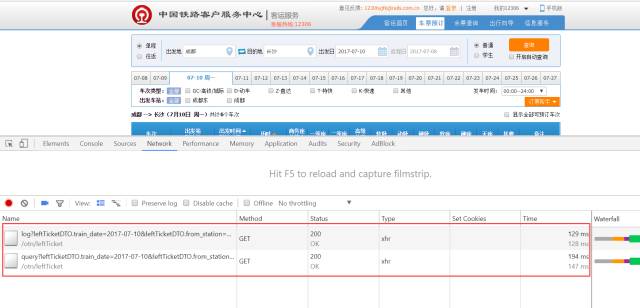
结果发现列表当中有了两个请求,也就是说我们点击查询按钮以后浏览器向服务器发起了两次请求,那么我们来通过返回值分析下那个请求才是真正获取到车次相关数据的请求,以便我们用Python来模拟浏览器操作。
第一次请求:
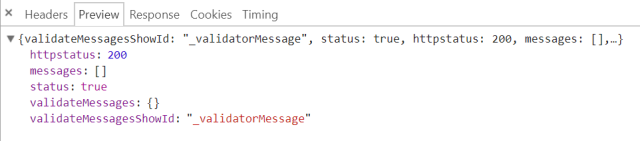
很明显第一次请求返回的值没有我们需要的车次信息。
第二次请求:
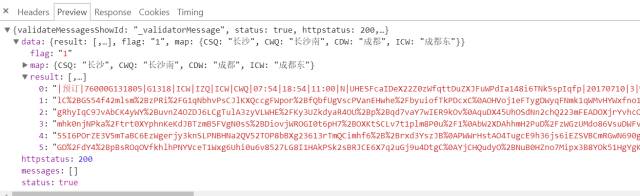
第二次请求里面看到了很多数据,虽然我们暂时还没看到车次信息,但是我们发现它有个特性,就是有个列表的值里面有6个元素,而刚好我们搜索出来的从长沙到成都的车辆也是6条数据,所以这两者肯定有一定关系,那么我们先用Python来获取到这些数据再进行下一步分析:
# -*- coding: utf-8 -*-importurllib2 importsslssl._create_default_https_context = ssl._create_unverified_context defgetList():req = urllib2.Request('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-07-10&leftTicketDTO.from_station=CDW&leftTicketDTO.to_station=CSQ&purpose_codes=ADULT') req.add_header( 'User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36') html = urllib2.urlopen(req).read() returnhtml printgetList()
首先定义一个函数来获取车次列表信息:
从抓包数据中获取到该请求的url:https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-07-10&leftTicketDTO.from_station=CDW&leftTicketDTO.to_station=CSQ&purpose_codes=ADULT
为了防止被12306检测到屏蔽我们的请求那么我们可以简单的增加个头信息来模拟浏览器的请求。
req. add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
其中的:
ssl. _create _default_https _context = ssl. _create _unverified _context
| zhengshu5.com |
| dajinnylee.cn |
| xc.xyseo.net |
| xyseo.net/xuancai/ |
是因为12306采用的是https协议,而ssl证书是它自己做的并没有得到浏览器的认可,所以Python默认是不会请求不受信任的证书的网站的,我们可以通过这行代码来关闭掉证书的验证
那么我们先来看看能不能正常获取到我们想要的信息 :
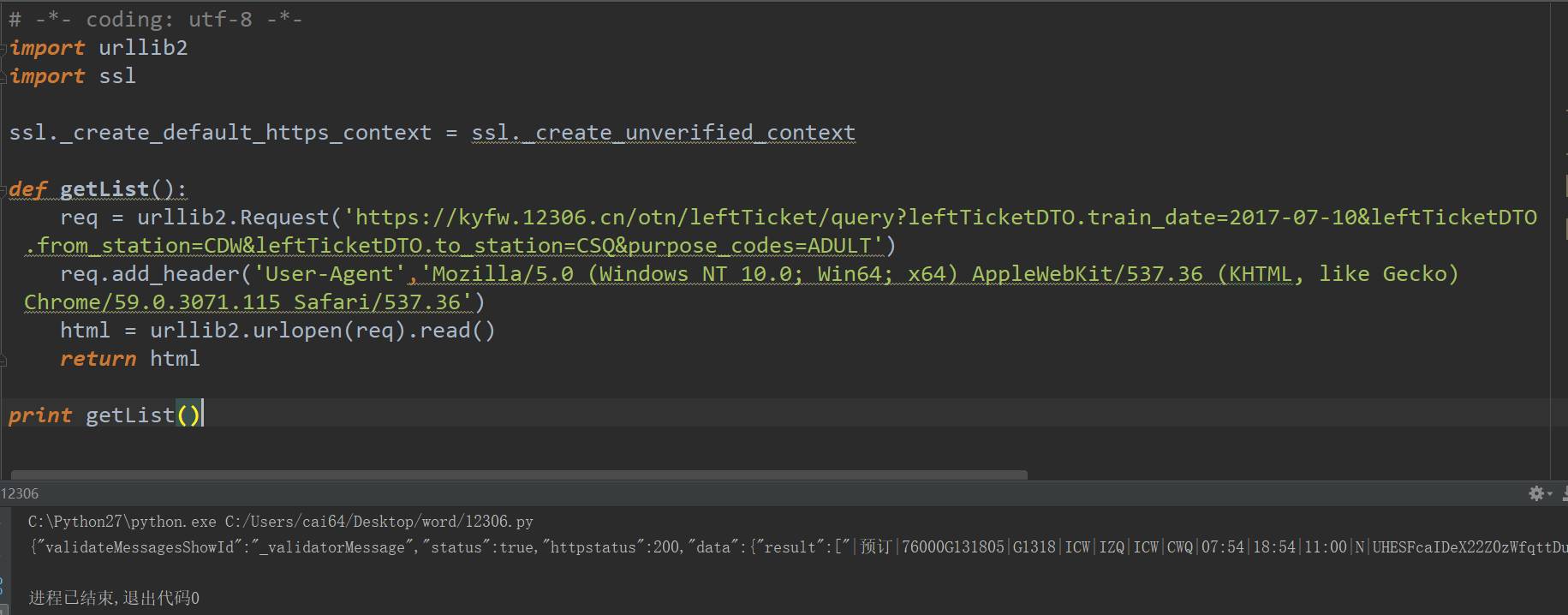
事实证明我们的操作没有问题,接下来先拿到包含有6条数据的这个列表再说。
返回的数据是json格式,但是Python标准数据类型中没有json这个类型,所以对于Python而言它就是个字符串,如果要非常方便的操作这个json我们就可以借助Python中的json这个包来把json这个字符串变成dict类型,然后通过dict的键值对操作方法把列表取出来并进行返回。
# -*- coding: utf-8 -*-importurllib2 importssl importjsonssl._create_default_https_context = ssl._create_unverified_contextdef getList(): req = urllib2. Request('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date= 2017- 07-10&leftTicketDTO.from_station= CDW&leftTicketDTO.to_station= CSQ&purpose_codes=ADULT') req.add_header(' User- Agent',' Mozilla/ 5. 0( WindowsNT10. 0; Win64; x64)AppleWebKit/ 537. 36( KHTML, like Gecko) Chrome/ 59. 0. 3071. 115Safari/ 537. 36') html = urllib2.urlopen(req).read() dict = json.loads(html) result= dict['data'][' result'] returnresult
最终返回的是一个list数据,我们先把这个数据for出来再看看每一条数据都有些什么东西:
foriingetList(): print i
for出来之后我们先来看看第一条数据是什么样的:
| 预订| 76000G131805| G1318| ICW| IZQ| ICW| CWQ| 07:54| 18:54| 11:00| N|UHESFcaIDeX22Z0zWfqttDuZXJFuWPdIa148i6TNk5spIqfp| 20170710| 3| W2| 01| 16| 0|0||||||||||| 无| 无| 无|| O0M090|OM9
其实我们稍微留一下就会发现里面有包含G1318,07:54,18:54,无这样的车次信息的,只不过看起来比较乱,但是他们都有一个特点,每个数据都是由|这个符号分开的,所以我们可以通过用|分割看看能发现什么呢?
foriingetList(): forn ini. split('|'): print n break
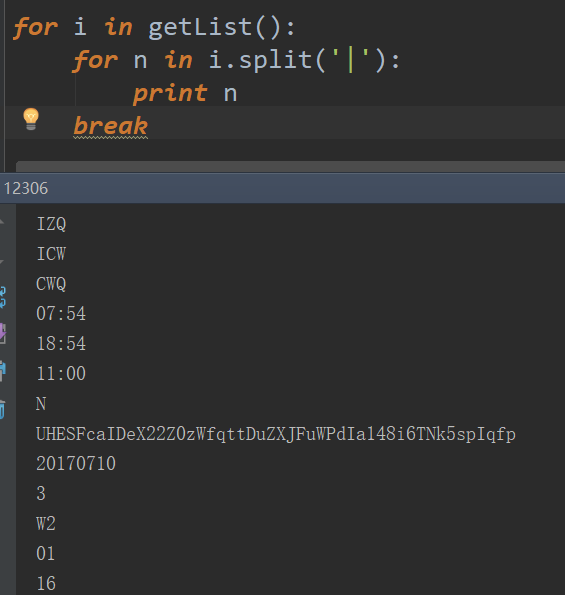
可以看到所有的值都打印出来了,我们再在前面加上一个序号就能清楚到看到每个序号所对应的值到底是什么了,比如有辆火车硬座还剩3张票,软卧还剩8张票,那我们就查看哪个序号对应的值是3哪个序号对应的值是8就搞清楚了哪个序号是代表什么座次或者其他参数了。
c = 0fori ingetList(): forn ini.split( '|'): print'[%s] %s'%(c,n) c += 1c = 0break#索引3=车次#索引8=出发时间#索引9=到达时间
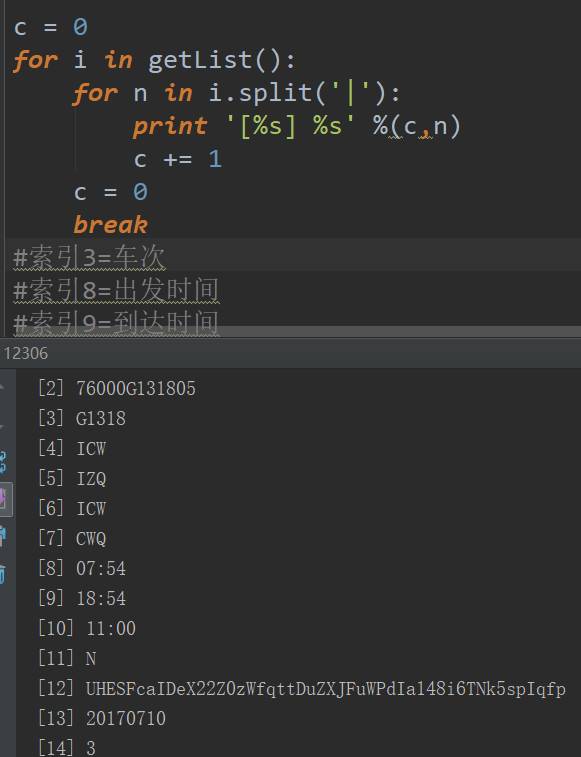
到了这里不知道同学们有没有发现一个问题,就是我用的这个函数只能够获取到从长沙到成都的数据,而别人不一定是买这个方向的火车,所以我们还得搞清楚请求的url当中的出发站和到达站的值是怎么来的。
https:/ /kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date= 2017- 07-10&leftTicketDTO.from_station= CDW&leftTicketDTO.to_station= CSQ&purpose_codes=ADULT
先找到出发站和到达站的参数分别是:
leftTicketDTO.from_station= CDWleftTicketDTO.to_station=CSQ
然而通过查找和分析我并没有发现这两个参数有规律,那么也就是说这两个值是在之前的请求里面就已经获取到了的,通过检查网页源代码没有找到,那么又只能通过抓包的方式来找。
在抓包过程中找到了一个包的返回值是附带有各城市的代号的,url如下:
https:/ /kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9018

那么我们把这里面的城市数据复制出来单独新建一个cons.py的文件保存起来
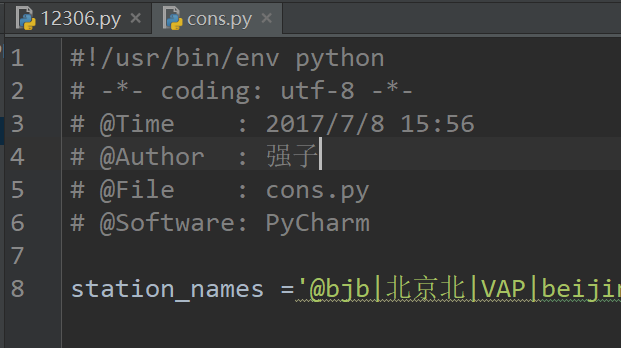
然后我们通过把参数做成通过输入出发城市和到达城市就可以直接在这个数据里面匹配到相应的城市代号,代码如下:
station = {} fori incons.station_names. split( '@'): ifi: tmp = i. split( '|') station[tmp[ 1]] = tmp[ 2] #print stationtrain_date = raw_input( '请输入出发时间')from_station = station[raw_input( '请输入出发城市')]to_station = station[raw_input( '请输入到达城市')]
到这里就已经能够通过输入时间,城市获取相应的车次信息了 。
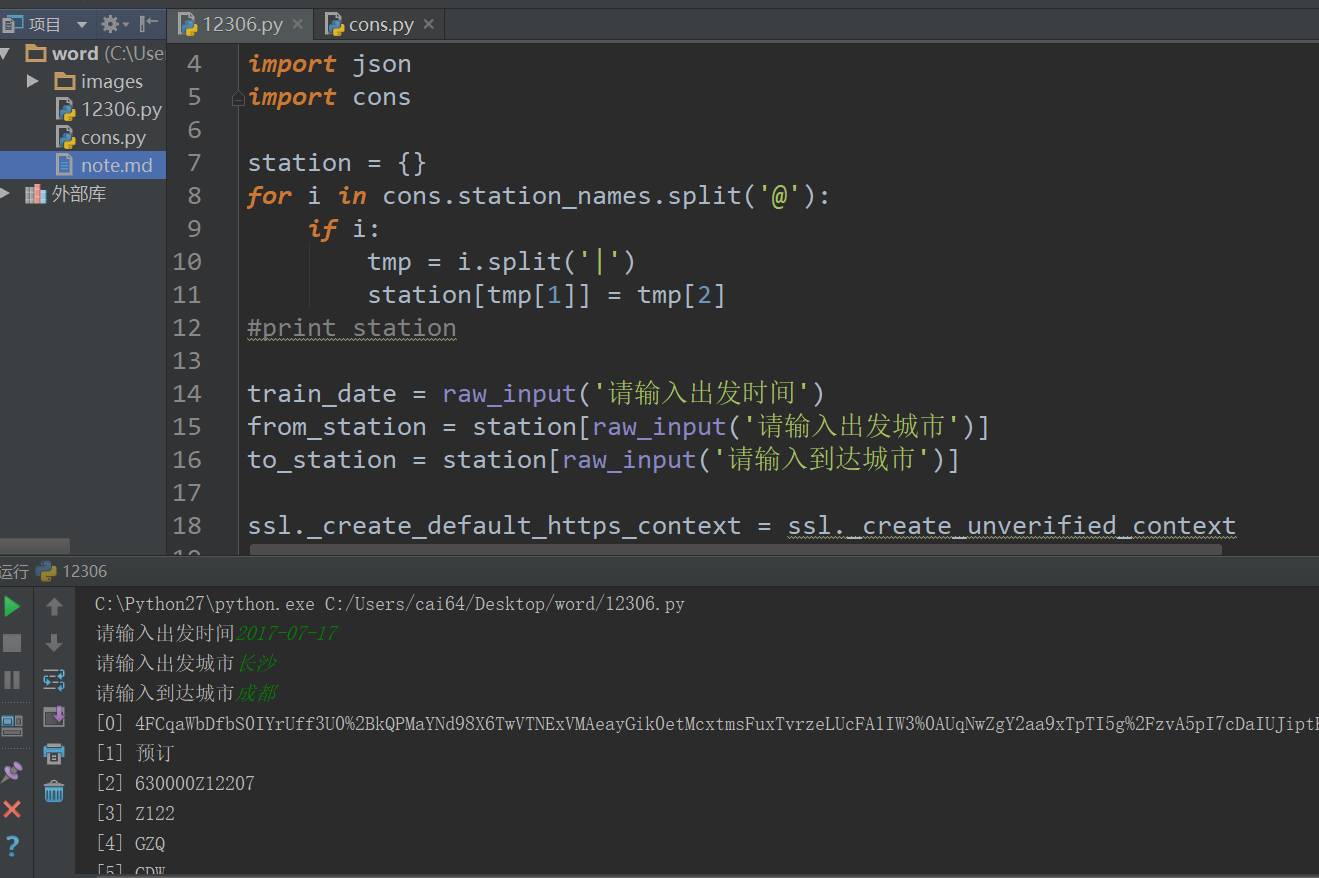
那么我们再进行一些简单的判断,就能实现检查相应的时间,地点,车次是否有余票了。
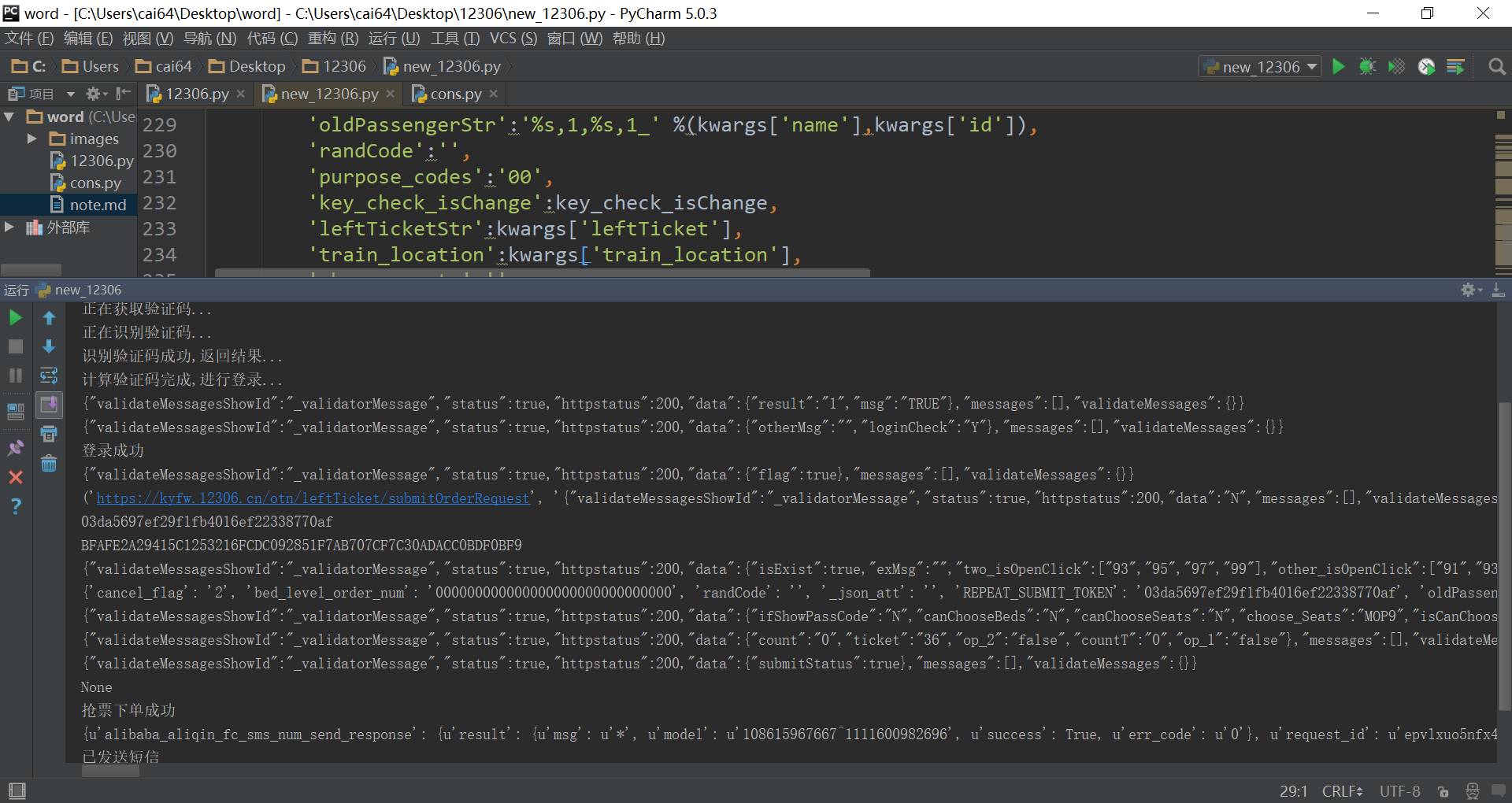
同时再结合登录,购票等流程,通过自动判断是否有票,如果无票就继续刷新,直到有票之后自动登录下单后通过短信或者电话等方式全自动联系购票人手机就可以了,如下图:
利用Python攻破12306的最后一道防线的更多相关文章
- 利用Python实现12306爬虫--查票
在上一篇文章(http://www.cnblogs.com/fangtaoa/p/8321449.html)中,我们实现了12306爬虫的登录功能,接下来,我们就来实现查票的功能. 其实实现查票的功能 ...
- 网页入侵最后一道防线:CSP内容安全策略
首先,什么是最后一道防线?网页入侵都有一个过程,简单来说,就是1.代码注入,2.代码执行. 对于黑客来说,代码注入后并不代表就万事大吉了,因为此时代码只是安静地躺在受害者的服务器里,什么坏事都没干呢! ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
随机推荐
- js 稍微判断下浏览器 pc 还是手机
function isMobile() { var a=navigator.userAgent; var ref=/.*(Android|iPhone|SymbianOS|iPad| ...
- Jquery的window.onload实现
我们都知道jquery的$(document).ready(function(){});与window.onload不同,第一个是在DOM树构建完成后触发,第二个是页面完全加载后(包括图片等资源的加载 ...
- Flutter - 自动生成Android & iOS图标
对于要发布的app来说,做图标是一个麻烦的事,你需要知道N个图标的分辨率,然后用PhotoShop一个个修改导出. PS好图标之后,按照各自的位置放进去. ********************** ...
- db2修改最大连接数
查看当前连接数,sample为数据库名db2 list applications for db sample db2 list applications for db sample show deta ...
- JavaScript术语:shim 和 polyfill
转自:https://www.html.cn/archives/8339 在学习和使用 JavaScript 的时候,我们会经常碰到两个术语:shim 和 polyfill.它们有许多定义和解释,意思 ...
- BugPhobia团队篇章:团队管理与Github源代码管理说明
0x00:序言 To the searching tags, you may well fall in love withhttp://xueba.nlsde.buaa.edu.cn/ 再见,无忧时光 ...
- Java实验报告一:Java开发环境的熟悉
实验要求: 1. 使用JDK编译.运行简单的Java程序 2.使用Eclipse 编辑.编译.运行.调试Java程序 实验内容 (一) 命令行下Java程序开发 (二)Eclipse下Java程序 ...
- Linux内核第四节 20135332武西垚
实验目的: 使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用 实验过程: 查看系统调用列表 get pid 函数 #include <stdio.h> #include & ...
- MyBatis 返回类型resultType为map时的null值不返回问题
问题一: 查询结果集中 某字段 的值为null,在map中不包含该字段的key-value对 解决:在mybatis.xml中添加setting参数 <!-- 在null时也调用 sett ...
- Apache+php安装和配置 windows
Apache+php安装和配置 windows Apache 安装 1.官网网址:http://httpd.apache.org/ 2.Download 3.点击链接Files for Microso ...