sqlAlchemy学习 001
研究学习主题
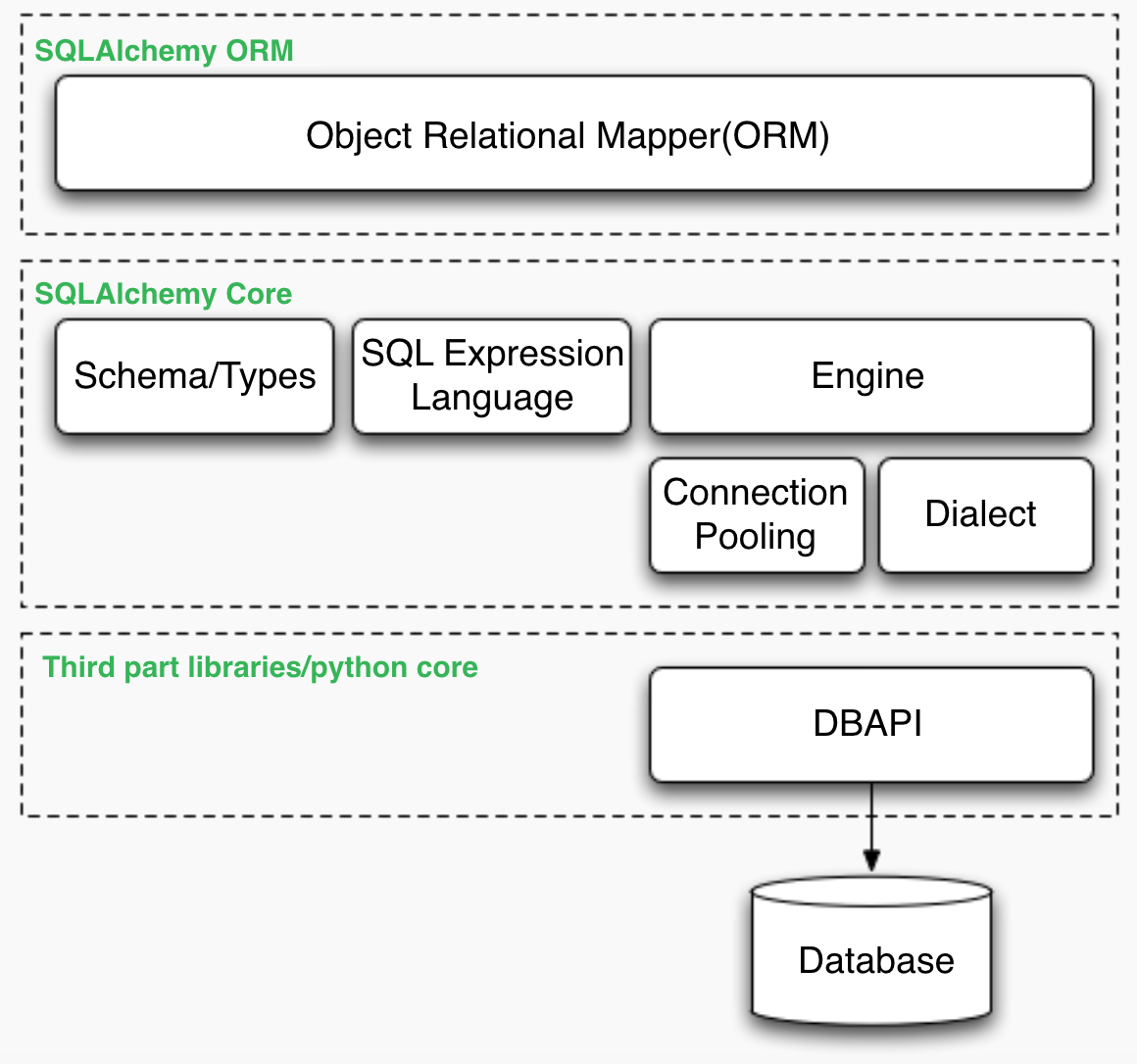
sqlAlchemy架构图
测试练习代码编写
连接数据库
看代码
db_config = {
'host': 'xxx.xxx.xxx.xx',
'user': 'root',
'passwd': 'xxxxxxxx',
'db': 'test',
'charset': 'utf8'
}
engine = create_engine('mysql://%s:%s@%s/%s?charset=%s' % (db_config['user'],
db_config['passwd'],
db_config['host'],
db_config['db'],
db_config['charset']), echo=True)
创建查询
分页
# start from 0 and get 10
searchResult = self.db.query(User).join(UserInfo, User.uid == UserInfo.uid).\
filter(UserInfo.income > 5000).offset(0).limit(10)
filter中实现isnull(id,0)=0
这个的办法就是用 or_ 函数, 同时实现了result转json
SysNote = self.db.query(Note.note_id.label('msg_id'), Note.content).filter(Note.deleted == 0).\
outerjoin(NoteBox, Note.note_id == NoteBox.note_id).\
filter(or_(NoteBox.nb_id == None, NoteBox.deleted == 0)).\
filter(or_(NoteBox.nb_id == None, NoteBox.uid == self.uid))
msgs = []
# print(dir(SysNote), ...)
for msg in SysNote:
row = {}
# msg is tuple
for field in msg._fields:
row[field] = eval('msg.'+field) #dynamicly get the field value
msgs.append(row)
SysNote = json.dumps(msgs, check_circular=False)
return JsonResponse(self, 50000, msg='Success', data=msgs)
排除Noe值
#方法一
session.query(employee).filter_by(employ.brand_id.isnot(None))
#方法二
from sqlalchemy import not_
session.query(employee).filter_by(not_(employ.brand_id==None))
列别名
users = session.query(User.name.label("user_name")) # 结果集的列取别名
for user in users:
print("label test:", user.user_name) # 这里使用别名
join使用
sqlalchemy各个模块主要功能了解
1. 在sqlalchemy.schema包里有数据库关系的描述,列举几个最常用的:
字段:Column
索引:Index
表:Table
1. 数据类型在sqlalchemy.types包,列举几个最常用的:
二进制:BIGINT
布尔:BOOLEAN
字符:CHAR
可变字符:VARCHAR
日期:DATETIME
1. 操作方法在sqlalchemy.sql包里,列举几个最常用的:
execute,update,insert,select,delete,join等
执行原生SQL,格式化参数
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql://user:passwd@ip:port/db', echo=True)
Session = sessionmaker(bind=engine)
session = Session()
session.execute('show databases')
如何选取指定的列,使用别名
联表统计,聚合函数的使用,sum,rownumber, avg
如何使用group by, having
创建表结构
创建名为users的表,有四个字段:id,name,fullname,password.
String在mysql里其实就是varchar
metadata = MetaData()
users_table = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(100))
)
metadata.create_all(engine)
从数据表获取映射对象
看到这里我们没有使用Model对象
from sqlalchemy.orm import mapper
metadata = MetaData(engine)
users_table = Table('users', metadata, autoload=True)
print users_table.columns
# 利用映射对象执行数据插入和显示
insert = users_table.insert()
insert.execute(name='leon', fullname='leon liang', password='leon123')
mapper(User, users_table)
ed_user=User('crackpot','Crackpot','password')
print 'username:', ed_user.name
print 'fullname:', ed_user.fullname
print 'password:', ed_user.password
print 'id:', str(ed_user.id)
ORM操作
单表操作
#coding:utf8
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
print(sqlalchemy.__version__)
engine = create_engine('sqlite:///dbyuan1.db', echo=True)
Base = declarative_base()#生成一个SQLORM基类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
password = Column(String)
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)
Base.metadata.create_all(engine) #创建所有表结构
ed_user = User(name='xiaoyu', fullname='Xiaoyu Liu', password='123')
print(ed_user)
#这两行触发sessionmaker类下的__call__方法,return得到 Session实例,赋给变量session,所以session可以调用Session类下的add,add_all等方法
MySession = sessionmaker(bind=engine)
session = MySession()
session.add(ed_user)
# our_user = session.query(User).filter_by(name='ed').first()
# SELECT * FROM users WHERE name="ed" LIMIT 1;
# session.add_all([
# User(name='alex', fullname='Alex Li', password='456'),
# User(name='alex', fullname='Alex old', password='789'),
# User(name='peiqi', fullname='Peiqi Wu', password='sxsxsx')])
session.commit()
#print(">>>",session.query(User).filter_by(name='ed').first())
#print(session.query(User).all())
# for row in session.query(User).order_by(User.id):
# print(row)
# for row in session.query(User).filter(User.name.in_(['alex', 'wendy', 'jack'])):#这里的名字是完全匹配
# print(row)
# for row in session.query(User).filter(~User.name.in_(['ed', 'wendy', 'jack'])):
# print(row)
#print(session.query(User).filter(User.name == 'ed').count())
#from sqlalchemy import and_, or_
# for row in session.query(User).filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')):
# print(row)
# for row in session.query(User).filter(or_(User.name == 'ed', User.name == 'wendy')):
# print(row)
一对多关联操作
http://www.cnblogs.com/yuanchenqi/articles/5638282.html
#coding:utf8
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
print(sqlalchemy.__version__)
engine = create_engine('sqlite:///dbyuan1.db', echo=True)
Base = declarative_base()#生成一个SQLORM基类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
password = Column(String)
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)
Base.metadata.create_all(engine) #创建所有表结构
ed_user = User(name='xiaoyu', fullname='Xiaoyu Liu', password='123')
print(ed_user)
#这两行触发sessionmaker类下的__call__方法,return得到 Session实例,赋给变量session,所以session可以调用Session类下的add,add_all等方法
MySession = sessionmaker(bind=engine)
session = MySession()
session.add(ed_user)
# our_user = session.query(User).filter_by(name='ed').first()
# SELECT * FROM users WHERE name="ed" LIMIT 1;
# session.add_all([
# User(name='alex', fullname='Alex Li', password='456'),
# User(name='alex', fullname='Alex old', password='789'),
# User(name='peiqi', fullname='Peiqi Wu', password='sxsxsx')])
session.commit()
#print(">>>",session.query(User).filter_by(name='ed').first())
#print(session.query(User).all())
# for row in session.query(User).order_by(User.id):
# print(row)
# for row in session.query(User).filter(User.name.in_(['alex', 'wendy', 'jack'])):#这里的名字是完全匹配
# print(row)
# for row in session.query(User).filter(~User.name.in_(['ed', 'wendy', 'jack'])):
# print(row)
#print(session.query(User).filter(User.name == 'ed').count())
#from sqlalchemy import and_, or_
# for row in session.query(User).filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')):
# print(row)
# for row in session.query(User).filter(or_(User.name == 'ed', User.name == 'wendy')):
# print(row)
#coding:utf8
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
print(sqlalchemy.__version__)
engine = create_engine('sqlite:///dbyuan1.db', echo=True)
Base = declarative_base()#生成一个SQLORM基类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
password = Column(String)
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)
Base.metadata.create_all(engine) #创建所有表结构
ed_user = User(name='xiaoyu', fullname='Xiaoyu Liu', password='123')
print(ed_user)
#这两行触发sessionmaker类下的__call__方法,return得到 Session实例,赋给变量session,所以session可以调用Session类下的add,add_all等方法
MySession = sessionmaker(bind=engine)
session = MySession()
session.add(ed_user)
# our_user = session.query(User).filter_by(name='ed').first()
# SELECT * FROM users WHERE name="ed" LIMIT 1;
# 批量插入
# session.add_all([
# User(name='alex', fullname='Alex Li', password='456'),
# User(name='alex', fullname='Alex old', password='789'),
# User(name='peiqi', fullname='Peiqi Wu', password='sxsxsx')])
session.commit()
#print(">>>",session.query(User).filter_by(name='ed').first())
#print(session.query(User).all())
# for row in session.query(User).order_by(User.id):
# print(row)
# for row in session.query(User).filter(User.name.in_(['alex', 'wendy', 'jack'])):#这里的名字是完全匹配
# print(row)
# for row in session.query(User).filter(~User.name.in_(['ed', 'wendy', 'jack'])):
# print(row)
#print(session.query(User).filter(User.name == 'ed').count())
#from sqlalchemy import and_, or_
# for row in session.query(User).filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')):
# print(row)
# for row in session.query(User).filter(or_(User.name == 'ed', User.name == 'wendy')):
# print(row)
ORM查询
http://www.cnblogs.com/aylin/p/5770888.html
#limit索引取出第一二行数据
session.query(Person).all()[1:3]
#order by,按照id从大到小排列
session.query(Person).ordre_by(Person.id)
#equal/like/in
query = session.query(Person)
query.filter(Person.id==1).all()
query.filter(Person.id!=1).all()
query.filter(Person.name.like('%ay%')).all()
query.filter(Person.id.in_([1,2,3])).all()
query.filter(~Person.id.in_([1,2,3])).all()
query.filter(Person.name==None).all()
#and or
from sqlalchemy import and_
from sqlalchemy import or_
query.filter(and_(Person.id==1, Person.name=='张岩林')).all()
query.filter(Person.id==1, Person.name=='张岩林').all()
query.filter(Person.id==1).filter(Person.name=='张岩林').all()
query.filter(or_(Person.id==1, Person.id==2)).all()
# count计算个数
session.query(Person).count()
# 修改update
session.query(Person).filter(id > 2).update({'name' : '张岩林'})
# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
ret = session.query(Person).join(Favor).all()
ret = session.query(Person).join(Favor, isouter=True).all()
# 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
relationship和join使用
转载自:http://www.cnblogs.com/coder2012/p/4746941.html
- relationship
#!/usr/bin/env python
# encoding: utf-8
from sqlalchemy import create_engine
from sqlalchemy import Column
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy import ForeignKey
from sqlalchemy.orm import backref
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import relationship, backref
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(32))
addresses = relationship("Address", order_by="Address.id", backref="user")
class Address(Base):
__tablename__ = 'addresses'
id = Column(Integer, primary_key=True)
email_address = Column(String(32), nullable=False)
user_id = Column(Integer, ForeignKey('users.id'))
#user = relationship("User", backref=backref('addresses', order_by=id))
engine = create_engine('mysql://root:root@localhost:3306/test', echo=True)
#Base.metadata.create_all(engine)
jack = User(name='jack')
jack.addresses = [Address(email_address='test@test.com'), Address(email_address='test1@test1.com')]
session.add(jack)
session.commit()
join
不使用join可以直接联表查询
session.query(User.name, Address.email_address).\
filter(User.id == Address.user_id).\
filter(Address.email_address == 'test@test.com').all()
# SELECT users.name AS users_name, addresses.email_address AS addresses_email_address
# FROM users, addresses
# WHERE users.id = addresses.user_id AND addresses.email_address = %s
# [('jack', 'test@test.com')]
在sqlalchemy中提供了Queqy.join()函数
# 有外键
session.query(User).join(Address).filter(Address.email_address=='test@test.com').first()
session.query(User).join(Address).filter(Address.email_address=='test@test.com').first().name
session.query(User).join(Address).filter(Address.email_address=='test@test.com').first().addresses
# 无外键
query.join(Address, User.id==Address.user_id) # explicit condition
query.join(User.addresses) # specify relationship from left to right
query.join(Address, User.addresses) # same, with explicit target
query.join('addresses')
表的别名
from sqlalchemy.orm import aliased
adalias1 = aliased(Address)
子查询
例如我们需要如下的查询
SELECT users.*, adr_count.address_count
FROM users
LEFT JOIN
(SELECT user_id, count(*) AS address_count
FROM addresses
GROUP BY user_id
) AS adr_count ON users.id=adr_count.user_id;
# 生成子句,等同于(select user_id ... group_by user_id)
sbq = session.query(Address.user_id, func.count('*').label('address_count')).\
group_by(Address.user_id).subquery()
# 联接子句,注意子句中需要使用c来调用字段内容
session.query(User.name, sbq.c.address_count).\
outerjoin(sbq, User.id == sbq.c.user_id).all()
包含contains
query.filter(User.addresses.contains(someaddress))
sqlalchemy(一)基本操作 TODO
http://www.cnblogs.com/coder2012/p/4741081.html
#获取所有数据
session.query(Person).all()
#获取某一列数据,类似于django的get,如果返回数据为多个则报错
session.query(Person).filter(Person.name=='jack').one()
#获取返回数据的第一行
session.query(Person).first()
#过滤数据
session.query(Person.name).filter(Person.id>1).all()
#limit
session.query(Person).all()[1:3]
#order by
session.query(Person).ordre_by(-Person.id)
#equal/like/in
query = session.query(Person)
query.filter(Person.id==1).all()
query.filter(Person.id!=1).all()
query.filter(Person.name.like('%ac%')).all()
query.filter(Person.id.in_([1,2,3])).all()
query.filter(~Person.id.in_([1,2,3])).all()
query.filter(Person.name==None).all()
#and or
from sqlalchemy import and_
query.filter(and_(Person.id==1, Person.name=='jack')).all()
query.filter(Person.id==1, Person.name=='jack').all()
query.filter(Person.id==1).filter(Person.name=='jack').all()
from sqlalchemy import or_
query.filter(or_(Person.id==1, Person.id==2)).all()
# 使用text
from sqlalchemy import text
query.filter(text("id>1")).all()
query.filter(Person.id>1).all() #同上
query.filter(text("id>:id")).params(id=1).all() #使用:,params来传参
query.from_statement(
text("select * from person where name=:name")).\
params(name='jack').all()
#计数 count
query.filter(Person.id>1).count()
session.query(func.count('*')).select_from(Person).scalar()
session.query(func.count(Person.id)).scalar()
Query
resultProxy=db.execute("select * from users")
resultProxy.close(), resultProxy 用完之后, 需要close
resultProxy.scalar(), 可以返回一个标量查询的值
ResultProxy 类是对Cursor类的封装(在文件sqlalchemy\engine\base.py),
ResultProxy 类有个属性cursor即对应着原来的cursor.
ResultProxy 类有很多方法对应着Cursor类的方法, 另外有扩展了一些属性/方法.
resultProxy.fetchall()
resultProxy.fetchmany()
resultProxy.fetchone()
resultProxy.first()
resultProxy.scalar()
resultProxy.returns_rows #True if this ResultProxy returns rows.
resultProxy.rowcount #return rows affected by an UPDATE or DELETE statement. It is not intended to provide the number of rows present from a SELECT.
**遍历ResultProxy时, 得到的每一个行都是RowProxy对象, 获取字段的方法非常灵活, 下标和字段名甚至属性都行. rowproxy[0] == rowproxy['id'] == rowproxy.id, 看得出 RowProxy 已经具备基本 POJO 类特性. **
http://blog.csdn.net/mmx/article/details/48064109
delete and remove
session.delete(jack)
session.query(User).filter_by(name='jack').count()
session.query(User).filter_by(name='jack').remove()
session.commit()
sqlAlchemy学习 001的更多相关文章
- SQLAlchemy 学习笔记(二):ORM
照例先看层次图 一.声明映射关系 使用 ORM 时,我们首先需要定义要操作的表(通过 Table),然后再定义该表对应的 Python class,并声明两者之间的映射关系(通过 Mapper). 方 ...
- SQLAlchemy 学习笔记(一):Engine 与 SQL 表达式语言
个人笔记,如有错误烦请指正. SQLAlchemy 是一个用 Python 实现的 ORM (Object Relational Mapping)框架,它由多个组件构成,这些组件可以单独使用,也能独立 ...
- sqlalchemy学习
sqlalchemy官网API参考 原文作为一个Pythoner,不会SQLAlchemy都不好意思跟同行打招呼! #作者:笑虎 #链接:https://zhuanlan.zhihu.com/p/23 ...
- Python之SQLAlchemy学习
alchemy 英[ˈælkəmi] 美[ˈælkəmi] n. 炼金术; 炼丹术; (改变事物.物质的)魔力(或方法) ; (事物.物质的) 神秘变化; SQLAlchemy是Python中最有名的 ...
- JVM学习001通过实例总结Java虚拟机的运行机制
JVM学习(1)——通过实例总结Java虚拟机的运行机制-转载http://www.cnblogs.com/kubixuesheng/p/5199200.html 文章转载自:http://www.c ...
- 从0开始的Python学习001快速上手手册
假设大家已经安装好python的环境了. Windows检查是否可以运行python脚本 Ctrl+R 输入 cmd 在命令行中输入python 如果出现下面结果,我们就可以开始python的学习了. ...
- tensorflow学习001——MNIST
1.MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片 数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test). 这样的 ...
- sqlalchemy学习-- 重要参数
Base = declarative_base 基类: 1.存储表 2.建立class-Table 的映射关系 engine = create_engine('mysql://root:root@lo ...
- sqlalchemy 学习--单表操作
以下所有代码片段都使用了统一的引用,该引用如下: from sqlalchemy import create_engine, ForeignKey from sqlalchemy.ext.declar ...
随机推荐
- 架构:Hexagonal Architecture Guidelines for Rails(转载)
原文地址:http://theaudaciouscodeexperiment.com/blog/2014/03/17/hexagonal-architecture-guidelines-for-rai ...
- JAVA中对List<map<String,Object>>根据map某个key值进行排序
方法compareTo()比较此对象与指定对象的顺序.如果该对象小于.等于或大于指定对象,则分别返回负整数.零或正整数.返回整数,1,-1,0:返回1表示大于,返回-1表示小于,返回0表示相等. 普通 ...
- 多线程-Executors和Executor,线程池
jdk1.5之前,所有的线程都是需要自己手动创建的,由jvm销毁,当请求过多的时候,频繁的创建和销毁线程是非常浪费资源的.jdk1.5为此做了优化,提供了 java.util.concurrent 包 ...
- Docker 常用命令与操作
介绍 此命令集合版本为 1.11.1 及以上 基础类 查看docker信息 # 查看docker版本 docker version # 显示docker系统的信息 docker info # 日志信息 ...
- QT中文乱码与国际化支持
QT国际化支持 Qt内部采用的全Unicode编码,这从根本上保证了多国语界面实现的正确性和便捷性.Qt本身提供的linguist工具,用来实现翻译过程十分方便.MFC中利用资源DLL切换资源,或 ...
- C# xml 常规 保护 方法总结
一 使用xsd模式文件验证xml文件: xml文件: <?xml version="1.0" encoding="utf-8" ?> <Boo ...
- [leetcode]Gas Station @ Python
原题地址:https://oj.leetcode.com/problems/gas-station/ 题意: There are N gas stations along a circular rou ...
- springboot的Web开发-Web相关配置
一:Spring Boot提供自动配置 通过查看WebMvcAutoConfiguration及WebMvcProperties的源码,可以发现Spring Boot为我们提供了如下的自动配置. 1, ...
- MFC中卡拉OK字体的定时器实现,使用DC的DrawText函数实现
void CTextView::OnTimer(UINT_PTR nIDEvent) { m_nWidth += ; // 在构造函数中初始化为 0: CClientDC dc( this ); TE ...
- 教程 | Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
https://mp.weixin.qq.com/s/JwRXBNmXBaQM2GK6BDRqMw 选自GitHub 作者:Artur Suilin 机器之心编译 参与:蒋思源.路雪.黄小天 近日,A ...