【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)
参考:
cs229讲义
机器学习(一):生成学习算法Generative Learning algorithms:http://www.cnblogs.com/zjgtan/archive/2013/06/08/3127490.html
首先,简单比较一下前几节课讲的判别学习算法(Discriminative Learning Algorithm)和本节课讲的生成学习算法(Generative Learning Algorithm)的区别。
eg:问题:Consider a classification problem in which we want to learn to distinguishbetween elephants (y = 1) and dogs (y = 0), based on some features of
an animal.
判别学习算法:(DLA通过建立输入空间X与输出标注{1, 0}间的映射关系学习得到p(y|x))
Given a training set, an algorithm like logistic regression or the perceptron algorithm (basically) tries to find a straight line—that is, a decision boundary—that separates the elephants and dogs. Then, to classify a new animal as either an elephant or a dog, it checks on which side of the decision boundary it falls, and makes its prediction accordingly.
生成学习算法:(GLA首先确定p(x|y)和p(y),由贝叶斯准则得到后验分布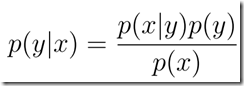 ,通过最大后验准则进行预测,
,通过最大后验准则进行预测,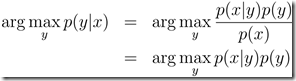 )
)
First, looking at elephants, we can build a model of what elephants look like. Then, looking at dogs, we can build a separate model of what dogs look like. Finally, to classify a new animal, we can match the new animal against the elephant model, and match it against the dog model, to see whether the new animal looks more like the elephants or more like the dogs we had seen in the training set.
(ps:先验概率 vs 后验概率
事情还没有发生,要求这件事情发生的可能性的大小,是
先验概率
.
事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是
后验概率
.
)
生成学习算法
首先,温习一下高斯分布的相关知识:
高斯分布 Gaussian distribution
高斯分布也就是正态分布; 数学期望为 , 方差为
, 方差为 的高斯分布通常记为
的高斯分布通常记为 .
.
标准正态分布 Standard normal distribution
标准正态分布是指数学期望为 , 方差为
, 方差为 的正态分布, 记为
的正态分布, 记为 . 对于数学期望为, 方差为的正态分布随机变量
. 对于数学期望为, 方差为的正态分布随机变量 , 通过下列线性变换
, 通过下列线性变换 可以得到服从标准正态分布的随机变量
可以得到服从标准正态分布的随机变量 .
.
二元正态分布 Bivariate normal distribution
二元正态分布[]是指两个服从正态分布的随机变量具有的联合概率分布. 二元正态分布的联合概率密度函数为

其中

 ,
,  ,
,  ,
,  ,
,  为概率分布的参数. 上述二元正态分布记为
为概率分布的参数. 上述二元正态分布记为 .
.
二元正态分布的特征函数为

多元正态分布 Multivariate normal distribution
多元正态分布是指多个服从正态分布的随机变量组成的随机向量具有的联合概率分布. 数学期望为 和协方差矩阵为
和协方差矩阵为 的
的 个随机变量
个随机变量 的多元正态分布
的多元正态分布 的联合概率密度函数为
的联合概率密度函数为

 服从多元正态分布可以记为
服从多元正态分布可以记为 .
.
如果, 并且 , 那么
, 那么 .
.
可以看到,多元正态分布与两个量相关:均值和协方差矩阵。因此,接下来,通过图像观察一下改变这两个量的值,所引起的变化。
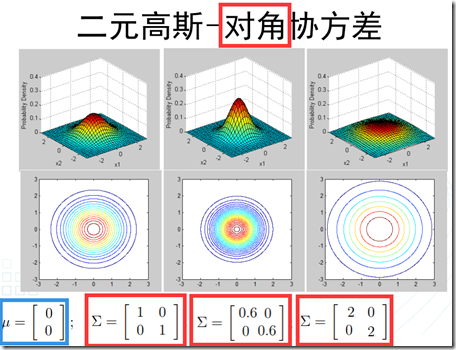
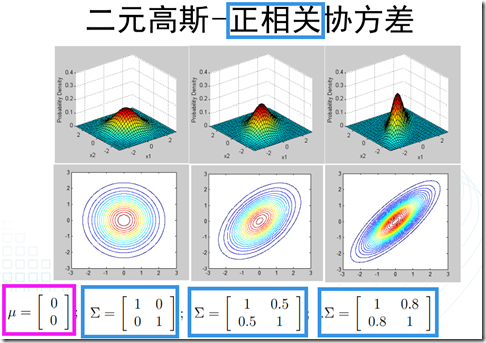
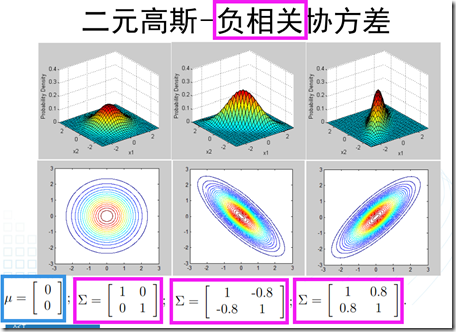
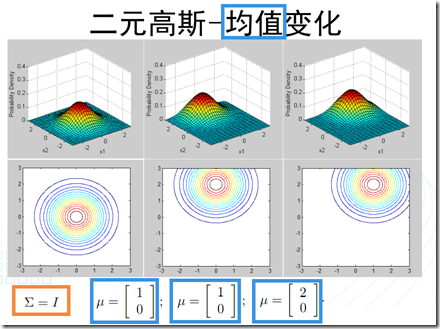
- 1、高斯判别分析(GDA,Gaussian Discriminant Analysis):
a、提出假设遵循正态分布:
In this model, we’ll assume that p(x|y) is distributed according to a multivariate normal distribution(多元正态分布).

b、分别对征服样本进行拟合,得出相应的模型
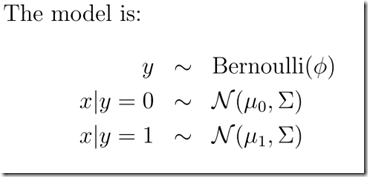


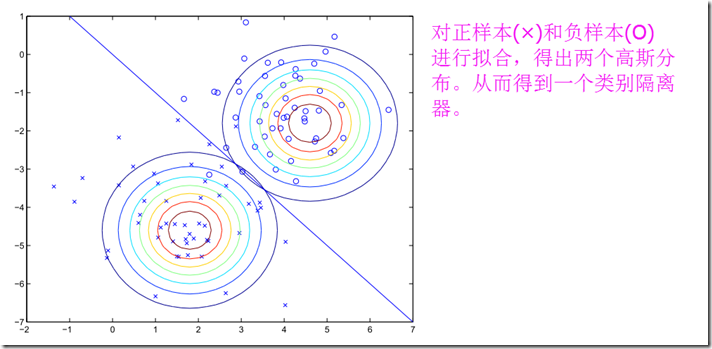
最后,比较一下GDA和Logistic回归
GDA——如果确实符合实际数据,则只需要少量的样本就可以得到较好的模型

Logistic Regression——Logistic回归模型有更好的鲁棒性

总结:
GDA makes stronger modeling assumptions, and is more data efficient (i.e., requires less training data to learn “well”) when the modeling assumptions are correct or at least approximately correct.
Logistic regression makes weaker assumptions, and is significantly more robust to deviations from modeling assumptions.
Specifically, when the data is indeed non-Gaussian, then in the limit of large datasets, logistic regression will almost always do better than GDA. For this reason, in practice logistic regression is used more often than GDA. (Some related considerations about discriminative vs. generative models also apply for the Naive Bayes algorithm that we discuss next, but the Naive Bayes algorithm is still considered a very good, and is certainly also a very popular, classification algorithm.)
2、朴素贝叶斯(NB,Naive Bayes):
以文本分类为例,基于条件独立的假设。在实际语法上,有些单词之间是存在一定联系的,尽管如此,朴素贝叶斯还是表现出了非常好的性能。
因为独立,所以
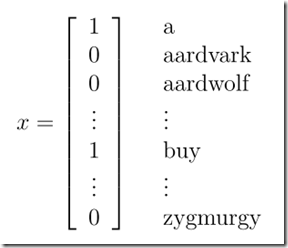
得到联合似然函数Joint Likelihood:
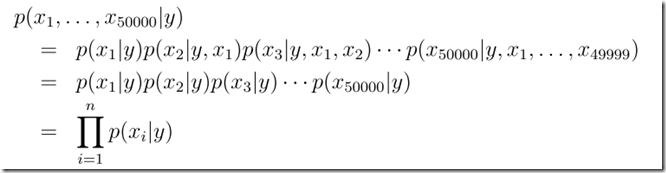
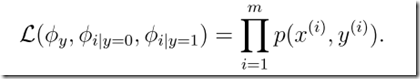

得到这些参数的估计值之后,给你一封新的邮件,可以根据贝叶斯公式,计算
(可以参阅我的另一篇实战随笔:http://www.cnblogs.com/XBWer/p/3840736.html)

Laplace smoothing(Laplace 平滑)
当邮件中遇到新词,(0/0)本质是输入样本特征空间维数的提升,旧的模型无法提供有效分类信息。
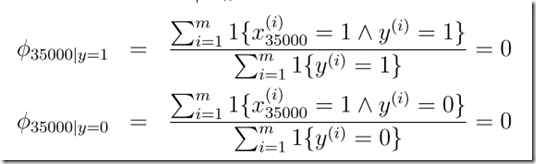
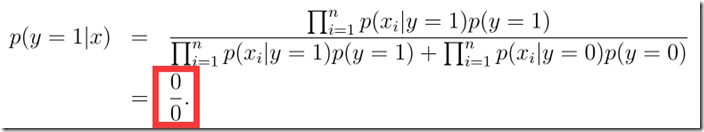
遇到这种情况时,可以进行平滑处理:(+1)
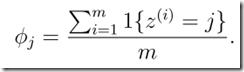 ==============>
==============>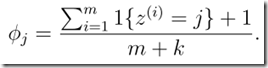
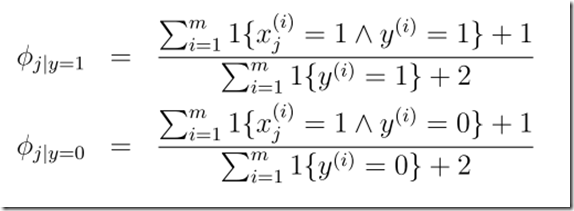
【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)的更多相关文章
- [置顶] 生成学习算法、高斯判别分析、朴素贝叶斯、Laplace平滑——斯坦福ML公开课笔记5
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9285001 该系列笔记1-5pdf下载请猛击这里. 本篇博客为斯坦福ML公开 ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 机器学习理论基础学习3.5--- Linear classification 线性分类之朴素贝叶斯
一.什么是朴素贝叶斯? (1)思想:朴素贝叶斯假设 条件独立性假设:假设在给定label y的条件下,特征之间是独立的 最简单的概率图模型 解释: (2)重点注意:朴素贝叶斯 拉普拉斯平滑 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- CS229 Lesson 5 生成学习算法
课程视频地址:http://open.163.com/special/opencourse/machinelearning.html 课程主页:http://cs229.stanford.edu/ 更 ...
- CS229笔记:生成学习算法
在线性回归.逻辑回归.softmax回归中,学习的结果是\(p(y|x;\theta)\),也就是给定\(x\)的条件下,\(y\)的条件概率分布,给定一个新的输入\(x\),我们求出不同输出的概率, ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- 3.朴素贝叶斯和KNN算法的推导和python实现
前面一个博客我们用Scikit-Learn实现了中文文本分类的全过程,这篇博客,着重分析项目最核心的部分分类算法:朴素贝叶斯算法以及KNN算法的基本原理和简单python实现. 3.1 贝叶斯公式的推 ...
- 朴素贝叶斯算法java实现(多项式模型)
网上有很多对朴素贝叶斯算法的说明的文章,在对算法实现前,参考了一下几篇文章: NLP系列(2)_用朴素贝叶斯进行文本分类(上) NLP系列(3)_用朴素贝叶斯进行文本分类(下) 带你搞懂朴素贝叶斯分类 ...
随机推荐
- Python——signal
该模块为在Python中使用信号处理句柄提供支持.下面是一些使用信号和他们的句柄时需要注意的事项: 除了信号 SIGCHLD 的句柄遵从底层的实现外,专门针对一个信号的句柄一旦设置,除非被明确地重置, ...
- PolymiRTS 数据库- miRNA SNP数据库
背景: miRNA通过和mRNA的3'UTR区结合,导致mRNA讲解或者抑制mRNA翻译,从而实现转录后调控的作用: 如果在miRNA和 mRNA的结合区域,发生了snp,就可能会影响miRNA和mR ...
- iOS:根据系统类型加载不同的xib
1.将 xib 文件名手动更改为 xxx~iphone.xib 和 xxx~ipad.xib 2.初始化时使用 [[xxx alloc] init] 即可,系统会自动判断系统类型并加载对应的 xib ...
- 3.7 su命令 3.8 sudo命令 3.9 限制root远程登录
3.7 su命令 3.8 sudo命令 3.9 限制root远程登录 su命令 切换用户 [root@centos_1 ~]# su - xiaobo [root@centos_1 ~]# su - ...
- Mac或者linux下登陆到linux上的SFTP
登陆 sftp -i 密钥路径 用户@ip ➜ ~ sftp -i Desktop/aliyun.pem root@39.106.30.1 Connected to 39.106.30.1 上 ...
- js scrollIntoViewIfNeeded
根据 MDN的描述,Element.scrollIntoView()方法让当前的元素滚动到浏览器窗口的可视区域内. 而Element.scrollIntoViewIfNeeded()方法也是用来将不在 ...
- java新手的session初体验
众所周知,session作为保存我们用户对话所需要的信息的对象,在我们的项目中必不可少.作为菜鸟学习java的第一课就是了解它的思想和用法,在以后的学习中,逐渐学习和总结,从基础到高级,慢慢学会应用. ...
- [转]jmeter实战
[转]http://blog.csdn.net/ultrani/article/details/8309932 本文主要介绍性能测试中的常用工具jmeter的使用方式,以方便开发人员在自测过程中就能自 ...
- Android布局学习——android:gravity和android:layout_gravity的区别
[Android布局学习系列] 1.Android 布局学习之——Layout(布局)详解一 2.Android 布局学习之——Layout(布局)详解二(常见布局和布局参数) 3.And ...
- Spring Boot 处理 REST API 错误的正确姿势
摘要:如何正确的处理API的返回信息,让返回的错误信息提供更多的含义是一个非常值得做的功能.默认一般返回的都是难以理解的堆栈信息,然而这些信息也许对于API的客户端来说有可能并没有多大用途,并没有多大 ...