Hive入门学习随笔(二)
====使用Load语句执行数据的导入
--将操作系统上的文件student01.txt数据导入到t2表中
load data local inpath '/root/data/student01.txt' into table t2;
--将操作系统上/root/data文件夹下的所有文件导入t3表中,并且覆盖原来的数据
load data local inpath '/root/data/' overwrite into table t3;
--将HDFS中,/input/student01.txt导入到t3表中
load data inpath '/input/student01.txt' overwrite into table t3;
--将操作系统上的data1.txt导入到分区t3表中
load data local inpath 'root/data/data1.txt' into table t3 partition (gender='M')
===使用Sqoop实现数据的导入
Sqoop是一个工具,用来进行Hadoop与关系型数据之间的批量数据的导入和导出。
Sqoop的安装非常简单,只需要从网站上下载Sqoop的安装包,并配置环境变量即可。
环境变量:
由于Sqoop是基于Hadoop的,所以需要通过环境变量HADOOP_COMMON_HOME来指明Hadoop的安装目录。
由于Sqoop是把作业最终转换成MapReduce的作业进行提交执行,所以,需要通过环境变量HADOOP_MAPRED_HOME来指明MapReduce的Jar目录。
--使用Sqoop导入Oracle数据到HDFS中。
./sqoop import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --target-dir '/sqoop/emp'
--使用Sqoop导入Oracle数据到Hive中。
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1
--使用Sqoop导入Oracle数据到Hive中,并且指定表名
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1
--使用Sqoop导入Oracle数据到Hive中,并且制定Where条件
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1 --where 'DEPTNO=10'
--使用Sqoop导入Oracle数据到Hive中,并且使用查询语句
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx --table emp --columns 'empno,ename,job,sal' -m 1 --hive-table emp1 --query 'SELECT * FROM EMP WHERE SAL<2000 $CONDITIONS' --target-dir '/sqoop/emp5' --hive-table emp5
--使用Sqoop将Hive中的数据导出到Oracle中。
./sqoop export --connect jdbc:oracle:thin:@192.168.1.36:1521:orcl --username xxx --password xxx -m 1 --table MYEMP --export-dir HDFS路径
Sqoop在业务系统中有着非常重要的作用,一般的应用场景是下面这个样子。
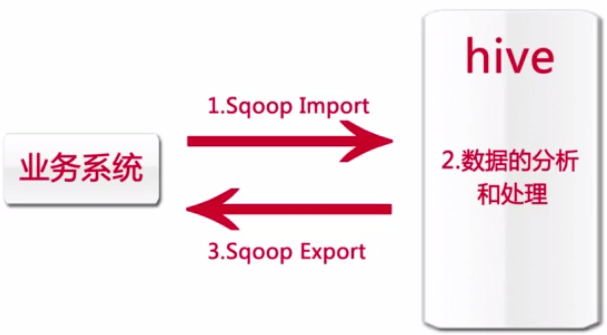
====Hive的数据查询

--查询所有员工的所有信息
select * from emp;
--查询员工信息:员工号 姓名 月薪
select empno, ename, sal from emp;
--查询员工信息:员工号 姓名 月薪 年薪 奖金 年收入
select empno, ename, sal, sal*12 comm, sal*12+nvl(comm, 0) from emp;
--查询奖金为null的员工
select * from emp where comm is null;
--使用distinct来去掉重复记录
select distinct deptno from rmp;
====Hive简单查询的FetchTask功能
从Hive0.10.0版本开始支持。开始了这个功能以后,我们执行一条简单的语句(没有函数、排序等)不会生成一个MapReduce作业。

hive-site.xml配置内容:

====在查询中使用过滤
--查询10号部门的员工
select * from emp where deptno=10;
--查询名称为KING的员工
select * from emp where ename='KING';
--查询部门号是10,薪水小于2000的员工
select * from emp where deptno=10 and sal<2000;
--模糊查询:查询名字以S开头的员工
select empno, ename, sal from emp where ename like 'S%';
--模糊查询:查询名字含有下划线的员工
select empno, ename, sal from emp where ename like '%\\_%';
注意:下划线在模糊查询中有特殊的含义,代表任意字符。所以,语句中需要转义符进行标记
====在查询中使用排序
--查询员工信息:员工号 姓名 月薪 按照月薪排序
select empno, ename, sal from emp order by sal desc;
※order by后面可以使用:列名、表达式、别名、序号。
另外,如果想使用需要进行排序的时候,需要设置下面的环境变量。
set hive.groupby.orderby.position.alias=true;
※null排序:升序时null排最前面,降序时null排最后面,一般用法都是将null转换成0之后进行排序。
====Hive的函数
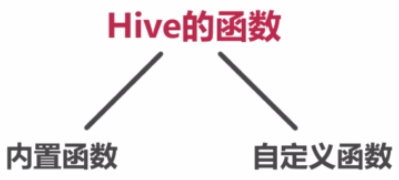
内置函数可以直接调用。也可以通过编写java程序来自定义函数
--内置函数

--自定义函数

①、自定义UDF需要继承org.apache.hadoop.hive.ql.UDF
需要实现evaluate函数,evaluate函数支持重载。
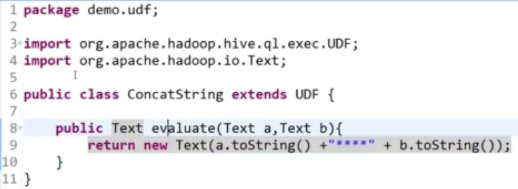
②、将程序打包放到目标机器上去,进入Hive客户端添加jar包
命令例:hive>add jar /root/udfjar/udf_text.jar
③、创建临时函数:CREATE TEMPORARY FUNCTION <函数名> AS 'java类名'
命令例:hive>CREATE TEMPORARY FUNCTION myconcat AS 'demo.udf.ConcatString';
④、自动以函数使用。select <函数名> from table;

⑤、销毁临时函数:DROP TEMPORARY FUNCTION <函数名>
====Hive表连接
Hive的表连接分为:等值连接、不等值连接、外链接、自连接
--等值连接
select e.empno, e.ename, e.sal, d.name from emp e, dept d where e.deptno=d.deptno;
--不等值连接
select e.empno, e.ename, e.sal, s.grade from emp e, salgrade s where e.sal between s.local and s.hisal;
--外链接(包括左连接和右连接)
select d.deptno, d.dname, count(e.empno) from emp e right outer join dept d on (e.deptno=d.deptno) group by d.deptno, d.dname;
--自连接
核心:通过表的别名将同一张表视为多张表
====Hive中的子查询
hive只支持from和where子句中的子查询。
例:select e.ename from emp e where e.deptno in (select d.deptno from dept d where d.dname='SALES' or d.dname='KING');
注意:子查询中的空值:如果子查询返回的结果集中含有空值得话,我们不能使用not in,但是可以使用in。
====Hive的JDBC客户端操作
①、启动Hive远程服务。命令:#hive --service hiveserver
②、JDBC客户端操作
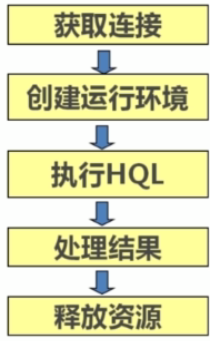
====Hive的Thrift Java客户端操作
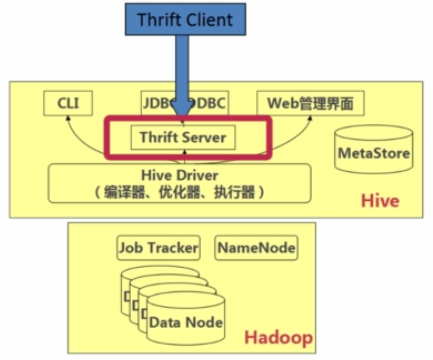
--END--
Hive入门学习随笔(二)的更多相关文章
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- 【转载】salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句 salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex ...
- Hive入门学习--HIve简介
现在想要应聘大数据分析或者数据挖掘岗位,很多都需要会使用Hive,Mapreduce,Hadoop等这些大数据分析技术.为了充实自己就先从简单的Hive开始吧.接下来的几篇文章是记录我如何入门学习Hi ...
- MyBatis入门学习(二)
在MyBatis入门学习(一)中我们完成了对MyBatis简要的介绍以及简单的入门小项目测试,主要完成对一个用户信息的查询.这一节我们主要来简要的介绍MyBatis框架的增删改查操作,加深对该框架的了 ...
- Java Web入门学习(二) Eclipse的配置
Java Web学习(二) Eclipse的配置 一.下载Eclipse 1.进入Eclipse官网,进行下载 上图,下载Eclipse IDE for JaveEE Developers 版本,然后 ...
- Swoole 入门学习(二)
Swoole 入门学习 swoole 之 定时器 循环触发:swoole_timer_tick (和js的setintval类似) 参数1:int $after_time_ms 指定时间[毫秒] ...
- Reactive UI -- 反应式编程UI框架入门学习(二)
前文Reactive UI -- 反应式编程UI框架入门学习(一) 介绍了反应式编程的概念和跨平台ReactiveUI框架的简单应用. 本文通过一个简单的小应用更进一步学习ReactiveUI框架的 ...
- salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex语言和java很多的语法类似,今天总结的是一些简单的Apex的变量等知识. 有如下几种常 ...
- Hibernate入门学习(二)
本文主要讲如何搭建Hibernate开发环境和简单实例. 一.搭建开发测试环境 1.1 下载Hibernate 从Hibernate官方网站上下载最新的Hibernate ORM,从Hibernate ...
随机推荐
- js正则表达式验证大全--转载
转载来源:http://www.cnblogs.com/hai-ping/articles/2997538.html#undefined //判断输入内容是否为空 function IsNull(){ ...
- JDK 8 - Method Reference 分析
Java SE 8 在 Java 语言层面上新增了 lambda expression 的功能,使得 Java 具备了函数式语言的能力 - 可以将函数作为方法参数传递,即 code as data. ...
- WebStorm ES6 语法支持设置
ECMAScript 6是JavaScript语言的下一代标准,已经在2015年6月正式发布了.Mozilla公司将在这个标准的基础上,推出JavaScript 2.0.ES6的目标,是使得JavaS ...
- .NET单点登录实现方法----两种
第一种模式:同一顶级域名下cookie共享,代码如下 HttpCookie cookies = new HttpCookie("Token"); cookies.Expires = ...
- Java程序中不通过hadoop jar的方式访问hdfs
一般情况下,我们使用Java访问hadoop distributed file system(hdfs)使用hadoop的相应api,添加以下的pom.xml依赖(这里以hadoop2.2.0版本 ...
- @BindingAnnotation
(1) 如果 一个接口只有一个实现,使用这种连接注解就可以: bind(XXInterface.class).to(XXImpl.class); @Inject XXInterface xxInter ...
- HTTP请求与响应协议
HTTP(hypertext transport protocol),即超文本传输协议.这个协议详细规定了浏览器和万维网服务器之间互相通信的规则 HTTP就是一个通信规则,通信规则规定了客户端发送给服 ...
- 显示本月日历demo
import java.text.DateFormatSymbols; import java.util.Calendar; import java.util.GregorianCalendar; p ...
- html中的一些常用的样式标签
html中的一些常用的样式标签 <p>这里是文本,<mark>高亮</mark></p> <strong>加粗,加重语气</stron ...
- SVN revert命令的使用
evert命令顾名思义就是对修改过的东西进行回滚操作.一般有2种情况发生时需要用到回滚的操作: 1,修改过的东西没有递交(commit) 这种情况下revert会取消之前的修改 用法:#svn rev ...