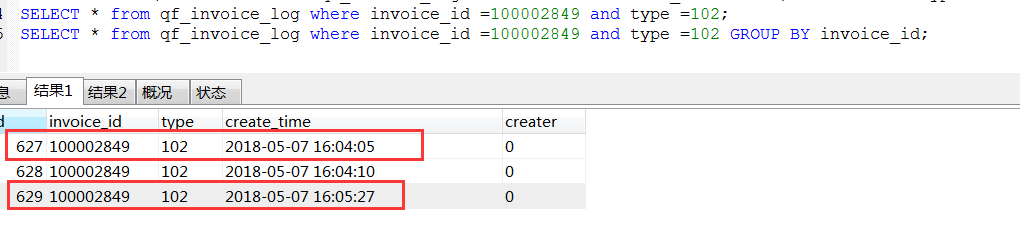
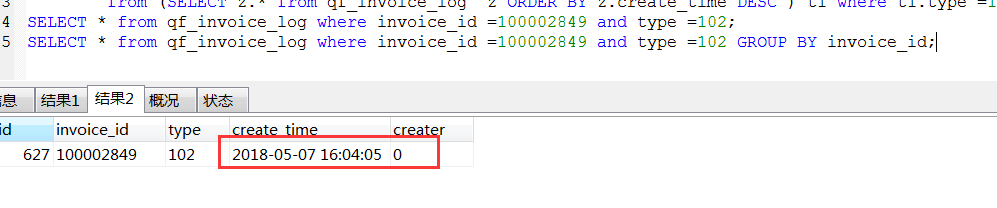
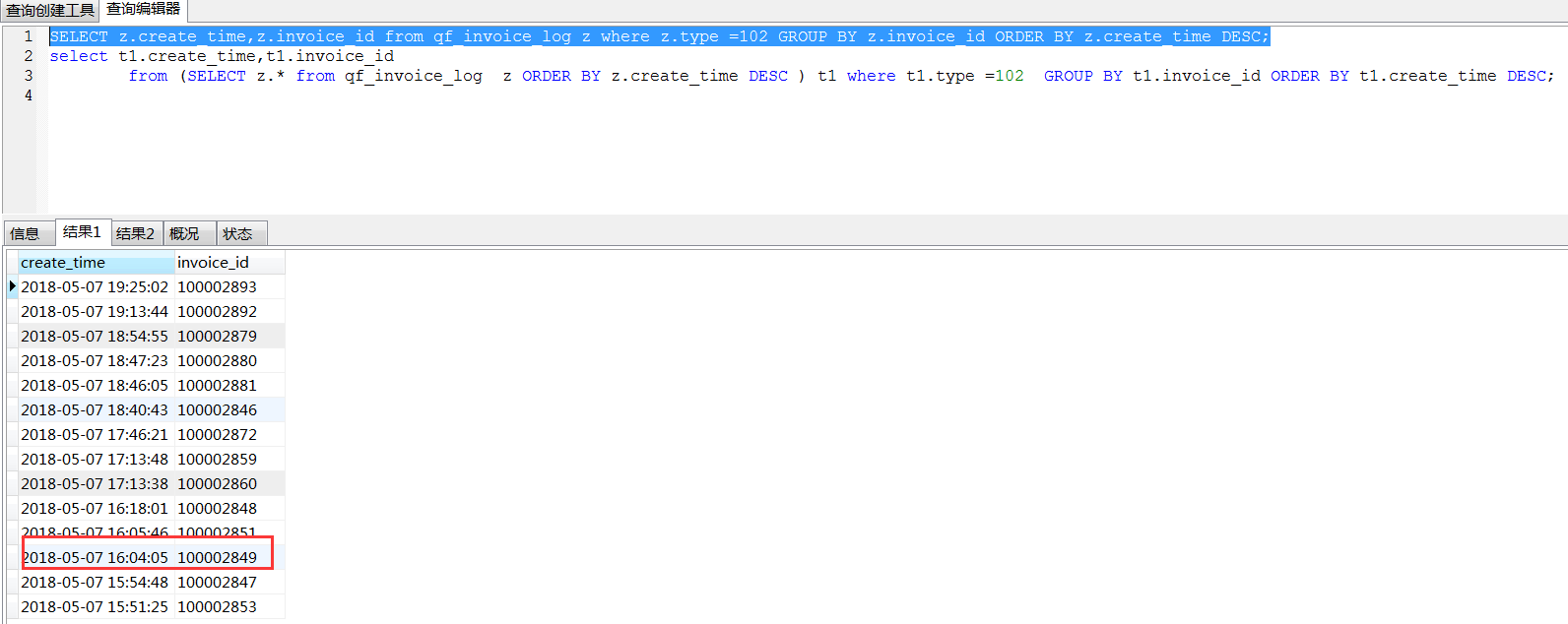
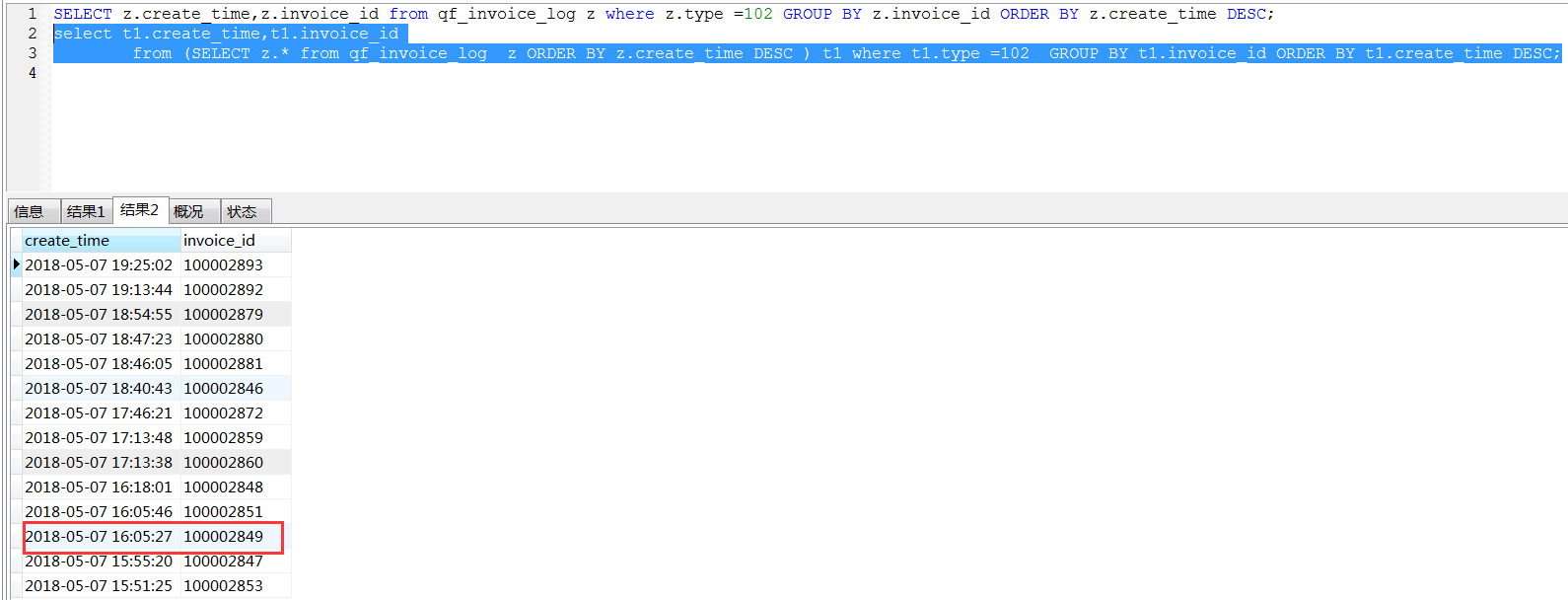
mysql group by组内排序
.png)
.png)
.png)
.png)
mysql group by组内排序的更多相关文章
- mysql group by 组内排序 group by 原理
mysql group by 组内排序 SELECT * FROM (SELECT MAX(id) AS t,wukong_uid, 1 AS tag FROM toutiao_uid_gath ...
- mysql group by 组内排序
有数据表 comments------------------------------------------------| id | newsID | comment | theTime |---- ...
- mysql 不同版本下 group by 组内排序的差异
最近发现网上找的 group by 组内排序语句在不同的mysql版本中结果不一样. 建表语句: SET FOREIGN_KEY_CHECKS=0; -- ---------------- ...
- mysql多表查询及其 group by 组内排序
//多表查询:得到最新的数据后再执行多表查询 SELECT *FROM `students` `st` RIGHT JOIN( //先按时间排序查询,然后分组(GROUP BY ) SELECT * ...
- MySQL Group Replication 技术点
mysql group replication,组复制,提供了多写(multi-master update)的特性,增强了原有的mysql的高可用架构.mysql group replication基 ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
- Mysql Group Replication 简介及单主模式组复制配置【转】
一 Mysql Group Replication简介 Mysql Group Replication(MGR)是一个全新的高可用和高扩张的MySQL集群服务. 高一致性,基于原生复制及p ...
- MySQL学习笔记:三种组内排序方法
由于MySQ没有提供像Oracle的dense_rank()或者row_number() over(partition by)等函数,来实现组内排序,想实现这个功能,还是得自己想想办法,最终通过创建行 ...
- SQL实现group by 分组后组内排序
在一个月黑风高的夜晚,自己无聊学习的SQL的时候,练习,突发奇想的想实现一个功能查询,一张成绩表有如下字段,班级ID,英语成绩,数据成绩,语文成绩如下图 实现 查询出 每个班级英语成绩最高的前两名的记 ...
随机推荐
- linux显示完整目录
vim ~/.bashrc ##添加以下信息 export PS1='[\u@\h `pwd`]$ ' 然后保存退出 source ~/.bashrc 或者关机重新启动即可
- nginx 配置白名单
在http 模块 增加 geo $remote_addr $ip_whitelist{ default 0; include white_ip.conf; } 在location 模块 增加 (注意i ...
- re_test
https://www.cnblogs.com/zhaof/p/6925674.html#4152933 https://www.cnblogs.com/lanyinhao/p/9165747.htm ...
- Confluence 6 PostgreSQL 设置准备
请查看 Supported Platforms 页面来获得 Confluence 系统支持的 PostgreSQL 数据库版本.你需要在安装 Confluence 之前升级你的 PostgreSQL ...
- vue install后出现的问题
出现这个问题你要先把node-sass移除后重新安装 执行下面命令 npm remove node-sass --save-dev 然后安装 npm install node-sass@latest ...
- linux下安装nginx及初步认识
linux下安装配置nginx nginx:是一个高性能的反向代理服务器正向代理代理的是客户端,反向代理代理的是服务端. 这里以nginx-1.12.2版本为例子 1.首先去官网下载nginx-1.1 ...
- LeetCode(91):解码方法
Medium! 题目描述: 一条包含字母 A-Z 的消息通过以下方式进行了编码: 'A' -> 1 'B' -> 2 ... 'Z' -> 26 给定一个只包含数字的非空字符串,请计 ...
- 刷《剑指offer》笔记
本文是刷<剑指offer>代码中的学习笔记,学习ing.. 衡量时间和空间. 递归的代码较为简洁,但性能不如基于循环的实现方法.
- Winhex数据恢复学习笔记(四)
睡不着,那就深夜写篇笔记打发一下不瞌睡,❥(^_-) 1.winhex在文件批量处理上主要是针对批量保存.打开.关闭,主要还是基于批量打开的其他一些操作,这里通过构造通配符来批量打开,列如 *符号 ? ...
- cf1144G 将串分解成单调递增和递减子串(贪心)
这算哪门子dp.. 具体做法就是贪心,建立两个vector存递增序列递减序列,操作过程中a可以合法地匀一个给b 就是判断第i个数放在递增序列里还是放在递减序列里,需要根据后面的数来进行决策 #incl ...