mysql 不同版本下 group by 组内排序的差异
建表语句:



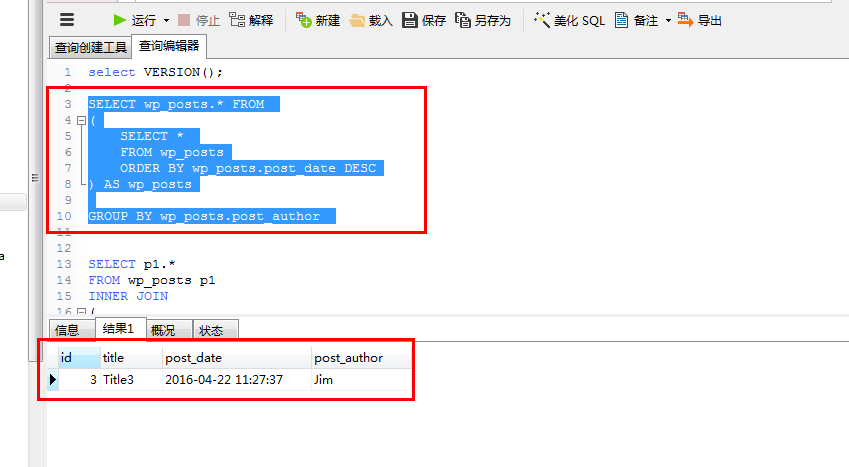
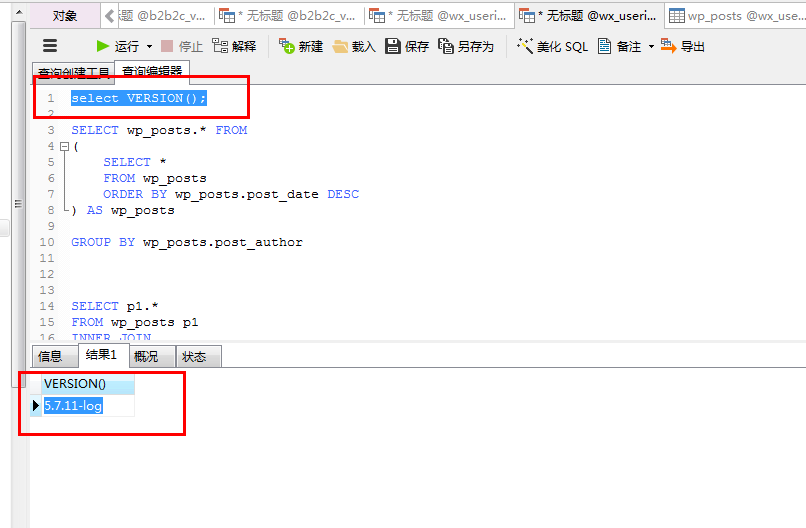




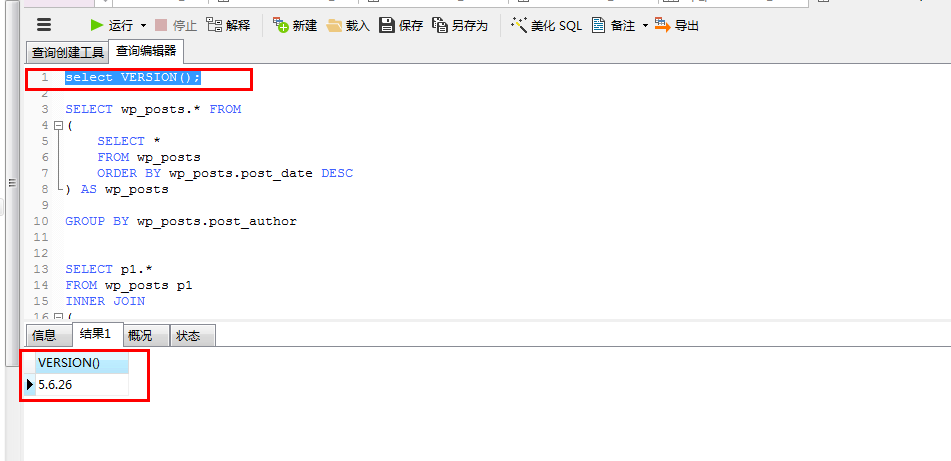



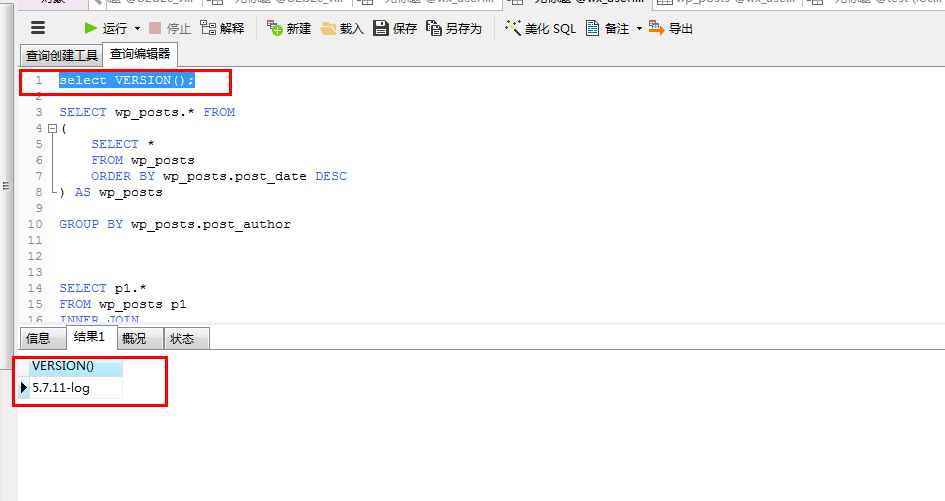


在版本5.6.26和版本5.7.11-log中结果是一样的(其他版本我没试过)。
mysql 不同版本下 group by 组内排序的差异的更多相关文章
- mysql group by组内排序
mysql group by组内排序: 首先是组外排序: SELECT z.create_time,z.invoice_id from qf_invoice_log z where z ...
- mysql group by 组内排序 group by 原理
mysql group by 组内排序 SELECT * FROM (SELECT MAX(id) AS t,wukong_uid, 1 AS tag FROM toutiao_uid_gath ...
- MySQL学习笔记:三种组内排序方法
由于MySQ没有提供像Oracle的dense_rank()或者row_number() over(partition by)等函数,来实现组内排序,想实现这个功能,还是得自己想想办法,最终通过创建行 ...
- mysql多表查询及其 group by 组内排序
//多表查询:得到最新的数据后再执行多表查询 SELECT *FROM `students` `st` RIGHT JOIN( //先按时间排序查询,然后分组(GROUP BY ) SELECT * ...
- mysql group by 组内排序
有数据表 comments------------------------------------------------| id | newsID | comment | theTime |---- ...
- mysql5.7.10和mysql5.5.39两个版本对于group by函数的处理差异
原理还是没有搞清楚,在官网上看了一下,看的不是很清楚.一并都记录一下. 问题描述: 存在如下数据结构 sql: 求用户最近更新的那条记录 思路: 按照modify_time排序后按照user_id分组 ...
- Groovy在不同JDK版本下的性能差异
Groovy作为一种动态语言,性能和JAVA比肯定是差不少,根据网友的测试,由于测试环境,场景和编译参数的不同,大概有差2到7倍的差距 那么同样的Groovy,在不同的JDK版本下,会有着怎样的差异呢 ...
- MySQL 5.7.17 Group Relication(组复制)搭建手册【转】
本博文介绍了Group Replication的两种工作模式的架构.并详细介绍了Single-Master Mode的部署过程,以及如何切换到Multi-Master Mode.当然,文末给出了Gro ...
- mysql在linux下的安装(5.7版本以后)
1.添加mysql组和mysql用户,用于设置mysql安装目录文件所有者和所属组. ①groupadd mysql ②useradd -r -g mysql mysql 2.将二进制文件解压到指定的 ...
随机推荐
- Http请求的响应没有Content-Length,只有Transfer-Encoding→chunked
如题:Http请求的响应没有Content-Length,只有Transfer-Encoding→chunked.如图 原因猜测:如果请求的响应返回是某个对象,则不会显示Content-Length, ...
- vue 左右滑动效果
个人实际开发中用到的效果问题总结出来便于自己以后开发查看调用,如果也适用其他人请随意拿走勿喷就行! vue.js是现在流行的js框架之一,vue 是一套用于构建用户界面的渐进式javascript框架 ...
- Appium+python自动化(十一)- 元素定位秘籍助你打通任督二脉 - 下卷(超详解)
简介 宏哥看你骨骼惊奇,印堂发亮,必是练武之奇才! 按照上一篇的节目预告,这一篇还是继续由宏哥给小伙伴们分享元素定位,是不是按照上一篇的秘籍修炼,是不是感觉到头顶盖好像被掀开,内气从头上冒出去,顿时觉 ...
- 系统学习 Java IO (十四)----字符读写缓存和回退 BufferedReader/BufferedWriter & PushbackReader
目录:系统学习 Java IO---- 目录,概览 BufferedReader BufferedReader 类构造器接收一个 Reader 对象,为 Reader 实例提供缓冲. 缓冲可以加快 I ...
- 【转载】java8中的Calendar日期对象(LocalDateTime)
Java 8 推出了全新的日期时间API,Java 8 下的 java.time包下的所有类都是不可变类型而且线程安全. 下面是新版API中java.time包里的一些关键类: Instant:瞬时实 ...
- 【Zookeeper01】ubuntu下安装zookeeper单例以及集群
参考链接:http://zookeeper.apache.org/ https://www.cnblogs.com/lyhc/p/6560993.html 系统: 乌班图16.04 虚拟机(zk一般要 ...
- 100天搞定机器学习|Day1数据预处理
数据预处理是机器学习中最基础也最麻烦的一部分内容 在我们把精力扑倒各种算法的推导之前,最应该做的就是把数据预处理先搞定 在之后的每个算法实现和案例练手过程中,这一步都必不可少 同学们也不要嫌麻烦,动起 ...
- IO解惑:cephfs、libaio与io瓶颈
最近笔者在对kernel cephfs客户端进行fio direct随机大io读测试时发现,在numjobs不变的情况下,使用libaio作为ioengine,无论怎么调节iodepth,测试结果都变 ...
- 用kubeadm创建高可用kubernetes集群后,如何重新添加控制平面
集群信息 集群版本:1.13.1 3个控制平面,2个worker节点 k8s-001:10.0.3.4 k8s-002:10.0.3.5 k8s-003:10.0.3.6 k8s-004:10.0.3 ...
- WebGL2系列之多采样渲染缓冲对象
在很久很久以前,盘古开辟了天地,他的头顶着天,脚踩着地,最后他挂了.他的毛发变成了森林,他的血液变成了河流,他的肌肉变成了大地......卡! 哦,不对,在很久很久以前,你属于我,我拥有你.你还有没有 ...